計算機的未來是幼兒的思維 - 彭博社
Jack Clark
機器包含了人類知識的廣度,但它們的常識卻像新生兒一樣。問題在於,計算機的行為並不像幼兒。Facebook人工智能研究主任Yann LeCun通過在桌子上豎起一支筆,然後在它面前舉起手機來展示這一點。他進行了一次手法表演,當他拿起手機時——哇!筆不見了。這是一個能讓任何一歲小孩驚歎的把戲,但今天最前沿的人工智能軟件——以及大多數幾個月大的嬰兒——無法理解這個消失的把戲並不正常。“在他們幾個月大之前,你對他們玩這個把戲,他們根本不在乎,”54歲的LeCun説,他是三個孩子的父親。“幾個月後,他們就會明白這並不正常。”
喜歡計算機的一個原因是,與許多孩子不同,它們會按照指示行事。計算機能夠做的幾乎所有事情都是由人類放置的,它們很少能夠發現新技術或自主學習。相反,計算機依賴於軟件程序員創建的場景:如果發生這種情況,就做那件事。除非明確告訴計算機筆不應該憑空消失,否則它就會照做。在追求思維機器的過程中,缺失的一個重要部分是給計算機提供一種像我們大腦中灰色物質一樣工作的記憶。擁有類似大腦記憶的人工智能將能夠辨別它所看到的亮點,並利用這些信息隨着時間的推移來塑造對事物的理解。為此,世界頂尖研究人員正在重新思考機器如何存儲信息,並正在向神經科學尋求靈感。
這種思維方式的變化促使了科技公司之間的人工智能軍備競賽,例如Facebook、Google和中國的百度。他們正在花費數十億美元來創造可能有一天具備常識的機器,並幫助創建更自然地響應用户請求的軟件,減少對用户的指導。理論上,生物記憶的仿製品應該讓人工智能不僅能夠識別世界中的模式,還能用我們與幼兒相關聯的邏輯進行推理。他們通過將模仿大腦的神經網絡與存儲更長信息序列的能力相結合來實現這一點,這種能力受到我們大腦中稱為海馬體的長期記憶成分的啓發。這種組合使得對世界的隱性理解能夠“融入”計算機從時刻到時刻檢測到的模式中,Facebook的人工智能研究員傑森·韋斯頓表示。6月9日,Facebook計劃發佈一篇 研究論文,詳細介紹一個可以處理數百萬條數據、記住關鍵點並回答覆雜問題的系統。這樣的系統可能讓人們有一天可以要求Facebook找到自己在朋友生日派對上穿粉色衣服的照片,或者詢問更廣泛、更模糊的問題,比如他們去年是否看起來比平時更快樂,或者似乎與朋友們花了更多時間。
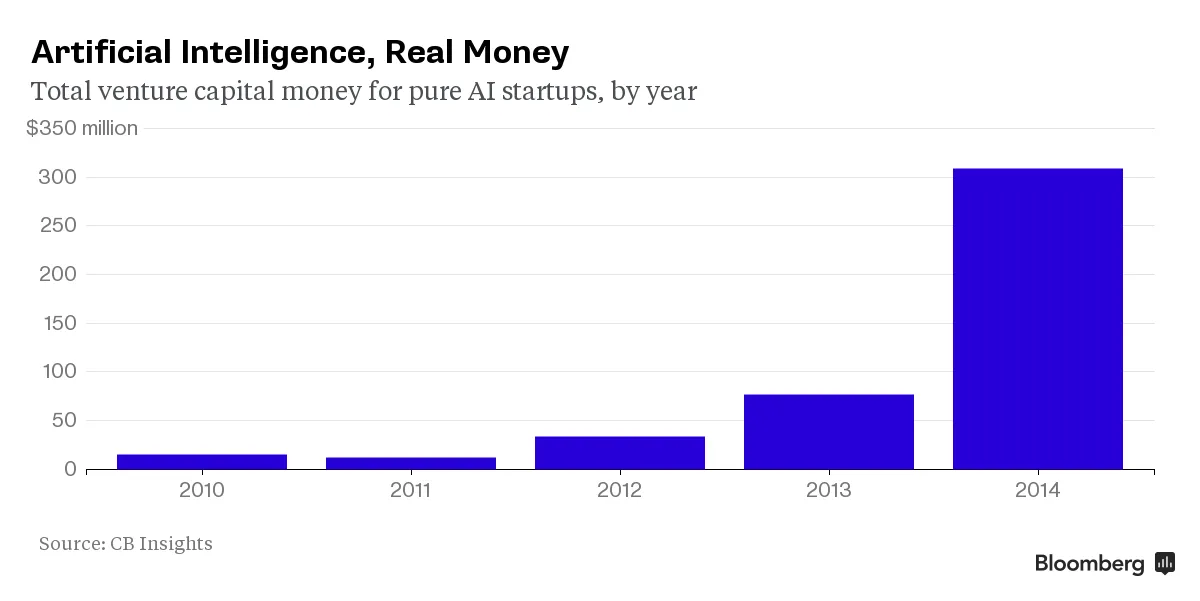
雖然人工智能長期以來一直是好萊塢和小説家的興趣領域,但公司們直到大約五年前才開始關注它。那時,研究機構和學者們藉助新的數據處理技術,以意想不到的速度打破了語音識別和圖像分析的記錄。風險投資家 注意到了這一點,並根據研究公司CB Insights的數據,去年對人工智能初創公司的投資達到了3.092億美元,是2010年的二十倍。其中一些初創公司正在幫助開闢新天地。硅谷的一家名為MetaMind的公司開發了改善計算機理解日常語音的技術。位於紐約的人工智能初創公司Clarifai正在進行復雜的視頻分析,並將該服務出售給企業。
 企業研究實驗室現在在人員和資金方面與學術界相媲美。它們在獲取專有數據和計算能力以進行實驗方面已經超過了學術界。這吸引了一些該領域最傑出的研究人員。前紐約大學數據科學中心主任LeCun於2013年12月加入Facebook,負責其人工智能團隊。在每週仍在紐約大學授課的同時,他已經招聘了近50名研究人員;6月2日,Facebook表示將在巴黎開設一個人工智能實驗室,這是其第三個此類設施。谷歌表示其人工智能團隊人數在“數百”之內,但拒絕提供更具體的信息。百度的硅谷人工智能實驗室於2014年5月開業,目前有約25名研究人員,由前谷歌人工智能負責人Andrew Ng領導。這家中國搜索巨頭在全球僱傭了約200名人工智能專家。來自資金雄厚的消費互聯網公司的興趣啓動了一場研究熱潮,創造了“幾十年來最大的進展之一”,加州大學伯克利分校紅木理論神經科學中心主任Bruno Olshausen表示。“這些實驗室的研究工作在研究的新穎性和開創性方面是前所未有的。”
企業研究實驗室現在在人員和資金方面與學術界相媲美。它們在獲取專有數據和計算能力以進行實驗方面已經超過了學術界。這吸引了一些該領域最傑出的研究人員。前紐約大學數據科學中心主任LeCun於2013年12月加入Facebook,負責其人工智能團隊。在每週仍在紐約大學授課的同時,他已經招聘了近50名研究人員;6月2日,Facebook表示將在巴黎開設一個人工智能實驗室,這是其第三個此類設施。谷歌表示其人工智能團隊人數在“數百”之內,但拒絕提供更具體的信息。百度的硅谷人工智能實驗室於2014年5月開業,目前有約25名研究人員,由前谷歌人工智能負責人Andrew Ng領導。這家中國搜索巨頭在全球僱傭了約200名人工智能專家。來自資金雄厚的消費互聯網公司的興趣啓動了一場研究熱潮,創造了“幾十年來最大的進展之一”,加州大學伯克利分校紅木理論神經科學中心主任Bruno Olshausen表示。“這些實驗室的研究工作在研究的新穎性和開創性方面是前所未有的。”
儘管科技資金在近年來推動了人工智能的發展,但計算機仍然相當愚蠢。當你在嘈雜的酒吧與朋友交談時,你會根據上下文和你對他們興趣的記憶來理解他們在説什麼,即使你聽不清每一個字。計算機無法做到這一點。“記憶是認知的核心,”Olshausen説。人類大腦並不會記錄每一天事件的完整日誌;它會彙總並在相關時突出重點,他説。或者至少,科學家們是這麼認為的。試圖按照我們的形象創造人工智能的問題在於,我們並不完全理解我們的思維是如何運作的。“從神經科學的角度來看,我們對大腦的理解以及構建智能系統所需的條件,處於一種前牛頓的狀態,”Olshausen説。“如果你在物理學中處於前牛頓時代,你甚至離建造火箭都還遠得很。”
現代人工智能系統使用一種稱為神經網絡的系統來分析圖像、轉錄文本和翻譯語言,這種系統受到大腦新皮層的啓發。在過去的一年裏,幾乎整個人工智能社區都開始轉向一種新的方法來解決難以破解的問題:為神經元的混亂添加一個記憶組件。每家公司使用不同的技術來實現這一點,但它們在記憶方面有着相同的重視。這一變化的速度讓一些專家感到驚訝。“就在幾個月前,我們認為我們是唯一在做類似事情的人,”西頓説,他是去年秋天Facebook首篇關於基於記憶的人工智能的主要期刊文章的共同作者。幾天後,谷歌DeepMind的研究人員也發表了一篇類似的論文。
 自那時以來,配備了一種短期記憶的人工智能幫助谷歌在視頻和圖像分析方面創下了記錄,並創造了一種可以在沒有説明的情況下 玩視頻遊戲 的機器。(它們與孩子們有更多的共同點,可能比你想象的要多。)百度在圖像和語音識別方面也取得了顯著進展,包括 回答關於圖像的問題,例如,“手的中心是什麼?”IBM表示其Watson系統可以以令人印象深刻的8%的錯誤率解讀對話。隨着Facebook在基於記憶的人工智能軟件上的持續工作,該軟件可以閲讀文章並智能地回答有關其內容的問題,社交網絡巨頭旨在創造“一個可以與你對話的計算機,”西頓説。下一步是創建一個更類似於長期記憶的伴隨框架,這可能導致能夠推理的機器,他解釋道。
自那時以來,配備了一種短期記憶的人工智能幫助谷歌在視頻和圖像分析方面創下了記錄,並創造了一種可以在沒有説明的情況下 玩視頻遊戲 的機器。(它們與孩子們有更多的共同點,可能比你想象的要多。)百度在圖像和語音識別方面也取得了顯著進展,包括 回答關於圖像的問題,例如,“手的中心是什麼?”IBM表示其Watson系統可以以令人印象深刻的8%的錯誤率解讀對話。隨着Facebook在基於記憶的人工智能軟件上的持續工作,該軟件可以閲讀文章並智能地回答有關其內容的問題,社交網絡巨頭旨在創造“一個可以與你對話的計算機,”西頓説。下一步是創建一個更類似於長期記憶的伴隨框架,這可能導致能夠推理的機器,他解釋道。
如果一個會説話、學習、思考的機器讓你感到有些恐懼,你並不孤單。“通過人工智能,我們正在召喚惡魔,”埃隆·馬斯克去年説。特斯拉汽車的首席執行官有一個團隊在研究人工智能,以讓其電動汽車實現自動駕駛。馬斯克還是一家名為Vicarious的人工智能初創公司的投資者。在經過一些顯而易見的自我反思後,馬斯克捐贈了1000萬美元給未來生命研究所,這是由麻省理工學院教授馬克斯·泰格馬克和他的妻子梅婭設立的一個組織,旨在促進關於人工智能相關可能性和風險的討論。該組織彙集了世界頂尖的學者、研究人員以及經濟學、法律、倫理和人工智能領域的專家,討論如何開發出更像傑森一家而不是終結者的聰明計算機。“除了少數幾個小型非營利機構,幾乎沒有認真研究這些問題。幸運的是,這種情況現在正在改變,”斯蒂芬·霍金在5月的一個谷歌活動上説,他在該研究所的顧問委員會任職。“風險評估的健康文化和對社會影響的意識正在人工智能社區紮根。”
來自競爭公司的人工智能團隊正在合作推進研究,目的是以負責任的方式進行。這個領域仍然以一種讓人想起半導體行業早期的學術熱情運作——分享想法、合作實驗和發表同行評審的論文。谷歌和臉書正在開發專注於基於記憶的人工智能的平行研究計劃,並將他們的論文發佈到免費的學術存儲庫。谷歌的尖端神經圖靈機“可以在沒有指導的情況下學習非常複雜的程序”,並且可以相當好地操作它們,谷歌研究主任彼得·諾維格在三月的一次演講中説。就像一個在Excel中掙扎的辦公室職員,這台機器偶爾會犯錯。而這沒關係,諾維格説。“這就像一隻用後腿走路的狗。你能做到嗎?這就是令人興奮的地方。”
“這就像一隻用後腿走路的狗”
企業人工智能實驗室的技術進步已經開始迴流到大學。 斯坦福大學和其他學校的學生們構建了谷歌人工智能系統的版本,並將源代碼在線發佈,供任何人使用或修改。Facebook也在學術界引起了類似的興趣。韋斯頓在5月11日於斯坦福大學為超過70名到場學生(還有更多在線收看)進行了關於Facebook記憶網絡項目的講座。Facebook人工智能負責人勒昆表示:“我們認為自己並沒有對好主意擁有壟斷權。”勒昆與谷歌的傑夫·辛頓和蒙特利爾大學的約書亞·本吉奧共同撰寫了一篇於5月28日發表在科學期刊自然上的論文,指出記憶系統是賦予計算機根據時間變化調整理解能力的關鍵。
為了説明人們如何利用記憶來應對事件,勒昆拿起他之前的魔法筆,朝一位同事扔去。沒有記憶或時間理解的機器不知道如何預測物體將落在哪裏或如何對其做出反應。另一方面,人們利用記憶和常識幾乎本能地抓住或躲避即將到來的東西。Facebook人工智能研究員韋斯頓看着筆在空中劃出弧線,然後擊中了他的手臂。“他抓東西的能力很差,”勒昆笑着説,“但他能預測!”韋斯頓安慰他説:“我知道它會擊中我。”