最強“新狗”AlphaGo Zero發佈 柯潔:對於它的自我進步來講,人類太多餘
北京時間今天(10月19日)凌晨,谷歌旗下的DeepMind團隊公佈了進化後的最強版AlphaGo ,代號AlphaGo Zero。AlphaGo曾打敗了中國頂尖棋手柯潔,而AlphaGo Zero經過3天的訓練,就以100:0的比分完勝AlphaGo。這條消息點燃了中國圍棋界,連柯潔也發微博感嘆:對於AlphaGo的自我進步來講,人類太多餘了……
**谷歌今天發佈的這款名為AlphaGo Zero有多厲害?**據“快科技”網站文章的介紹,它的系統可以通過自我對弈進行學習,它利用了一種名為強化學習的技術。在不斷訓練的過程中,這套系統開始靠自己的能力學會圍棋中的一些高級概念。
經過3天的訓練後,這套系統已經可以擊敗AlphaGo Lee,也就是去年擊敗韓國頂尖棋手李世石的那套系統,而且比分高達100比0。經過40天訓練後,它總計運行了大約2900萬次自我對弈,使得AlphaGo Zero得以擊敗AlphaGo Master(今年早些時候擊敗世界冠軍柯潔的系統),比分為89比11。

AlphaGo之父戴密斯·哈薩比斯(Demis Hassabis)
與學習大量人類棋譜起步的前代AlphaGo不同,AlphaGo Zero是從“嬰兒般的白紙”開始,通過3天數百萬盤自我對弈,走完了人類千年的圍棋歷史,並探索出了不少橫空出世的招法。
值得注意的是,雖然AlphaGo Zero在幾周的訓練期間學會了一些關鍵概念,但該系統學習的方法與人類有所不同。另外,AlphaGo Zero也比前幾代系統更加節能,AlphaGo Lee需要使用幾台機器和48個谷歌TPU機器學習加速芯片。其上一代AlphaGo Fan則要用到176個GPU芯片。AlphaGo Zero只需要使用一台配有4個TPU的機器即可。
DeepMind團隊創始人David Silver介紹AlphaGo Zero説,這款程序超越了過去所有的AlphaGo版本,目前是世界上最大強大的圍棋程序。

(視頻截圖,下同)
它的學習不使用人類數據,而是自我學習,完全從零開始。之所以它能比向人類數據學習的程序效果更好,是因為它每次對弈的“陪練”都被校準為與它持平的水平,它的“陪練”從非常基礎的水平開始,逐漸上升為非常高的水平。

David Silver還説,人們一般認為機器學習就是大數據和海量計算,但是他們在AlphaGo Zero的研究中發現,算法比所謂計算或數據可用性更重要。

以下是完整視頻:
DeepMind聯合創始人和總裁David Silver介紹新版阿法狗。 (視頻自騰訊)
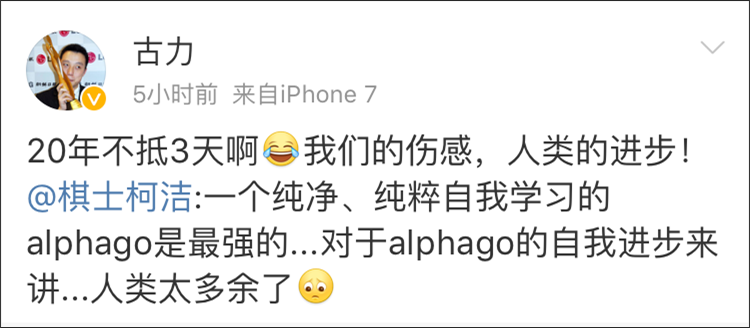
這篇論文發出的消息迅速點燃了圍棋界。曾和“阿法狗”交過手的中國棋手柯潔在微博感嘆:“一個純淨、純粹自我學習的alphago是最強的……對於alphago的自我進步來講……人類太多餘了……”
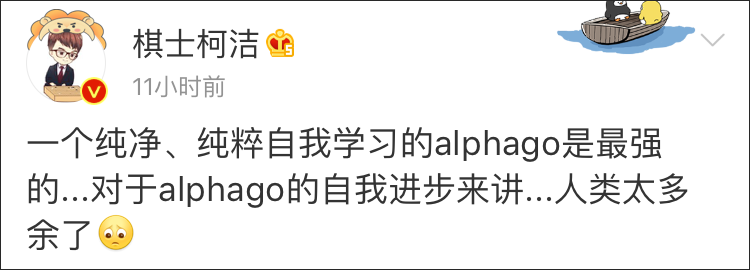
(截圖自微博)
今年五月,輸給阿法狗的的柯潔曾在賽後一度哽咽,稱:“它太完美,我很痛苦,看不到任何勝利的希望。”在賽後的發佈會上,柯潔説,“很感謝AlphaGo,我居然能有這麼大差距,希望我能再努力,讓差距更小一點。AlphaGo實在太完美,以後差距只能越來越大,我只能説對自己的表現感覺很遺憾,為DeepMind團隊感到開心,AlphaGo棋手能表現這麼完美,真是了不起。”

今年五月,柯潔對陣“阿法狗”。 (視頻截圖)
棋手古力也轉發了這條微博,説:“20年不抵3天啊!我們的傷感,人類的進步!”
“AlphaGo Zero”的發佈再起引起網友對人工智能的熱烈討論,人工智能對人類的超越讓人既驚喜又擔憂。 在網友看來,機器雖然在比賽上勝過了人類,卻無法取代贏得人類的情感,尤其對於廣大圍棋迷來説,“阿法狗”並不能替代他們心中的棋手。