陳經:Deepmind這次搞定國際象棋,只用了四個小時
【文/ 觀察者網專欄作者 陳經】
2017年12月6號,Deepmind扔出了一篇論文《Mastering Chess and Shogi by Self-Play with a General Reinenforcement Learning Algorithm》,聲稱從AlphaGo Zero發展來的新程序AlphaZero又零基礎自學,只用4個小時和2個小時就勝過了國際象棋和日本將棋的最強程序。加上之前在圍棋上的進展,這其實等於是説,世界上所有知名棋類都可以用一個架構輕鬆碾壓過去的高手,不管是人還是程序。
這篇文章正在被審核,按Deepmind過去的風格有可能還是投到《自然》去。但這回Deepmind不保密了,直接在arxiv.org公佈了全文。前兩篇圍棋AI的文章由於投出來之後有人機大戰,是需要保密。
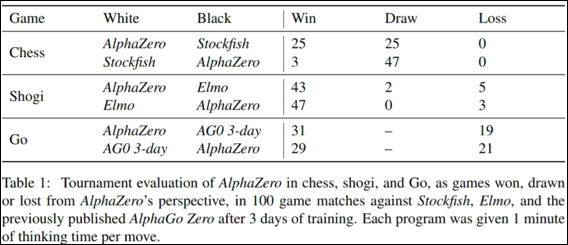
這篇文章在圍棋上,用訓練34小時的AlphaZero和訓練72小時的AlphaGo Zero相比,100盤60:40。這個結果並不令人吃驚,就是訓練速度快了,説明新的方法有提升,其實網絡架構訓練方法和AlphaGo Zero的差不太多,是一些小改進。圍棋界對這篇文章應該反應不大,新東西不多,早就被震驚好幾次了。
AlphaZero在日本將棋上訓練2小時就超過最強程序Elmo。日本將棋和中國象棋、國際象棋差不多,也是各兵種吃對方的王。但是最大的不同是吃掉對方的棋子可以變成本方的棋子,放回棋盤任意位置,這使得對局攻殺極為激烈,和局很少,變化比國際象棋要多不少。中國象棋的理論局面數量超過國際象棋,但由於大量局面類似,高手們一般認為實際變化複雜程度比國象要少。
由於日本將棋更為複雜(以及研究人員關注的少),直到2017年冠軍程序Elmo才戰勝了人類高手。這個Elmo應該實力還比較弱,所以最終被AlphaZero以90勝2和8負戰勝了。AlphaZero還會輸幾局,但這是因為訓練時間不長,已經能夠説明問題就行了。
真正影響重大的是國際象棋。這次倒不是説AlphaZero怎麼碾壓了人,人類高手早就被國際象棋AI整得服氣了。但是AlphaZero訓練4小時就反超了,最終以28勝72和戰勝了Stockfish(鱈魚),其中先行戰績是25勝25和。這個Stockfish在國際象棋界可不是隨便搞搞研發的程序,也不僅是2016年國象AI冠軍這麼簡單,它對職業棋手和愛好者們就像是親人朋友一樣,天天在為棋界服務。在chessbomb等網站上,職業棋賽每一步Stockfish都在實時地給出各種變化,愛好者們看棋的方式和以前完全不一樣了。高手們訓練也非常依賴頂級AI給出的各種提示,有時就像終極答案一樣。高手們通過親身感受,對於Stockfish的實力非常認可。
由於國際象棋最優解極有可能是和棋,所以高手和愛好者一般認為,Stockfish和國際象棋上帝也差不了太多,反正就是和棋。以前兩個頂級AI對打(通常是大戰100盤),總有90%的是和棋。排名世界前五的美國特級大師中村光就説:就算是上帝先手和Stockfish下,也得75%是和棋。
現在AlphaZero忽然跑出來,先行能以50%的概率戰勝Stockfish,這讓一些國際象棋高手和愛好者們有些難以接受。我對圍棋很熟,AlphaGo對圍棋界的衝擊可以説是天翻地覆無以倫比。現在輪到國際象棋界來感受新型AI的衝擊了,看着一些國外愛好者對AlphaZero的討論,各種置疑或者不接受,不由得一陣暗爽。
Stockfish和AlphaZero都是機器,不管誰強誰弱,和人都沒啥關係,為什麼國際象棋界的人要着急?這裏有一些算法背景。

(圖片來源:chessbase)
上圖對弈者為國際象棋排名前兩位的卡爾森與卡魯亞納,圍觀者左為卡斯帕羅夫,右為哈薩比斯。哈薩比斯本人是國際象棋職業選手,青少年時排名僅次於天才少女小波爾加,他的“一個框架解決一切棋類問題”的思想這次實現了。
Stockfish是機器,但是裏面的算法是人們一步步看着發展過來的,程序員寫了很多代碼,每年都在不斷升級,還有國際象棋大師出主意。棋界和計算機學界一起努力,才達到了非常高的水平,那一行行代碼都開源在那,還有規模極大的開局庫、殘局庫放在那幫着簡化搜索。這都是業界的心血,那些精巧的alpha-beta搜索、剪枝算法、高效實現,各種知識庫,有多少人的聰明才智在裏面。業界其實對以Stockfish為代表的國際象棋AI比較滿意,開發出來的程序又幫助棋手們漲棋,促進了國際象棋界的繁榮,職業棋手數量和水平都大大增加。
各種AI們自己在那對戰,Stockfish前幾天就正在和Komodo大戰。但棋迷和高手們主要還是對人類對局有興趣。這個局面是不錯的,AI們自己玩,玩出東西來幫助人漲棋以及評化棋局,人不和AI較勁。
但是現在AlphaZero等於是説,人類之前開發AI的所謂“心血”都是沒意義的白忙活。弄好一個resnet神經網絡結構,把國際象棋基本規則做好了,來5000個一代TPU對局生成樣本,再來64個二代TPU訓練,過4小時就行了。
人類大師1000多年發掘的象棋精妙知識不需要,算法大師構造的精妙剪枝搜索不需要,也不要任何開局庫殘局庫。就這麼一個結構,還同時可以搞定圍棋、日本將棋、國際象棋,區別只是訓練出來的神經網絡係數不同。
這種機器暴力征服,圍棋AI界的人還是比較服氣和欣賞的,説算法優美簡單。可能是因為以前開發圍棋AI的人也沒寫出什麼好的搜索算法,各種搜索代碼寫得心煩意亂,明知一堆缺陷也勉強推出來被人類高手低手嘲笑。
老辦法搞不定圍棋,機器暴力搞定了,是很好的事。但國際象棋不一樣了,業界好不容易各種精巧的代碼折騰,精心添加維護開局庫殘局庫,感覺摸到國際象棋真理的邊了,忽然一下被機器暴力4小時否定了,難道過去的事真的是沒有意義的?
因此一些棋迷和高手質疑AlphaZero這個結果,對Stockfish更有感情,是可以理解的。一種質疑是,你AlphaZero背後財大氣粗,機器厲害,是不是讓Stockfish運行在弱機上,不公平啊?有棋迷就聲稱,我還能戰勝初代stockfish呢,Deepmind到底怎麼試的?為什麼每步只讓Stockfish思考一分鐘?但是按論文的數據,測試的Stockfish有64個線程,每秒能搜索7000萬個局面,這機器並不弱。
另一種質疑就專業一些,如中村光説,Stockfish並不是一個簡單的程序,需要配上合適的開局庫殘局庫。Deepmind是不是配錯了開局庫,讓Stockfish沒有發揮最佳實力?怪不得AlphaZero先行能25勝,Stockfish沒有好的開局庫吃這麼大虧才輸成這樣的。這種質疑比較專業,因為國際象棋開局變化要比中盤、後期複雜得多,AI也不可能搜索清楚。
業界的解決辦法是,搞一個龐大的開局庫,通過實戰對局或者測試中發現不對勁,就放到開局庫裏免得Stockfish掉到溝裏去。而且不同配置的機器對應的開局庫是不同的,強機能走的開局,弱機不一定抗得住。這個Deepmind論文裏説得是有些不清楚。
特級大師考夫曼是幫助Komodo開發的專家,對AI很瞭解,他也有類似意見。考夫曼認為,現在説“AlphaZero這種暴力訓練的引擎比基於min-max搜索的傳統算法強”還為時過早。AlphaZero這麼訓練,相當於自帶了最合適的開局庫,公平的比試應該讓Stockfish配上最合適的開局庫。

對國際象棋不熟的人可能會説,Stockfish這不是還不錯麼,AlphaZero等級分和它也差不多,而且好像高不上去了。等級分高不上去,主要是因為太多和棋弄的,等級分系統認為分差大獲勝概率就得很高,老和就説明你兩水平差不多。對人類高手確實如此,人類和stockfish下基本是輸,等級分差距很大。但是在極高的水平上,就不能看等級分了,要看輸棋。
有經驗的高手們認為,國際象棋特別容易和棋,正常走就是和棋,大比例的就應該和棋,就算走得稍不精確也能和,容錯犯圍比較大。只有説走多了,才偶爾掉進坑裏算不清楚輸掉。
卡斯帕羅夫和卡爾波夫爭霸時曾經連和26局,兩人都快折騰死了,卡爾波夫雖然勝局2:0領先,但是已經下崩潰了。
現在Stockfish在後走的50局裏輸掉一半,不太正常,掉坑概率過高,感覺像是開局庫吃大虧。下到中後盤,Stockfish那每秒7000萬步的搜索不是開玩笑的,如果有和棋的路線,不太可能輸。
一些國象高手們對Deepmind應用Stockfish細節的質疑,似乎也有道理。但不管怎麼説,就算Stockfish真是因為沒有好開局庫輸大了,它總得依賴好幾個G的寵大開局庫,而且還得不停更新維護達到高水平,這看上去不是正路。這等於是説,吃了虧,就把吃虧算不清的地方用開局庫補足。
這看上去很像騰訊的圍棋AI絕藝之前掙扎的開發階段,老是出死活bug,就去人工修,修來修去似乎是出錯概率小了,但總修不乾淨。棋下得也不太自然,解説人類對局的時候也經常給出不靠譜結論。後來騰訊參考AlphaGo Zero的新版本“符合預期”就很好了,行棋自然,不出死活Bug,對人類高手也是60連勝,還讓二子勝了絕藝。
符合預期這個版本2017年12月9日10日參加了在日本舉辦的龍星杯世界圍棋AI賽,預賽決賽兩次戰勝最強對手DeepZenGo奪冠。但是絕藝預賽中對一個弱程序Maru輸了一局,終局已經大勝了,但因為是用中國規則開發的,對日本規則沒有準備,對手不斷Pass,絕藝卻自填了很多目填輸了。比賽中多箇中韓程序都因為日本規則中招了,自填負、自填超時負、終局死機負,狀況不斷。
從開發思想看,其實很清楚。Stockfish等之前的“頂級”國際象棋AI,是用精確搜索的思想開發的,各種細節都做到極致,人工編寫的局面估值函數極盡精巧,算法剪枝操作研究極深,代碼量不小。如果搜索不行,就加開局庫、殘局庫補足弱點。這是傳統的人工代碼開發的思想,其實搜索本身是暴力傾向的,開發目標就是儘可能多搜增強實力,標誌性指標之一就是一秒能搜多少個局面。
而AlphaZero的開發思想特別簡單。人簡直是太輕鬆了,給出網絡結構,實現下棋規則,搞出強化學習方法,配上足夠的學習和訓練的機器就行了。一切都是機器自己學出來的,人沒有什麼事。而且學完後下棋,一些棋迷評論説AlphaZero下得混然天成,非常自然,人容易理解,沒有什麼開局庫的生搬硬套,一切都在神經網絡係數裏。Stockfish倒是下得像機器,有些招法不知道怎麼蹦出來的,人理解不了。
AlphaZero下國際象棋的時候,每秒只要搜索8萬個局面就夠了,個個變化圖都很有意義。這反過來説明Stockfish每秒7000萬個局面,雙方對局時一分鐘一步,那幾十億的局面絕大多數都沒啥意義浪費了,還有漏算。

國際象棋AI超級決賽(TCEC Season 10 SuperFinal ),第97場Komodo執白負於Houdini
從算法意義來説,AlphaZero下得更像人。AlphaZero是用MCTS來搜索的,不是精確的,有概率隨機因素,是隨機選擇一些高概率的分枝進行搜索,低概率的分枝根本不浪費算力去碰。之前人們評論説,這不象人,人不可能這麼下棋。這主要指的是MCTS用在圍棋上,有一個下完數子的rollout用來代替代碼寫不好的局面估值,這確實不象人。
但是AlphaGo Zero已經把rollout取消了,直接用深度神經網絡來進行估值。這樣AlphaZero下棋其實更像人的思路,找直覺最想下的點往下推,再找其它也看着靠譜的點也試試。只不過AlphaZero比起人來還是特別能算,一秒能算8萬個局面(人類高手每步一般考慮10個局面)。但是與Stockfish相比,AlphaZero這還是人的思考方式,Stockfish等於在那一秒7000萬個局面瘋狂分枝擴展,各種不靠譜的分枝佔據了大量算力,真正有效的搜索沒有太多,藉着機器的暴力才搞定了人。
這就是機器學習算法界之前爭議的,博弈算法“MCTS+神經網絡”是更先進的框架。之前Deepmind有人簡單地把“MCTS+神經網絡”用在國際象棋上,只是大師的水平,達不到頂級AI的水平。有不少人認為,也許“MCTS+神經網絡”這個套路只是對圍棋這種簡單規則的管用。國際象棋規則複雜,MCTS不夠“精確”,還是人類程序員精心編制的確定性算法更管用。這次Deepmind新論文應該給出結論了,“MCTS+神經網絡”就是先進生產力的代表。
哈薩比斯評論説,AlphaZero下國際象棋的時候,最革命性的一點是,它沒有棋子的概念。在AlphaZero看來,只有整體局勢才是它關心的,這相當於國際象棋理論對“position”的重視。但無論是人類高手還是過於的頂級AI,再怎麼也是以棋子實力評估為基礎的,被吃了大子會心疼,在這個基礎上再去進行“重視中央”之類的局面評估理論。
而AlphaZero卻完全對棋子沒有概念,只要它認為未來整體局勢好,棄子根本不叫事。所以哈薩比斯説,從棋藝理論來説,AlphaZero既不是人的下法,也不是機器的下法,它是自己創新了一個下法。
這次Deepmind公佈了AlphaZero對Stockfish的十局勝局棋譜,可以這個鏈接中動態查看。

從棋譜中看,AlphaZero很善於棄子。人類或者機器也棄子,但多半有明確目的,棄了子立刻能吃回或者做殺入局。但AlphaZero經常早早放棄子力,在多步以後才建立優勢,這個能力是令人震驚的。
如第十局AlphaZero執白對Stockfish,到36步這個局勢黑多兵,而且還多一個馬,粗看上去應該是黑大優。但實際上白棋進入了必勝局勢,黑為了救命,只能用車後換白的後,白方車對馬優勢很大可以把黑的兵掃光。而AlphaZero第18步就把馬棄了,這麼多步以後人們才明白它在幹什麼。
AlphaZero剛出來,國際象棋高手們還在接受中,但方向應該是明確的。機器學習代表了一大類問題的未來,人類精心設計的算法,不如機器暴力自學習。和之前的圍棋相比,這次的國際象棋和日本將棋進一步打開了想象力。也許以後,機器就自己學會編程了,因為編程其實就是實現一些明確的目標。
本文系觀察者網獨家稿件,文章內容純屬作者個人觀點,不代表平台觀點,未經授權,不得轉載,否則將追究法律責任。關注觀察者網微信guanchacn,每日閲讀趣味文章。