【壹周讀書】大數據時代_風聞
西竹先生-长安一片月,万户捣衣声2018-07-25 09:23
亮點摘錄
1. 世界的本質就是數據。
2. 大數據發展的核心動力來源於人類測量、記錄和分析世界的渴望。
3. 從因果關係到相關關係的思維變革才是大數據的關鍵,建立在相關關係分析法基礎上的預測才是大數據的核心。
4. 大數據提供的不是最終答案,只是參考答案。
5. 大數據的真實價值就像漂浮在海洋中的冰山,第一眼只能看到冰山的一角,絕大部分都隱藏在表面之下。而發掘數據價值,征服數據海洋的動力就是雲計算。
6. 大數據與雲計算是一個問題的兩面:一個是問題,一個是問題的方法。
7. “大數據”發展的障礙,在於數據的“流動性”和“可獲取性”。
8. 越是萬能的,就越是空間的。
9. 當我們改變規模時,事物的狀態有時也會發生改變。
10. 尋找因果關係是人類長久以來的習慣。即使確定因果關係很困難而且用處不大,人類還是習慣性地尋找緣由。
11. 相關關係也許不能準確地告訴我們某件事情為何會發生,但是它會提醒我們這件事正在發生。
12. 大數據告訴我們“是什麼”而不是“為什麼”。
13. 統計學的一個目的就是用盡可能少的信息來證實儘可能重大的發現。
14. 採樣分析的確定性隨着採樣隨機性的增加而大幅提高,但與樣本數量的增加關係不大。
15. 樣本選擇的隨機性比樣本數量更重要。
16. 採樣的目的就是用最少的數據得到最多的信息。
17. 大數據是指不用隨機抽樣這樣的捷徑,而採用所有數據的方法。
18. 執迷於精確性是信息缺乏的時代和模擬時代的產物。
19. 我們研究一個對象,是因為我們相信我們可以理解它。
20. 測量就是認知。
21. 混亂,簡單地説就是隨着數據的增加,錯誤率也會相應的增加。
22. 大數據的簡單算法比小數據的複雜算法更有效。
23. 大數據不僅讓我們不再期待精確性,也讓我們無法實現精確性。
24. 錯誤性並不是大數據本身固有的。它只是我們用來測量、記錄和交流數據的工具的一個缺陷。
25. 要想獲得大數據帶來的好處,混亂應該是一種標準途徑,而不應該是竭力避免。
26. 我們再也不能假裝活在一個齊整的世界裏。
27. 寬容錯誤會給我們帶來更多的價值。
28. 我們默認自己不能使用更多的數據,所以我們就不會去使用更多的數據。
29. 相關關係是無法預知未來的,他們只能預測可能發生的事情。
30. 一旦你知道了結果,一切都很容易。
31. 數據化是一種把現象轉變為可製表分析的量化形式的過程,數字化指的是把模擬數據轉換成用0和1表示的二進制碼。
32. 資產=負債+所有者權益。
33. 預測給我們知識,而知識賦予我們智慧和洞見。
34. 本質上世界是由信息構成的。
35. 隨着大數據的出現,數據的中和比部分更有價值,當我們將多個數據集的總和重組在一起時,重組總和本身的價值比單個總和更大。
36. 面對懷疑,公開優先。
37. 他們思考的只有可能,而不考慮所謂的可行。
38. 一個似乎經過了理智討論的事情其實是在沒有什麼實際標準的情況下做出來的。
39. 知識退化成騷亂的主觀臆想,那是太陽神經叢的感情引起的營養不良。
40. 也許大數據預測可以為我們打造一個更安全,更高效的社會,但是卻否定了我們之所以偉人的重要部分——自由選擇的能力和行為負責。
41. 錯誤的前提導致錯誤的結論。
42. 變革並不至於規範。
43. 在大數據時代,關於公正的概念需要重新定義以維護個人動因的想法:人們選擇自我行為的自由意志。簡單地説,就是個人可以並應該為他的行為而非傾向負責。
44. 凡是過去,皆為序曲。
45. 有些歷史最悠久的做事方法並不是最好的。
46. 數據不可能是完全對的或完全錯的。當數據以規模級增加時,這些混亂也就算不上問題了。
47. “現代”的一個定義性特徵便是人們感到自己是命運的主人。
48. 潛在的可能性在概念的聖壇上被解剖。
49. 沒有什麼是上天註定的,因為我們所能就手中的信息制定出相應的策略。
50. 人類最偉大之處真實運算法和硅片沒有揭示也無法揭示的東西,因為數據也無法捕捉到這些。並不是“人類最偉大的東西是什麼”,而是“什麼不是人類最偉大的產物”——真空、人行道上的裂縫、未説出的話還是未想到的事。
51. 預測未來的最好方法就是創造未來。
對於大數據,有這幾種定義
Gartner Group的定義是:“大數據”是需要新處理模式才能具有更強的決策力、洞察發現力和流程優化能力的海量、高增長率和多樣化的信息資產。
維基百科的定義,大數據是指無法在可承受的時間範圍內用常規軟件工具進行捕捉、管理和處理的數據集合。(參見維基百科)
大概這本書的線索是這樣的
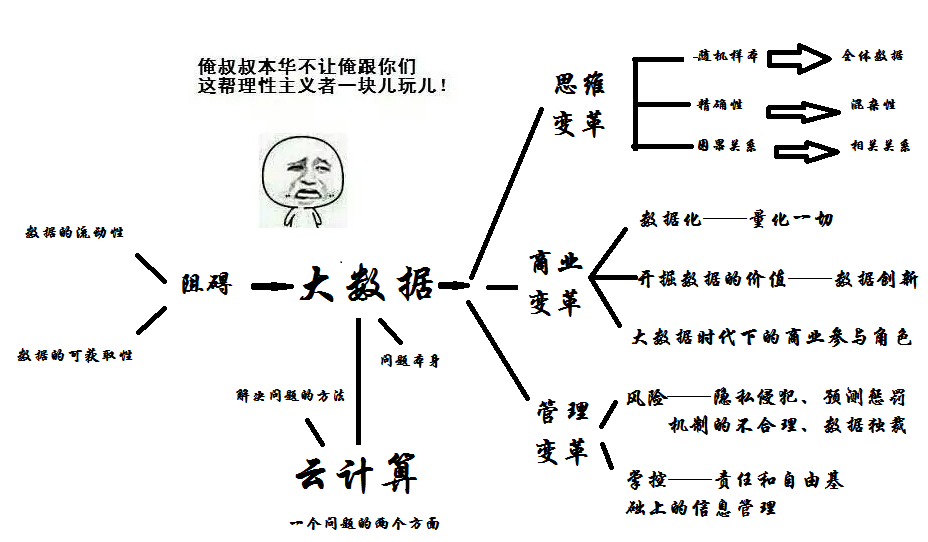
(字好小……)
大數據和雲計算的關係是這樣的
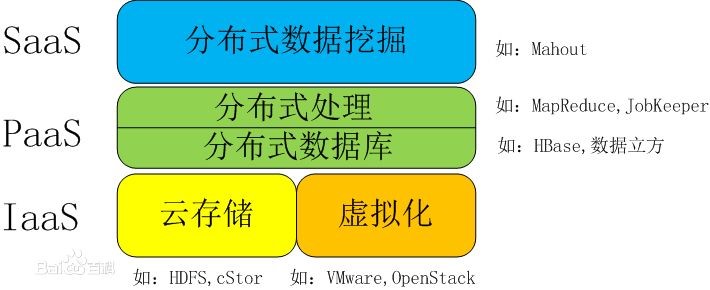
(字好大……)
在綜述部分,作者介紹了大數據帶來的生活、工作和思維變革:大數據對公共衞生的變革(以谷歌搜索與流感預測為例),大數據對商業的變革(Farecast票價預測軟件)、思維變革(大數據可以實現小規模數據無法處理和解決的事情,無論是市場,組織還是征服和公民關係)、大數據開啓的時代轉型(數據質量和數量的急劇擴張,已經新的數據計算和利用方式的湧現,人們的商業、科技、醫療、政府、教育、經濟、人文以及社會的其他領域發生的重大改變)。
預測是大數據的核心,把數學算法運用到海量的數據上來預測事情發生的可能性(如垃圾郵件的過濾)。計算機系統逐漸在改變甚至取代人類單憑判斷力的階段。
大數據帶來的思維變革,作者劃分為三大塊。
1. 從隨機樣本向全體樣本的過度。伴隨着數據處理技術的更新,樣本=總體得以可能,“抽查”到“普查”的可能性真正實現。大數據時代下,不再需用用隨機抽樣得到的“最多信息”來進行描述、分析和預測。這消弭了隨機抽樣的隨機性無法保證的死局。(在有些領域,甚至找不到一個最優抽樣方法),樣本=總體的全數據模式正在取代樣本分析。
2. 從信息的精確性到數據的混雜性的轉變。精確性和樣本是相伴而生的,正確的結果來源於正確的信息,而正確的信息需要精確,所以在“小數據”模式裏,數據的不精確會影響甚至謬誤結果。而大數據時代容許不精確的出現,放鬆了容錯的標準,更多的數據得以形成。一來在海量數據面前,單條數據的延遲,謬誤甚至缺失對結果的影響都不會像原來那麼重要;一來,海量混雜的數據,可以促使很多未察覺問題的被發現。“大數據的簡單算法比小數據的複雜算法更有效”。(就像QQ和微信,原來QQ好友是分組,微信好友是貼標籤。)
3. 因果關係向相關關係的轉變。簡單滴説,就是大數據時代,帶來從“為什麼”到“是什麼+怎麼做的轉變”。相關關係的好處在於,一來不需要人工選擇關聯物或者一部分相似數據來分析,一來更準確,更快速,受偏見的影響越小。相關關係分析法指向的是預測,預測是大數據的核心。因果關係在分析事物邏輯演變的內在正確關係,在正確初始條件和正確運衍法則下,才能做出正確的行為。相關關係就像一個黑箱,跳過“為什麼”的階段,從“現象——本質——現象”跳躍到“現象——現象”(找出一個關聯物並且監控它就可以預測未來)整個系統的價值就是告訴我們“會發生什麼而不是為什麼會發生”這是一種不費力(計算系統處理)的快速思維方式,而且可以避免因果關係分析法中人為預設的思維進路死角。理論和實踐都變得更加可行。
大數據帶來的商業變革,大概也有這三個模塊。
1. 人類生活的數據化。數字化是把模擬數據轉換成用0和1表示的二進制碼,而數據化是一種把現象變成可製表分析的量化形式的過程。數據化最早的根基是計量和記錄,在大數據時代,文字可以數據化(如電子圖書),方位的數據化(如GPS),溝通的數據化(Facebook)乃至萬事萬物的數據化(通過手機內置測振儀監測人體顫動來應對帕金森等神經疾病的iTrem,蘋果用音頻耳塞收集關於血液氧合、心率和體温數據的專利等等)數據化帶來的效果是不影響,或者促進了人的使用,也方便了機器的分析。數據化帶來的是一種信息的視角——信息是一切的本原。
2. 數據價值的開發。Luis Von Ahn設計的ReCaptcha就是數據再利用的例證通過模糊單詞識別來確認操作者,破譯數字化文本中不清楚的單詞(“驗證碼”(就是我們每天都要輸入的那個)就是他發明的。)當我們的各類信息,甚至人脈關係,想法,喜歡,日常生活模式甚至心情通過各種各樣的系統加入信息庫時,萬萬千千個人信息庫的集成就帶來了“羊毛出在豬身上”(六模有一門課《信息化思維》就有談到這個商業模式的轉變,然後我期末就寫了Practice Fusion,然後懷着拿A的心情吃了一個B-,生無可戀)數據的價值不會隨着對它的使用而減少,不斷地處理數據卻可以不斷地產生價值,數據的價值是其所有可能用途的總和。這些似乎無限的潛在用途就像是實際意義上的選擇, 選擇的總和就構成了數據的價值,即潛在價值(讀不懂)。數據再利用(如谷歌的搜索詞分析)、重組數據(Zillow.com通過將房地產信息和價格添加在美國社區地圖上,再加之諸如社區近期交易和物業規格等其它信息來預測房屋價值)、可擴展數據(如谷歌的街景汽車不僅拍攝房屋和道路照片,還採集GPS,檢查地圖信息甚至加入無線網絡名稱)、數據的折舊(分離有用無用信息)、數據“廢氣”(如模糊輸入和模糊查詢的實現。數據廢氣描述的是人們在網絡上留下的數字痕跡,比如瀏覽了哪些頁面,停留了多久,光標停留的位置,曾輸入了什麼信息、開放數據(早期如FlyOnTime的航班時間預測)。接着就是一個很有意思的數據估值問題,如Facebook在上市前的定價是每股38刀,總估值=1040億美元=波音公司市值+通用汽車市值+戴爾電腦市值,然而Facebook在2011年供投資者評估公司的審核賬目中,包括計算機硬件,專利和其它實物價值是66億美元,則意味着Facebook公司數據庫中的大量信息的賬面價值為0。無形資產是賬面價值和市場價值之間的差額,數據逐漸加入到品牌,人才和戰略構成的非有形資產模塊中去,大多數數據,數據佔有本身沒有價值,然而使用的價值是無限的。
3. 大數據時代的角色定位。大數據時代裏面的角色,一個維度是數據公司(如擁有海量數據的Twitter,但是它的數據是通過兩個獨立的公司授權他人使用的)、技術公司(為沃爾瑪提供數據分析和營銷策略的Teradata)和思維公司(Jetpac通過用户分享到網上的旅行照片來推薦下次旅行的目的地)的三足鼎立(但有公司是三者兼備的,如谷歌和亞馬遜);另外一個維度是公司、個人和科學家(着重講了數據科學家的崛起,可以參見電影《點球成金》)的動態關係。大數據帶來了盈利模式,交流模式甚至競爭模式的變革。
大數據時代的管理變革,其實分析的是大數據模式的新困境。
1. 大數據成為“第三隻眼”,在不合理的數據應用下就會成為一顆威力巨大的炸彈(如荷蘭的綜合民事記錄數據成為納粹分子搜捕猶太人的花名冊)。再者,我們的隱私在大數據時代被“二次利用”(歐美有每6秒採集讀書的智能電錶,通過能源使用情況可以暴露一個人的日常習慣、醫療行為等等),包括谷歌街景就無法避免對民眾的傷害(無論是否對居民圖像進行模糊化處理,都給盜賊指明瞭行動目標)。
2. 預測與懲罰的突破,我有錯誤,不是因為我“所做”,而是因為我“將做”。阿湯哥的少數派報告就反思了這個制度的問題:罪責的判定是基於對個人未來行為的預測。記得上學期的人生倫理課討論課我就帶着大家跑到一個扯不清的話題裏面去了:一個人無須對自己的感覺負責,但是要對自己的行為負責,一個人要對自己將會發生甚至必然會發生的行為負責嗎?比如A想要謀殺B,A做出了所有的準備,日思夜想,但是直到A傷害B的前一刻,行為都是沒有發生的,思想層面也存在思想改變的可能,儘管這個可能性近乎於0,但是它存在。但是,要是A謀殺了B,做什麼事情B也回不來了,這個問題無解了。大數據就面臨比這更嚴峻的引誘,美國國土安全部研發中的FAST,Future Attribute Screening Technology就旨在監控個人的生命體徵、肢體語言和其它生理模式來發現潛在的恐怖分子。這一切的以後面對的一個討論是,大數據分析如果完全正確(精準的預測不現實是自然的,比如曾有一個大數據模型旨在預測判緩刑的人或者假釋的人提前釋放的話會不會再次殺人,該模型自稱準確率為75%,這意味着什麼呢?如果這樣做,每4個人中就會出現一個失誤。),那麼我們的未來會被精確地預測,我們不僅會喪失選擇的權利,而且會按照預測去行動,如果預測成為現實,我們也就失去了自由意志,失去了自由選擇生活的權利。既然我們失去了選擇,我們就無須承擔任何責任。這否定了法律系統或者無罪推定原則,我們被追求責任,居然是為了自己不會實施的行為 。

所以少數派報告中的阿湯哥是沒法證明自己不會犯罪的,因為我們已經通過預先預警機制制止了這種行為。他沒有按照他的意願去做,我們卻堅持他應該為自己尚未實施的未來行為付出代價,但是我們的預測永遠無法證實。因為他有罪,不是因為事實,而是因為一個極高的可能性。然後100的可能性都不等於事實。一定會發生不代表發生。
3. 數據獨裁。對數據的依賴可能會導致很多問題。比如谷歌要得到被招聘者的 SAT成績和大學平均績點,根據谷歌內部研究表明,這些分數和員工的工作表現是沒有關係的,戲劇的是,谷歌的創始人都沒有達標,而他們正是這個制度的強力推行者。(推薦James Scott的《Seeing Like a State》,這本書就講了政府是如何因為對量化和數據的盲目崇拜給人民帶來的災難。文科館二樓文科書庫應該有,代碼 D035 /S812(3)不出意外的話明天它應該躺在我的桌上^-^)
最後一個部分,作者提及到面對變革時我們自身的變革,也是在為解決大數據的某些弊端,提供一些可能的進路。比如
1. 採取個人隱私保護機制,從個人許可到讓數據使用者承擔責任,監管機制決定不同種類的個人數據必須刪除的時間,信息模糊處理等
2. 個人可以並且應該為他們的行為二位傾向負責。大數據預測,應該保留公開(結論、源數據和算法)、公正(具備第三方的公正)、可反駁(提出個人可以對針對自己的預測進行反駁的具體方式)等原則。
3. 數據算法師的規範應用、外部算法師扮演公正的審計員,內部算法師監督公司數據活動,在考慮公司利益的基礎上顧及他人利益。算法師以公正、保密、資歷、專業水準和責任規範進行強制約束。
4. 反數據壟斷大亨:在立法層面和機制層面(上面三點)等等。