外語專業學生會被機器搶走飯碗嗎?_風聞
一然-别人笑我太疯癫,我笑他人看不穿2018-09-25 16:22
前幾天,科大訊飛被指AI同傳造假一事在網上鬧得沸沸揚揚。
同傳Bell Wang在社交媒體上發文稱,其所負責傳譯的活動現場大屏上展示的實時雙語字幕的中文部分,是人工翻譯+語音識別的結果,但現場佈置會令觀眾誤以為字幕是訊飛產品的機器翻譯結果。
 除了這次的爭議之外,會議AI同傳表現不佳的新聞也時常見諸報端。幾個月前騰訊的AI同傳就在博鰲亞洲論壇2018年年會上出盡洋相。
除了這次的爭議之外,會議AI同傳表現不佳的新聞也時常見諸報端。幾個月前騰訊的AI同傳就在博鰲亞洲論壇2018年年會上出盡洋相。
熬夜觀看iPhone XS發佈會的網友也被由搜狗同傳翻譯的實時字幕逗得樂不可支:
 對這類AI翻車新聞最喜聞樂見的,莫過於外語專業的學生了——一天到晚擔心被AI搶了飯碗,結果一看,你這AI水平根本不怎麼樣嘛,最後還是得靠我們“人腦智慧”。
對這類AI翻車新聞最喜聞樂見的,莫過於外語專業的學生了——一天到晚擔心被AI搶了飯碗,結果一看,你這AI水平根本不怎麼樣嘛,最後還是得靠我們“人腦智慧”。
可是這次笑過之後,下次再有其它AI機翻產品推出時,我們又要懷疑一次人生,思考自己學習外語專業到底有沒有意義。
我們下面以英譯中為例。
給出一個外語句子f(你可以聯想f代表foreign),機器翻譯要找到一箇中文句子 e 從而使P(e|f)最大。利用貝葉斯定理,此處P(e|f)可以轉換為P(f|e) × P(e)。
其中,P(f|e)由翻譯模型負責,對應“信”;P(e)由語言模型負責,對應“達“。
達:P(e)
“達”指通順流暢。中文語言模型需要讓P(通順的中文句子)大於P(不通順的中文句子)。此處可以用的語言模型有很多種,我們以最簡單的N元(n-gram)模型為例。
如果我們想讓P(“我吃飯”)大於P(“我飯吃”),那在我們的一元語言模型中,P(“飯”|“吃”)需要大於P(“吃”|“飯”)。以上操作都只需要中文數據即可完成,還不需要加入英文的數據。
信:P(f|e)
“信”指忠實準確。準確的翻譯是由具有高概率的句子組成的。翻譯模型由大型雙語平行語料庫(parallel corpus)訓練而成。
一個日英對照的平行語料庫
模型會學習中文“吃”在語料庫裏有多少次被翻譯成了英文“eat”。此時我們需要將中文語料與英文語料中相應的詞彙對齊(alignment)。
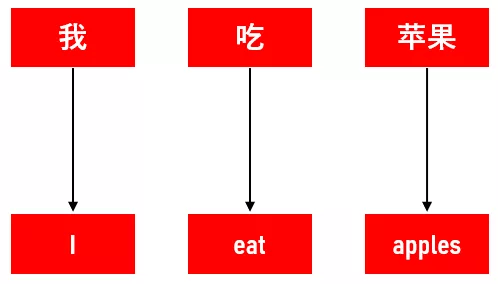
有時一箇中文詞可能需要對應多個英文詞:
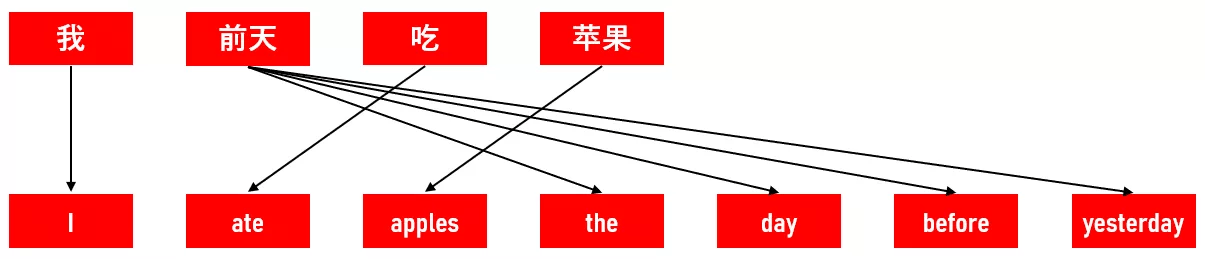
有的英文詞可能並沒有對應的中文詞,這類詞被稱為偽詞(spurious words):
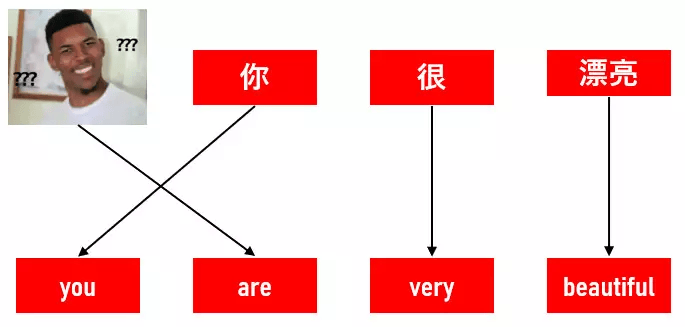 這些都是詞彙對齊算法需要處理的情況。
這些都是詞彙對齊算法需要處理的情況。
“信”不會在乎語序和通順的問題,它只負責找到兩種語言中詞彙的對應關係,而把這些對應出來的詞語組成通順的話便是P(e)“達”的任務了。
機器翻譯關心的不是語言,是數據
當今機器翻譯最大的一個特點是它並不理解文本的意思。
自然語言數據和其他數據對機器來説沒有本質上的區別。統計機器翻譯只關心概率,而神經機器翻譯為什麼能用就是一個謎,連研發者自己也解釋不清,可以理解為是變魔術。
語言的句法、語義、語篇結構、呼應(如:小明很胖,因為他很能吃)等語言學家關心的角度在機器翻譯中沒有任何應用。
雖然忽略語言結構目前不影響語言技術的使用,但這也意味着機器翻譯並不能通過對語境的語義理解來改善自己的輸出,所以也就不能根據文本的領域來選擇對應的術語以處理歧義,也就自然沒有那個奢侈談論“雅”的境界了。這也是機器翻譯和人工翻譯區別最顯著的地方。
由於沒有語言結構做支持,機器翻譯的開發非常依賴語料數據,尤其是內容非常豐富的雙語平行語料庫。如果我們想要為缺乏豐富的雙語平行語料、只有單語語料、甚至缺乏語料庫的小語種開發機器翻譯要怎麼辦呢?
 既然機器翻譯還差得這麼遠,我們是不是完全無需擔心語言科技發展帶來的挑戰呢?AI翻車,我們是不是應該幸災樂禍呢?
既然機器翻譯還差得這麼遠,我們是不是完全無需擔心語言科技發展帶來的挑戰呢?AI翻車,我們是不是應該幸災樂禍呢?
科大訊飛在回應此次事件的聲明中指,發展AI無意用來取代任何職業,所謂”人機耦合”才是未來的方向。
無論我們對訊飛的回應怎麼看,“人機耦合”這個概念我們是應當予以肯定的。語言科技的發展對我們每個人的生活都是有益的。不知道各位還記不記得在搜狗拼音輸入法誕生前用智能ABC打字的日子。我們早已不習慣那種候選詞和想打的詞不一樣的日子。
機器翻譯的發展本身可以幫助翻譯工作者更好地完成翻譯工作。就像我們從來沒有擔心過字典會搶了翻譯的飯碗一樣,機器翻譯也可以是同傳和譯員的得力助手:機器先完成基礎的翻譯,譯員再在它的基礎上進行潤色和修正,人機互補,合作完成更高質量的翻譯。
Google Translator Toolkit 就是一個實用的機器輔助人工翻譯的工具
同時,我相信不少語言類學生也有這樣一個疑問:既然科技公司開發的是語言科技,難道我們不能參與其中,貢獻自己的語言專長嗎?
首先,當今的自然語言處理研究融合了統計學、概率學、計算機科學、甚至認知科學領域的知識,但唯獨沒有語言學。這聽起來很不合理,但的確是行業和學界的普遍實踐。
所以,語言技術的開發和語言學家的關係還是比較小的。它們仍主要是工程師的任務。而成為自然語言處理工程師要求我們必須有很強的計算機背景,對於廣大的文科生來説還是比較難。
但語言學家是可以幫助科技公司處理訓練模型所需的語言數據的。為了獲得高質量的訓練數據,科技公司還是需要語言學家和外語生來協助他們進行審查的。因此,我們可以看到不少創業公司和科技巨頭都是熱切歡迎語言生的。
不過,如果有意進入科技業,語言類專業學生也需要主動接受編程和算法的訓練,這樣才有機會從事計算語言學相關的工作。否則即使進入了科技公司,也只能對着Excel表格檢查數據,十分枯燥。
語言科技的應用雖然看上去很唬人,但它們仍處於快速成長階段。不管它最終能否發展成媲美人工的水平,當下語言類專業學生都無需緊張,且應當積極利用語言技術來幫助我們學習和工作。
但同樣重要的是,在目前AI熱和重視STEM的大環境下,即使我們語言生不會馬上失業,也應當警醒。要不斷隨着科技的發展提升自己,才是應對快速變化的社會的萬全之道。