讓AI一口氣讀完《四庫全書》會怎樣?_風聞
章黄国学-2019-08-14 16:44
“
他花了兩週時間,取得了令人目瞪口呆的古文閲讀水平。
”
近年來, 人工智能技術與人文歷史研究碰撞出不少火花,上個月MIT與谷歌大腦團隊的研究者們發佈了一項最新研究,利用AI技術破解了失傳的古文字,這也使我們不禁好奇,AI對於古代漢語的理解能力怎麼樣?近日,北京師範大學的研究團隊嘗試讓機器從頭學習文言知識,並開始像古人一樣練習句讀。

每當問起語文老師,如何提升文言文閲讀能力?
一定會被告知:閲讀能力的提升,不是一朝一夕……

如果我們讓最擅長記憶和積累的計算機來閲讀古文,它是不是可以做得很棒?
日前,北師大中文信息處理與古典文獻學專業的研究者們嘗試訓練一個“飽讀詩書”的語言模型,並讓TA來參與古籍整理的工作。模型學習的對象包括《四庫全書》與殆知閣語料庫(規模約33億字),而學習的方法則來自語言智能領域最新的深層語言模型。
2018年,谷歌公司推出了深層語言模型BERT,在閲讀理解等11項語言理解任務中刷新記錄,隨後,CMU、百度、OpenAI、Facebook等機構也在其基礎上推出了改進版本。和之前的方法相比,深層語言模型究竟有什麼優勢呢?一是可以吞吐超大量的數據,二是有很強的記憶和理解能力。
**現有的深層語言模型覆蓋了英文和中文,但卻不具備理解古漢語的能力。**於是,研究者們希望通過上述海量的古漢語數據來讓機器“感受”一下博大精深的詩書禮樂文化。在多塊計算卡上並行訓練了約一週時間後,古漢語BERT初出江湖,TA可以像人一樣聯繫上下文理解字詞含義,並將其以數學向量表示。為了檢測其理解效果,研究者們引入了句讀任務。

**在古典文史學習過程中,句讀通常是必備的基本功。古文句讀不僅需要考慮當前文本的語義和語境信息,還需要綜合歷史文化常識,對古漢語知識有較高要求。**宋代大儒朱熹讀韓愈文章,便有“然不知此句當如何讀”之惑,近代經學大師黃侃在致陸宗達的信中也表示“侃所點書,句讀頗有誤處,望隨時改正。”
在句讀的過程中,有三項重要的技能點:
· 利用古漢語特有的節奏和韻律感;
· 聯繫上下文語境信息推敲求解;
· 調用文本之外的歷史文化知識。
試看對應的三例:
1.梅花發寒梢掛著瑤台月瑤台月和羹心事履霜時節野橋流水聲嗚咽行人立馬空愁絕空愁絕為誰凝佇為誰攀折 (朱熹《憶秦娥》)
2.李十一郎行修初娶江西廉史王仲舒女貞懿賢淑行脩敬之如賓王女有幼妹嘗挈以自隨行修亦深所鞠愛 (馮夢龍《情史類略》)
3.此即昔人所謂東坡詩如大家婦女大踏步走出山谷便不免花面丫頭屏角窺人扭捏作態之意 (柳亞子《磨劍室雜拉話》)
第1例為宋詞,其開頭很容易誤斷成“梅花發寒梢,掛著瑤台月”,而事實上“發”和“月”古音押韻,“瑤台月”與“空愁絕”則利用重複表示詠歎效果,故應斷為:
梅花發 〇 寒梢掛著瑤台月 〇 瑤台月 〇 和羹心事 〇 履霜時節 〇 野橋流水聲嗚咽 〇 行人立馬空愁絕 〇 空愁絕 〇 為誰凝佇 〇 為誰攀折
對於第2例來説,“王仲舒女貞懿賢淑行修”處很容易斷錯,原因是未理解“行修”是人名,或把“貞懿”誤當人名。其句讀重點為聯繫前文理解“行修”為夫君,其所娶妻子“貞懿賢淑”,“行修”對其十分尊敬,故應斷為:
李十一郎行修 〇 初娶江西廉史王仲舒女 〇 貞懿賢淑 〇 行脩敬之如賓 〇 王女有幼妹 〇 嘗挈以自隨 〇 行修亦深所鞠愛
第3例出自清華大學解志熙老師文章《斷句背後的知與識——以三則詩文評為例》,該例曾用於清華大學研究生入學考試,《柳亞子文集·磨劍室文錄》與參加考試的大部分學子均將其誤斷成:
此即昔人所謂東坡詩如大家婦女,大踏步走出山谷,便不免花面丫頭,屏角窺人,扭捏作態之意。
此處句讀關鍵在於“山谷”指黃庭堅(文本之外的知識),柳亞子意在比較蘇東坡和黃庭堅兩人的詩風,故應斷作:
此即昔人所謂東坡詩如大家婦女,大踏步走出,山谷便不免花面丫頭,屏角窺人,扭捏作態之意。
雖然現在很多古代經典都有了標點本,但其中常常包含錯誤,上述《柳亞子文集》即是一例。並且,在現有的古籍數據中,大部分文獻仍未實現句讀。據統計,殆知閣古代文獻藏書2.0版語料庫規模約33億字,其中僅25%左右數據包含標點。

如果依靠人工繼續整理這些古籍,則不知何年何月才能整理到頭。如果依靠計算機,現有的技術方法卻普遍只能達到60-70%的準確率,還很難為人所用。
深層語言模型在各種語言理解任務中都取得了大放異彩的效果,能不能GET上述三項技能,幫助我們解決句讀難題呢?

為了讓計算機在理解文義的基礎上具備句讀功能,研究者們準備了大量帶標點的數據,包括超過30萬首古詩,2萬餘首詞,800多萬段古文,模型還引入了處理標籤序列的機制來專門學習句讀方法。
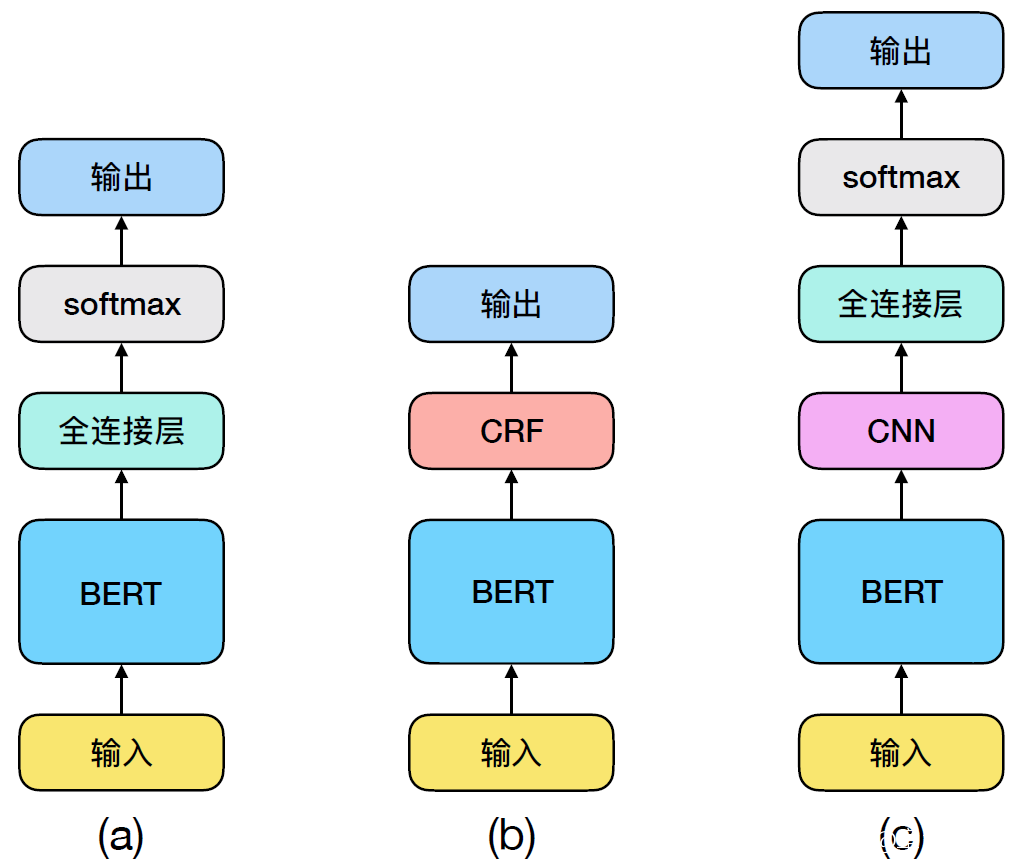
由於詩詞具有較為明顯的格律特徵,如大部分古詩為四五七言,而詞牌名可以提示斷句規則,為了幫助模型更好地學習語義和韻律信息,在預處理數據時保留了古詩題目,並去除詞牌名。
在多塊計算卡上並行學習了數天句讀後,模型終於可以“出山”。在測試環節,研究者們引入了兩輪難度不同的實驗:
普通版測試對象為一批模型從來沒見過的詩詞古文數據(古詩5000首,詞2000首,古文5000段),試驗中,模型在詩、詞、古文的句讀準確率上分別達到了99%、95%和92%以上,較之已有的自動斷句方法取得了巨大提升。
**升級版測試對象為已出版古籍中的句讀疑難案例。**根據司馬朝軍、顏春峯、汪少華等學者研究,從中華書局出版的《欽定四庫全書總目》、《周禮正義》中抽取出了60則句讀誤例(排除了模型訓練時見過的數據)。這兩本古籍均由該領域專家完成整理和句讀標點,並經多次校對,其中的誤例可謂句讀任務的難點所在。

《欽定四庫全書總目》(1997年版)由李學勤作序,是今人重要的古籍整理成果。從司馬朝軍的研究中找出了《總目》中11則與句讀相關的錯誤,發現模型可以完全做對8則,試舉正誤例各一如下:
①
原文:柏何人,斯敢奮筆而進退孔子哉?(《詩疑》第216頁)
模型:柏何人斯 〇 敢奮筆而進退孔子哉 (模型正確)
作者按:“斯”字上屬。“何人斯”為上古習語。
②
原文:其中如“大衍”類蓍卦發微,欲以新術改《周易》揲蓍之法,殊乖古義。古歷會稽題數既誤,且為設問,以明大衍之理。(《數學九章》第1406頁)
模型:其中如大衍類蓍卦發微 〇 欲以新術改 〇 周易 〇 揲蓍之法 〇 殊乖古義 〇 古歷會稽題數既誤 〇 且為設問 〇 以明大衍之理
模型句讀與原文在一處犯了同樣的錯誤,當作:
……《周易》揲蓍之法,殊乖古義、古歷。會稽題數既誤,且為設問,以明大衍之理。

考慮到上古語言與中古語言的差異,為了驗證模型在處理上古語言時的效果,又選擇了王文錦、陳玉霞點校的《周禮正義》一書,將顏春峯、汪少華整理的49則斷句誤例送入模型測試。其中,模型能完全正確斷句27則,斷句存在問題的有22則。
原文:《公羊説》曰:“師出曰祠,兵入曰振旅。”(1485頁)
模型:公羊説 〇 曰 〇 師出曰祠兵 〇 入曰振旅 (模型正確)
《周禮正義》的模型斷句誤例中,較為集中的是對字義的考證,尤其是引《説文》時的錯誤,比如 “服,牝服,車之材”誤斷作“服牝,服車之材”。“服”作為《説文》中的字頭,其用法與其他古文表達有較大區別。此外,因盟誓、考課、葬禮等禮儀制度不明而致誤亦有數例。
從經典古籍中的斷句疑難案例可以看出,基於深層語言模型的句讀方法在處理古籍一般句式表達時有明顯優勢。而在處理《説文》、古代制度等專業性較強的數據時尚存在問題,這與該類型學習數據相對較少有關。總的來説,模型在已出版古籍的斷句疑難誤例上取得了很好的效果,測試共計60例(均為專家標點錯誤,並經多次校對未查出),而模型竟能完全正確斷句35例,可以説達到了較為實用的水平。
看來,讓AI一口氣讀完四庫全書,取得的效果還不錯——
“我是中文系畢業的,實話説,模型的閲讀和句讀能力肯定比我強,看測試case的時候,常常感嘆,它做得真的挺不錯的。”——研發團隊成員李紳
“有時候甚至強過博士後,模型斷句效果超出了我的預期,在我們文獻整理的項目中已經開始用它來做預處理。”——研發團隊成員諸雨辰(古典文獻學博士、歷史學博士後)
從應用角度看,這裏的句讀方法既可以用於大規模古籍整理中預斷句工作,大大減輕專家負擔,也可用於校對環節,幫助檢測人工斷句或標點的錯誤。
為了更好地服務於古籍整理和研究工作,基於古漢語BERT的句讀和標點工具已經對外開放:
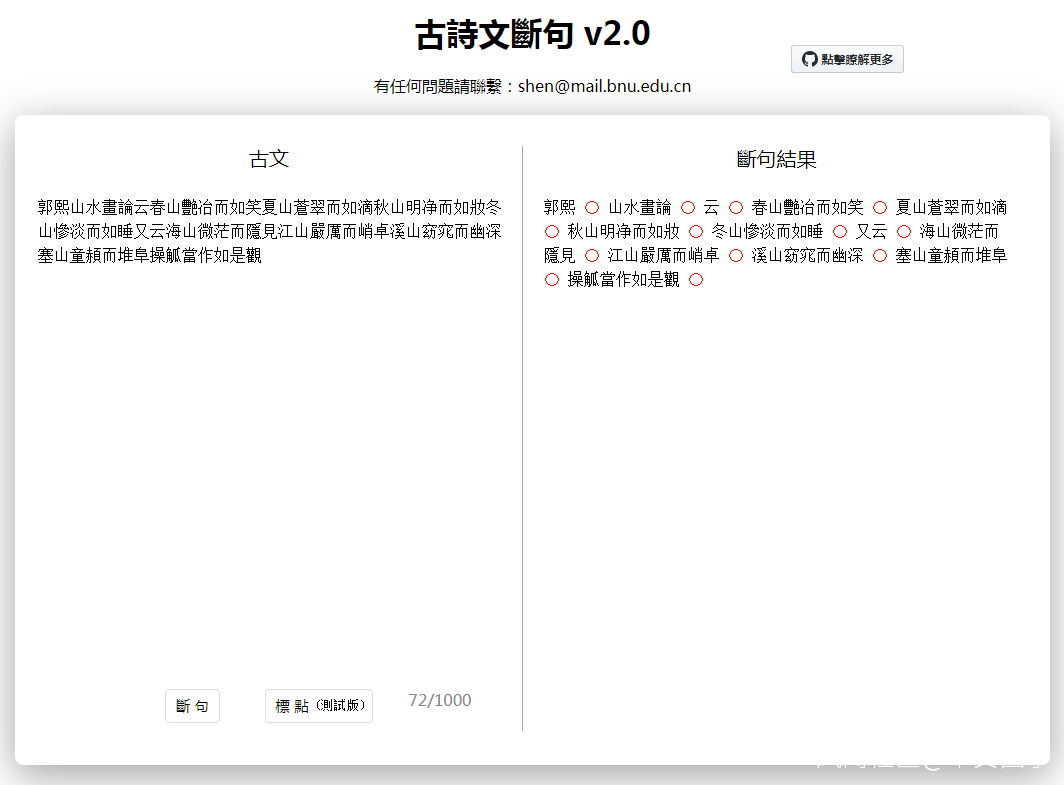
在後續工作中,除了提升已有的句讀模型,還希望將基於深層語言模型的古漢語知識表示方法應用到古文翻譯、古詩文創作等其他古漢語信息處理任務中。
參考文獻:
[1] 朱熹. 韓文考異. 影印文淵閣四庫全書(第1073冊). 台灣商務印書館, 1986.
[2] 黃侃. 黃侃手批白文十三經. 上海古籍出版社, 1983.
[3] 解志熙. 斷句背後的知與識——以三則詩文評為例, 文史知識, 2017(5).
[4] 王博立,史曉東,蘇勁松.一種基於循環神經網絡的古文斷句方法.北京大學學報(自然科學版),2017,53(02).
[5] 張開旭,夏雲慶,宇航.基於條件隨機場的古文自動斷句與標點方法.清華大學學報(自然科學版)網絡.預覽,2009,49(10).
[6] Devlin Jacob et al. Bert: Pre-training of deep bidirectional transformers for language under-standing. NAACL 2019.
[7] 司馬朝軍.中華書局《欽定四庫全書總目》整理本校記.人文論叢, 2013(00).
[8] 顏春峯,汪少華.從《周禮正義》點校本談避免破句的方法.古漢語研究, 2014(02).

作者簡介

胡韌奮
北京師範大學漢語文化學院、中文信息處理研究所講師,研究方向為自然語言處理、數字人文。
李紳
北京師範大學文學院、中文信息處理研究所畢業生,研究方向為自然語言處理,目前就職於DeeplyCurious.AI。


諸雨辰
北京師範大學文學院講師,研究方向為古典文獻學、數字人文。

特別鳴謝
書院中國文化發展基金會
敦和基金會

章黃國學
有深度的大眾國學
有趣味的青春國學
有擔當的時代國學
北京師範大學章太炎黃侃學術研究中心
北京師範大學漢字研究與現代應用實驗室
北京師範大學文學院古代漢語研究所
北京師範大學文學院古代文學研究所
微信號:zhanghuangguoxue

文章原創|版權所有|轉發請注出處
公眾號主編:孟琢 謝琰 董京塵
責任編輯:馮可然
專欄畫家:黃亭穎
部分圖片來自網絡