【數值中心葡萄系統培訓】第二天,資料同化基礎理論錄音稿_風聞
联邦鹰-Stay humble.2019-08-28 12:22
Han:
比如説,我知道了一個温度的分佈或者是氣壓的分佈,某種程度上講,風場的信息是可以導出來的。所以説,這裏面還有一個“由此及彼”。所以説,這就反映了我們資料同化中變量之間的平衡(關聯)。那麼變量之間的平衡有幾種實現條件?其中一種是背景誤差協方差中藴含的一些關係,包括集合預報估計出來的,比如説集合卡爾曼濾波啊,就是估計出來的這些東西,其實也能反映變量之間的相關關係。“相關關係”其實也是一種平衡關係。另外的,比如説四維變分,我們是有模式約束的,比如説我們有了一個温度的觀測結果以後,那麼會自動地把風的信息給“調整”出來。所以説,這裏面變量之間都是有關聯的,由一個觀測可以導出其它觀測出來。
涉及到變量之間的關聯,那就複雜了。
比如説,3km的模式、25km的模式和100km的模式,變量之間的關聯都是不一樣的。還有,就是説空間上,比方説我們北京探空的一個站,可能周圍200km以外才有另一個站。那麼這時,怎麼和空間上其它的點連接起來,也就是説空間上的聯繫。過去最簡單的辦法就是差值,空間反距離權重啊等等很多一些差值算法,這些在地理上用得很多。空間上的聯繫是有前提條件的,需要作一些假設。
還有就是時間上的聯繫,比如説,我們現在北京的大氣,一天前,它在張家口,它從張家口過來。那麼這意味着什麼呢?就是説,我今天觀測的槽脊,可以反推得到一天前它在張家口的狀態。這也就是説,為什麼我們在四維變分同化當中,都把時間窗的信息都用起來,去估計初值的狀態,也就是説,“用時間換空間上的密度”。你比如説,我在新疆沙漠中很難建立一個觀測站,那麼我們可以在它的下游,建立一個觀測站,然後用同化的辦法給它反推回去。比如説,應用在海洋上也是一樣的,我們海面有觀測,海底很難觀測,但是海面和海底是有聯繫的,海面上的觀測可以反推海底的狀態。其實,這些都是同化,就是説一種“由此及彼”。由相互之間有物理聯繫的要素啊,去得到這種關係。
另外就是,與模式的尺度要匹配。比如説咱們風的觀測,大家做觀測員的同志可能有印象,我們看風速的觀測啊,毛毛刺刺的,就是那種非常高頻的振盪。大家想想,如果就説隨機地取這麼一種觀測直接放到模式裏面去,作為這一時刻的模式的狀態,肯定是不合理嘛。因為非常大的隨機性,你這個東西它差幾秒就很大的不一樣。模式積分是每一個時間步,對吧?每一個時間步,也就是説,你要和模式的每一個時間上,要匹配起來。所以説,全球模式也好,區域模式也罷,我把這個原始的觀測怎麼去得到跟模式相關的(數據),這麼一種匹配。比如説代表性,我模式大氣的代表性和我真實觀測的代表性怎麼建立(聯繫),這些問題,其實現在都是開放的,並沒有一個很好的答案。包括説現在衞星觀測,有5min的,甚至更短的,還有説像我們一些雷達的觀測,5、6分鐘啊等等。那麼就是説,這樣一種不同時間和分辨率的觀測,怎麼去和我特定的模式作為匹配,在這個環節上,大家是可以做很多創新的,而不是説,直接把觀測拿過來用。另外就是説,作為一種初值的問題的數值預報,同化分析很重要。因為你當前的狀態不對的話,後面的時刻,你是很難把它做好的。
前面我就是説,為什麼數值預報要做資料同化啊。誤差的來源,一個是初值。其實對我們業務數值預報啊,今天的預報的背景場,就是從前面時刻的誤差帶過來的,所以我們要用資料去修正它。那麼資料同化的概念,我剛才已經説過天氣圖了。那麼同化與反演,用資料反演得到一些參數啊,其實説,同化與反演,也是同一個問題,背後的東西是一樣的。還有就是説,同化與融合,其實也是一樣的。融合就是説,用單變量的,多元的線性的“單變量”的高分辨率的分析,同化呢,是為了得到與模式匹配的比較平衡的這麼一種“多變量”的分析,兩者其實在某種條件下是可以等價的。我們現在做的融合分析,就可以在資料同化的框架下,通過調整背景誤差協方差、觀測誤差,包括一些空間相關的尺度,就可以得到我們想要的融合。還有就是説同化和人工智能,也就是深度學習,其實兩者也是某種程度上等價的。神經網絡反向梯度計算,和我們變分同化裏面的梯度計算,從道理上講是一樣的,只是實現路徑不一樣。我們是一種顯式的算法實現的,深度學習是一種數據的因果關係實現的,但是兩者是有關聯的。深度學習中有一章專門講正則化,正則化就是講,把一些先驗性信息作為約束放進去,這個先驗性信息,和我們資料同化的背景場約束那一項,是同一個道理的。
再一個,就是要了解國內外發展的現狀。對於一個學科要有大的視野。人家在做什麼,我們在做什麼。過去做什麼,未來會做什麼。有了一個大的視野,我們就可以找準自己的座標,這樣子呢也能找到自己前後左右的鄰居。
再一個就是資料同化的基礎理論。涉及到三維變分同化、四維變分同化、卡爾曼濾波、集合卡爾曼濾波,這麼多東西,一上午講起來可能難以聽懂,但是我認為有些東西是相通的,做不同領域的人可以相互交流。
衞星資料同化,我重點講一些理論方面的,包括和觀測系統相關的。後面再讓Wang博士把一些具體的針對GRAPES衞星資料同化的一些框架性的東西,包括一些實驗,再講一下。
GRAPES全球四維變分,2018年上業務。發展過程中,一些關鍵性的東西如何診斷是很重要的。現在區域快速三維變分同化呢,我們也是還在做,而且我們全球和區域是一體的,也就意味着,我們很多全球的工作,在區域裏面是可以用的。它的基本理論是基於各種同化算法,比如基於變分啊,集合啊這些,這些聯繫,包括這些算法的發展和應用。
如何入手?上手單點實驗!突破單點試驗這一步,就明白了資料同化是怎麼一回事。別人給你講一萬遍,你自己不動手實踐一遍,也沒用的。再一個就是入門教材,1999年歐洲中心的技術文檔,是最好的教材,很有條理,沒有任何基礎的人都可以從這裏看起。它的前一半,需要非常認真地看。
目前的一些主流的算法呢,像三維變分、四維變分、集合卡爾曼濾波,包括一些混合的辦法,其實呢,這裏面,背後,是一脈相承的,沒有什麼太多的新東西,只是説不同的實現途徑而已。比如説,混合的,集合和變分混合的,無非就是把集合預報得到的背景誤差信息,想了一個辦法,放到我們原來統計得到的B裏面去。你要清楚背後的聯繫,不要覺得好像是一個全新的東西。同時,也要了解方法背後的數學原理。概率論、控制論、反問題、最優化,做資料同化,不一定要對這些方面全部瞭解,但一定要有自己的切入點。比如説我本人就是從偏微分方程最優控制,從這個角度,切入到資料同化裏面的。等你瞭解清楚這些東西,你再看,從貝葉斯概率論過來的東西,或者是從反問題過來的,其實都是一樣的,大同小異的。所以説,大家一定要有自己的切入點,背後的數學,要花一點時間的。在一個就是物理,因為資料同化不單純是一個數學問題。我們很多人一看,啊,一大堆公式,又是矩陣又是方程的,好像它是個數學問題,其實不是的。你看看真正做資料同化的那種大家,純數學的,做好了他也不懂。所以説為什麼呢,大氣也好,海洋也好,地學也好,裏面的物理過程太複雜了。只有你對你的物理問題非常瞭解了以後,你才可能做各種各樣的簡化,抓住主要的一些東西,把一些次要的、目前技術條件解決不了的東西,忽略掉。比如説一些模式的偏差和誤差,包括説變量之間的相關。比如説,海洋資料裏面,温度和鹽度啊,它們並不是説是完全獨立的,而是有關係的。同時,也希望大家多看看,同化方法在各領域裏的應用。大氣面向數值預報的資料同化,每天都受到實踐的檢驗。把大氣資料同化學好了以後,用到其它領域,也是可以的。第二大方面,是瞭解一些方法背後的假設。這個我要特別強調一下,我們要清楚是通過什麼條件得到的最優。對觀測有什麼假設?比如説,99年教材提到,“觀測是無偏的”,但我們業務並不是這樣。不僅不是無偏的,現在幾乎所有觀測,都是有偏差的,這個就很要命。還一個就是模式,模式假設也是無偏的,但實際上,不是的。比如説GRAPES物理過程,涉及到那麼多算法,各種變量的偏差,在這種情況下,對於一個有偏差的模式,你怎麼去做同化(,也是一個挑戰)。關鍵參數,關鍵參數包含哪些呢?你比如説“背景誤差協方差”,那這個協方差是我們統計的,這個統計的東西,跟我們真實的背景誤差協方差,多大程度上,抓住了哪些東西,那麼這裏面,也不是説完美的。我説的這些東西,也包括對觀測誤差。當所有這些東西,條件都滿足的時候,那是個最優分析。所以説咱們實際上,業務上做的,都是個次優的,不是最優的。我們做資料同化呢,就是要在這些假設的方面,把它們做得更完美。再一個,就是對一些説法和判斷呢,要做自己獨立的思考。從問題出發,不要被一些權威和論文迷信,教條。發表一篇論文,只要兩三個審稿人就可以了。發表一篇論文,不代表它是對的,而代表它目前符合行業規格而已,現在國內外這種論文太多了。所以説,對於一些文章的結論,千萬不要盲從。很多中心的選擇,不是從方法上的先進性選擇,而是要立足現實。鼓勵大家學習Python。我們現在和深度學習團隊合作,試圖找到四維變分和深度學習之間的橋樑。國外有一些研究,用深度學習的辦法去構造微分算子。再一個就是觀測系統,資料同化資料同化,資料一定是非常重要的,我們對新的觀測系統,要敏感。要了解中心的未來發展目標,特別是工作的年輕人,一定要有一個未來一年、三年、五年的發展目標。到了哪些關鍵點,要做到什麼地步。
在歐洲中心的網站上,每年都有培訓的資料和材料,其實完全可以去下載網上的錄音和PPT。建議把前些年的東西看一看,因為前些年的更系統。
看資料同化系統,先得了解觀測。觀測就是來自於哪些觀測系統。
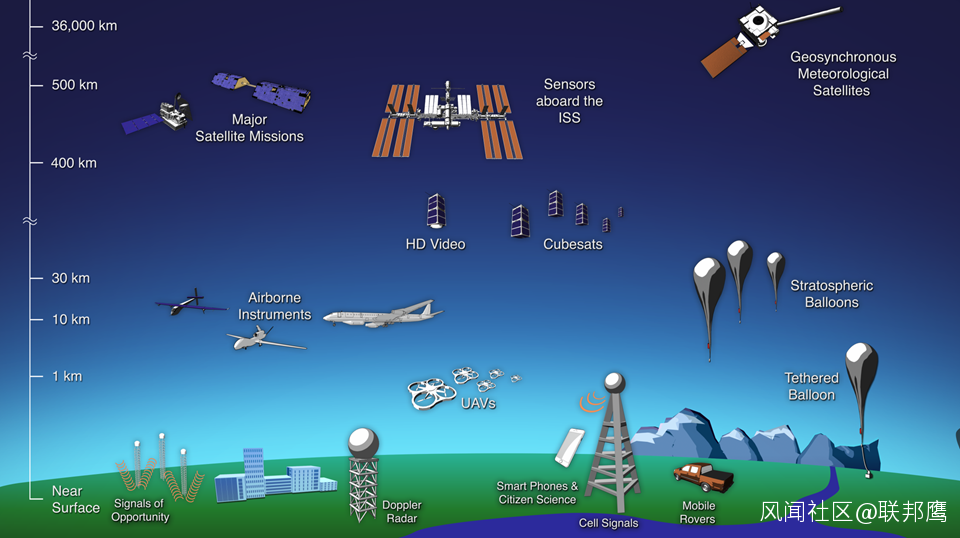
如上圖,左邊,就是從地面,到36000km的靜止衞星軌道。目前我們的全球模式在33km左右。區域模式到10hpa,也就是在30km左右,稍微低一點。未來,我們今年要到60km左右。地面的觀測很多,全國有5萬多個自動站。其實地面上各種觀測系統……包括我們每個人的手機,都有温度傳感器和氣壓傳感器。現在就有人開發一種APP,把每個人手機的氣壓傳感器的信息收集起來,做一些預報。也挺有意思的,將來,有人的地方就有觀測。還有就是像雷達,我們國家有200多部,每天都在6分鐘一次的觀測,但是比較可惜的是,到目前為止,我們的雷達資料還是沒有進入到我們的數值預報系統中去。非常可惜啊!因為1部雷達1天的成本折算下來要1萬左右,你想想,1天200多萬,就這樣……不過預報員還是會看雷達回波圖的,但是這種利用是遠遠不夠的。還有你看像汽車,其實每個汽車都有傳感器。其實啊,這種傳感器,無處不在,但是現在都沒有得到利用。其實我的意思是説,這些信息,都可以通過資料同化的辦法用到數值預報裏面去,都是可以用的!所有的觀測,咱們的數值預報,都是可以用的!只不過現在由於條件啊行業啊的限制……其實我想未來都是可以實現的。氣球,大家是都知道的,大家想想,為啥我們過去,都是全球固定同一個時間同時放氣球啊?放氣球是二戰後,全球無線電收發實現以後的事。因為數值預報是一個初值問題,初值,我就在t=t0時刻,t0是一個時刻,對不對,我全球,大家都在那一個時刻探測回來以後……過去我們預報都是00時和12時,為什麼全球數值預報都是00時和12時啊?也是因為咱們過去放氣球。全球數值預報,咱們能不能快速循環?我逐小時都能往前預報?可不可以?這完全可以。因為現在衞星,可以在每個時刻都可以形成一個全球的觀測,得到一個對初值的估計,那麼理論上,我任何時刻都可以向前預報。所以我全球也是可以快速分析的,不止是説,區域可以快速分析。再往下,就是咱們平時乘坐的飛機,飛機上有温度和風的觀測,一般沒有濕度。現在有的飛機經過改造記錄濕度數據,公司專門賣這個資料。但是比較可惜的是,咱們國內航空幾個大的航空公司,國航南航,他們的資料都不上傳。為什麼?因為上傳就要租衞星的通訊線路,一條信息好像要多少錢。他們説,可以通過北斗,短信息上傳,而且很便宜。我就問他們,既然這樣,為什麼不用北斗傳這個信息呢?他説,這個,我們的飛機都是進口的,進口的飛機,裏面是什麼都不能動的,哈,就是説,你所有的信息資料,什麼都不能動的。所以説,為什麼要“自主發展”啊,你不自主發展,是沒辦法創新的。這是飛機的觀測。上面還有衞星的觀測。那麼衞星,咱們全球衞星分為兩類,一類是靜止衞星,一類是極軌衞星。風雲衞星系列,奇數號都是極軌衞星,偶數號都是靜止衞星。極軌衞星繞着兩極轉,可以實現全球觀測。靜止軌道上,可以實現一個高分辨率觀測,特別像咱們風四,風四就可以實現一個垂直觀測。有了觀測系統以後,我們就可以通過一定的同化算法,形成在每個網格點上的分析。這就是咱們資料同化做的事情。所以説,在這些年,在咱們數值預報裏面,有兩個領域最活躍,一個是資料同化,再一個就是物理過程。資料同化的活躍,就是有不斷湧現的新的觀測系統出來。有了一個新的觀測系統,你想把它做好,就得做得非常精細才行。就是説,每一個觀測,都要花費人力。再一個物理過程呢,隨着網格越來越小,過去很多物理過程的一些假設啊,假定啊,都不滿足了。所以説,這兩個領域,應該是這些年最活躍的。人數上就可以看出來,你看歐洲中心,它各個方向上,資料同化和物理過程,這兩個人數是最多的,當然,動力框架也很重要。但是,動力框架呢,想做壞事很容易,想做好事很難。你可以把它算準,但不一定結果好,因為結果好你還得初值好,你還得每個柱兒裏面物理過程各種量算得好。所以説,你動力框架不搗亂就是最好的。在動力框架上,國外投入的人力相對比較少。但是資料同化,特別是資料方面,衞星啊雷達啊,甚至每一顆衞星的紅外微波這些,都不一樣。所以説,資料同化是一個蓬勃發展的行業。就是我剛才説的,咱們數值預報,這個專業領域比較年輕,也就100年。數值預報中的資料同化,更是一個,朝陽中的朝陽。大家做這個行當,不説別的,未來至少有飯吃。包括申請一些項目,總是會有的。這些,有些數量的估計,應該説現在衞星的觀測是越來越多了。其實,衞星,之所以,容易實現,最主要的是因為它能夠快速地實現全球,實現選址。你比如説,你裝個雷達,又得供水又得供電,還得把周圍那些基礎設施啊都建好,比較麻煩。那衞星,只要火箭,打上去以後,差不多十來年,你就不用管它了。所以就是説,從這個角度來説,這個衞星呢,還是一個性價比比較好的。舉個例子,地基紅外的高光譜儀器,一台小儀器,大概300萬左右。我們現在未來的立方小衞星,一顆衞星,包括火箭發射的成本,才500萬。大家想想,一個小衞星能實現全球的觀測,一個地基儀器只能實現一個點的觀測,大家想想,這種觀測帶來的效益。所以説,為什麼現在咱們這種商業航天發展得非常迅速。我想,未來的咱們的這種衞星的觀測,還會越來越多。資料同化呢,就是要把我們的資料,和模式結合起來。
我剛才寫了一個公式啊,在那裏面…….我們這個,我就以變分(為例)啊,我們這個目標函數(J=Jb+Jo+Jc)裏面,有一個背景場(Jb),有一個觀測項(Jo),還有一些其它的約束項(Jc)。那麼這個背景場是説什麼呢?就説,大家可以看這個啊,這個其實很簡單,就是説,我們最後得到的這個場呢,數學上用泛函的模來表示。就是説,我這個場呢,和這個點的距離,不要太遠。我原來得到的一個背景場,就是説從昨天預報過來的,就比如説,我們昨天的預報,我們在這個格點上,比方説27度,你分析的時候,不要離27度太遠,如果大家一開始看到這種向量的符號比較費勁的話,就把它當成標量好了。這就是背景場,你最後分析得到的,不要離我這個太遠。另外還有一項呢,就是説,觀測項,觀測項呢,就是説我這個yo,和我這個,就是説,你最後分析場得到的這個東西,和我的觀測的,也不要離得太遠。實際上是一種妥協,是吧。你既不要離我背景場太遠,也不要離我觀測太遠。那麼這裏面,究竟多遠算遠呢,好,就是這裏面的,背景誤差和觀測誤差,這兩項,來決定的。如果你得到的當前估計非常不準,誤差很大,B很大,B是在分母上的,大家把它當做標量想,不要看成矢量了。所以説,即使你這一項算的很大的話,在分母上,你這一項也不大,對不對?所以我就可以向,觀測項,很逼近。

我們用一個幾何來表達它啊,假如我知道這個地方,大氣有個真值。我這個地方呢,有一個觀測。我這個地方,是它的背景場。這一段距離是觀測誤差,這一段距離是背景誤差。我們能得到的這一項呢,這就是yo-H(Xb),它就是(O-B),即當前,你得到的背景場,和觀測之間的距離。有了這個信息你才能做同化,才能有增量,對吧?大家想想,我們最後的分析場,會在什麼地方?分析場就是過真值點做垂直於背景場和觀測值的連線的線交點。分析場到真值的距離,是分析誤差。觀測減背景是O-B,觀測減分析是O-A,最後你的分析場落在觀測和背景場的之間,這是,相對比較理想的狀態。大家想想,有沒有可能落到邊上去啊?有的時候,就是你有多個觀測影響的時候,或者系統設置不合理的時候,就會落到邊上去。除了背景場項和觀測項,我們還可以加一些約束,比如説數字濾波啊,就是各種,我們已知的信息,可以放上去。其實從反問題的角度看,資料同化這些融合,都是放在裏面的。
一個複雜的系統,如果不是自己設計自己發展的話,你很難給它消化透。你看國內好幾個中心,在業務上還是跑的WRF,但是,所有跑WRF的,慢慢得慢慢得,評分都上不去。
同歐洲中心比,我們還是有差距。但是這幾年,我們進步還是巨大的。
這是北半球,我們和歐洲中心再分析的一個比較。你看我們2010年的時候,差得很遠。經過幾代發展,終於有了很大的改善。