關於淘寶三次擬合造假的一兩個可笑之處_風聞
Berboba-2019-11-14 06:05
廢話不多説,我們同樣取十個點,鏈接為國家統計局北京市1999到2008年GDP核算http://data.stats.gov.cn/easyquery.htm?cn=E0105,如下圖:
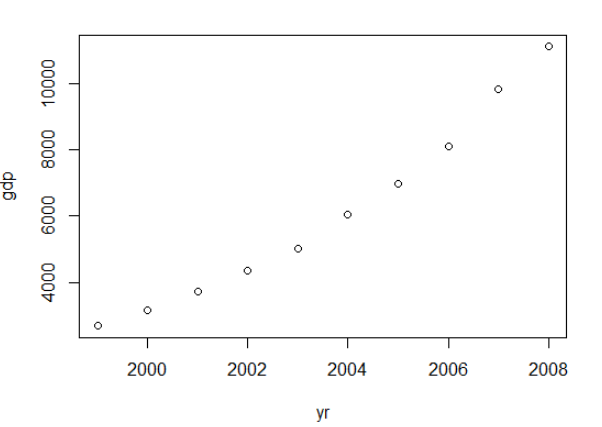
那麼下一步就是像某人一樣用此數據做三次迴歸,也就是y = ax + bx^2 + cx^3 + e,計算R^2如下:
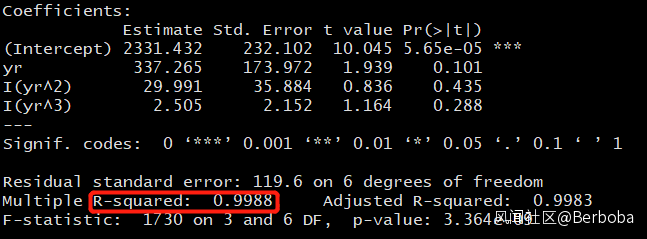
這就是所謂”擬合“,本人的也不差嘛,99.88%,哼哼,北京市GDP核算造假了吧?做個預測簡直是輕輕鬆鬆嘛… 唉,真替某些人着急啊…
所謂統計學的模型,引用一句George Box的名言,想必各位業內都知道的:

先不説這個三次迴歸,某人所謂的“擬合”也就是R^2叫做Coefficient of Determination,也是一種模型,只不過年代久遠(1921),來源於 Sewall Wright 那片大名鼎鼎的文章 “correlation and causation”。具體的就不長篇大論了,現代統計學中其實我們已經較少的用到R^2來判斷某個模型的擬合度了,原因很簡單,隨着你變量的增多,比如變為四元四次: y = ax + bx^2 + cx^3 + dx^4 + e,這時候我們再去計算:
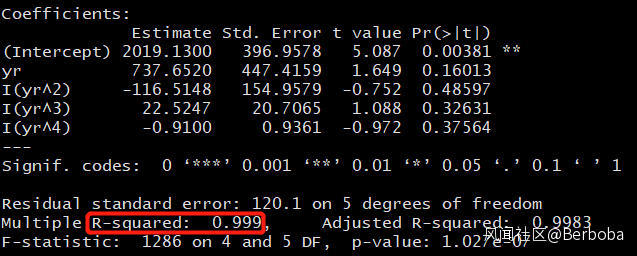
R^2 = 0.999,變量多了殘差的自由度降低,最後到了x^9那麼R^2 = 1。針對這個問題後人還發明瞭很多方法,比如adjusted-R^2等等,甚至根據目的和模型假設的不同已經細化為多種指標,這裏就不贅述了。
其實尹某人最為嚴重的錯誤,是把年份直接用來當成自變量擬合,這是完全錯誤的!帶有時間屬性的數據,時間本身不能作為變量直接套用迴歸模型,因為這違背線性迴歸模型自變量相互獨立的基本假設,這種行為產生的模型直接就是無效的。在統計學中的建模,最開頭除了要對數據有一個基本方向之外,必須要對數據做檢驗,看看其是否能夠滿足模型的基本假設,絕對不是隨隨便便套個幾次方程就完事… 一般來説很多學生會選擇陳平大佬最看不起的隨機過程衍生品,也就是今天流行的時間序列,這已經是最低要求,可以見得微博上公知的可笑之處。
PS:不管加多少指數x^2還是x^9,都叫做線性模型,所謂線性指的是 y = ax + bx^2 + e 的係數a,b,而非自變量x。