漢字的特殊性和科學性——形義文字論 10—13_風聞
华民-2019-11-15 14:00
漢字的特殊性和科學性
——形義文字論 10—13
作者:夏國民
十、解頂中區N200之謎
前文曾提及,二〇一〇年前後,現復旦大學張學新教授當年在香港中文大學帶領的一個由我國多地研究人員組成的團隊,採用腦電技術進行視覺詞彙識別科學實驗,發現了中文特有的“頂中區N200”腦電波,但該重要發現至今仍是一個沒有完全解開的謎。本節試圖持形義文字論的觀點聯繫相關的實驗結果對其作進一步的解讀。
漢字是二維圖形結構,多字詞彙又是其重要特色,識別時會有特別的心理加工過程嗎?
“早期的一些心理學實證研究提出,較之拼音文字,漢字識別加工更多地涉及右腦。此後基於腦損傷病人的神經心理學研究也有類似的觀點。”[29]
早些年這方面的研究是以行為方法為主,近些年科學家們使用最前沿的認知神經科學技術進行研究。新技術能更為直接地記錄認知過程中的腦神經活動,超越了過去依賴行為指標間接推測大腦活動的侷限性。
中國科學院和國家自然科學基金委員會共同主辦的《科學通報》2012年2月第57卷第5期以封面圖文形式刊登了張學新教授等撰寫的《頂中區N200:一箇中文視覺詞彙識別特有的腦電反應》,該文報告的是理解思維和人腦信息加工中視覺詞彙識別的神經機制。他們使用腦電技術,對中文雙字詞的識別進行了系統的研究,具體實驗是採用語言文字研究中常用的視覺詞彙判斷方法。
因為一秒等於1000毫秒,腦電技術具有毫秒量級的分辨率,能夠清楚地顯示視覺詞彙識別的時間進程。
實驗“結果顯示,中文雙字詞在其呈現後約200ms誘發了一個負走向的、以腦頂部和中央區域為中心、分佈廣泛的腦電反應,稱為頂中區N200。此外,詞彙重複呈現時,該N200出現一個罕見的、大幅度的增強效應。類似的效應在英文等字母文字的識別中並不存在,提示頂中區N200是一箇中文特有的腦電反應”。[30]
實驗涉及相當廣泛和高級的視覺加工腦區,首次揭示了中西文詞彙加工腦機制上的區別。
在這裏,中文詞彙重複呈現時,N200出現的增強效應,稱為重複增強效應。
文獻記載,在視覺詞彙識別實驗研究中,被試頭部佈置的大多數電極上都會出現N1、P2和N400這三個詞彙識別腦電成分。
N1、P2和N400是文獻中廣泛報道的跟語義(字詞義)加工機制密切相關的三個腦神經指標。前兩個成分反應刺激物的基本物理屬性(如視覺複雜度)特有的基本感知加工,之前有潛伏期。N400是腦電在語言文字研究中最重要的發現,它在重複啓動下的幅度變化也是最顯著的腦電效應之一,其特性通常是對無意義刺激顯示更強的反應。
下圖中,上方第一個峯值點為N1(負向向上),下方第一個峯值點為P2(正向向下),上方第二個峯值點為N400,N200腦電波峯出現在P2之後。中文詞彙第一次呈現誘發的波形為藍線,重複呈現誘發的波形為紅線。
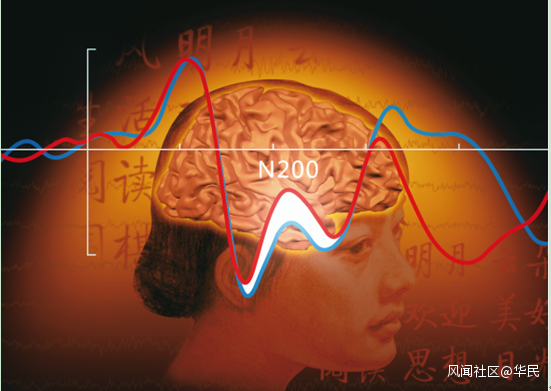
(上圖截取於《科學通報》2012年2月第57卷第5期封面圖,橫軸為時間,單位為100毫秒。縱軸為波幅。)
在特定的實驗中,被試都是母語為漢語且不懂諺文的大學生,實驗結果顯示,跟中文詞高度匹配的諺文詞並不誘發N200反應,説明漢字對被試而言是有語義(字詞義)的視覺材料。進一步推論,上述實驗結果不支持對N200的感知覺解釋,説明把兩個一般視覺刺激在空間上並置起來並不能誘發N200反應。
形、音、義是文字的三要素,漢字詞彙是由單字組成,因而漢字詞彙的三要素也都必不可少。實驗顯示,漢詞同音不同義對照條件下(如:斟酒,針灸。)誘發的N200波幅沒有任何統計區別,説明詞音啓動不影響N200。而漢詞同義不同形對照條件下(如:説明,解釋。)誘發的N200波幅也沒有任何統計區別,説明詞義啓動也不影響N200。因此,在邏輯上N200的重複增強效應必然是視覺漢詞形態的加工。
N200不反映感知覺加工,也不反映詞音和詞義加工,只反映漢詞形態識別加工,説明它是一個反映中文與拼音文字不同加工機制的腦神經指標。又由於選用單個漢字識別的研究結果也不能誘發頂中區N200腦電反應,並且與英文單詞的N1、P2和N400腦電反應沒有區別[31]。因此,這為“中文裏存在單字和詞彙兩個不同層次的表意單位”提供了強有力的科學佐證。
對於中文詞,與對照條件(詞彙形態不同)相比,重複啓動條件(詞彙重複呈現)導致N400幅度顯著降低,這是詞彙識別文獻中早已確立的重複啓動效應,表明一個詞彙的第一次加工,明顯促進了它第二次呈現時的語義(字詞義)加工。重複啓動條件同時還導致N200幅度顯著增強,這表明N200與N400存在此長彼消的相關性和聯動性。
N200反應漢字詞形加工,N400反應語義(字詞義)加工,兩者反應的屬性不同。但N200反應在前,N400反應在後,如果將前者看成是原因,那麼後者就是結果。
從時間軸上看,漢字詞彙的詞形已經在200毫秒時段得到識別,顯示為N200。已知隨後發生的N400對詞頻敏感,能區分真假詞,反應了詞彙水平上的詞義通達。兩個結果相結合,就把從詞形識別到詞義通達這個過程限定在了N200到N400之間。或者説,由形到義的轉換就在其間,並且對詞義的喚醒也在其中,因為研究使用的視覺詞彙材料很多都是被試者高度熟悉的。
實驗結果顯示,高頻真詞重複條件下N200幅度最高而N400幅度最低;真詞(如:研究)與假詞(如:技究)對比條件下,假詞的N400幅度很高,這符合N400對無意義刺激有更強反應的通常特性。所謂假詞,就是不構成真詞,也不跟任何真詞同音,但其物理屬性跟真詞完全匹配。
由於單字的字形信息是雙字詞詞形信息的一部分,可以構成局部詞形重複,通過操縱啓動詞(前)和目標詞(後)之間的詞性相似性來觀察N200重複效應的變化。實驗顯示,從對照條件(如:錢幣——微弱)、尾字重複(如:流利——互利)、首字重複(如:榮幸——榮華)到完全重複(如:思索——思索),N200的波幅是依次增大,而N400則呈相反走向是依次減小。
上述實驗結果表明,漢字是比其它文字更為徹底的以形示義文字,詞中的部分字不同就有不同的腦電反應;漢字詞彙由形轉義或詞義的喚醒是在大約一百毫秒的時間段內完成。這就提示,漢字詞彙存在一個比其他文字更加複雜的腦電反應,而且能承載比其他文字更為豐富的詞義功能,當然前提是漢字結構具有強大的構形功能。
由此可以總結出N200出現的必要充分條件。這裏的各個漢字都是有意義的視覺材料(原來就認識),這是必要條件,這個條件其他文字的單詞也都具備。但是,漢字詞彙由單個漢字組成,形式比單字更復雜,並且是作為整體出現,同樣應該是有意義的視覺材料,漢詞形態需要進一步識別,這是充分條件。
因為其他的拼音文字以及單個漢字都不具備漢字詞彙這樣能夠而且需要進一步識別的充分條件,所以N200為漢字詞彙所獨有。
為什麼上述充分條件其他文字都不具備呢?
世界上同樣是由30個左右符號(筆畫或字母)組成的不同文字,只有漢字是由筆畫(符號)二維構成,漢字詞彙由字組成(主要是二字詞,三字以上的詞相對較少),漢詞與漢字是兩個不同層次的表意單位,二者的構成符號均非常集中,而且意義或概念都明確。儘管漢詞裏面包含的單字跟單個使用的單字是相同的,但這種漢詞的義與單字的義一般來説是不同的,且通常都能夠識別。例如,漢詞“中國、法國”與單個漢字“國”比較,前者詞彙的形相對複雜而義更清晰一些,後者單字的形相對簡單而義更寬泛或模糊一些。其他文字的單詞基本上都是由字母(符號)一維線性排列,因為它們都是通過音節組合來表意,每個單詞不能也沒有必要再進一步識別,就象識別單個漢字一樣。
進一步推理,上述必要充分條件與字詞符號(筆畫或字母)的多少無關,只與字詞的構成方式或組成形式相關。只有一個筆畫的漢字與擁有十個筆畫構成的漢字,或者只有一個字母的單詞與擁有十個字母排列的單詞,在視覺腦電技術實驗中沒有區別,但是,由單字排列組成的漢詞與由字母排列組成的單詞卻存在完全不同的根本區別,這也許就是腦電科學技術實驗結果告訴我們的重要答案之一。
漢字的33個“橫豎撇點折”筆畫(現代漢字折筆筆畫25個),能夠千變萬化地構成一個個基本表意單位即漢字,然後由字組詞,又能形成呈幾何級數增長的複合表意單位即漢詞。如此獨特的組成形式和表現方式,尤其是其合理性或科學性,可以説已經得到了現代科學技術的驗證。
從邏輯上來講,形義文字論拓展了漢字拼義論[32]的空間,涵蓋了漢字單字和詞彙兩個不同層次的全部,進一步闡明瞭漢字所特有的字詞學説,結合對N400等相關科學發現的分析,可謂已經解開了頂中區N200腦電科學發現之謎,因而也就有了科學的依據。
十一、快速查字典
漢字數量大、結構較複雜,千百年來一直缺乏一個科學、快速的檢字法。常用的幾種傳統檢字法都存在嚴重缺陷。1、部首檢字法歸部原則不明確、查字繁瑣;2、四角號碼檢字法歧義性強且規則龐雜;3、筆畫序列檢字法編碼冗長而費時費力;4、音序檢字法無法處理不知道讀音的字。因而長期以來,人們總是羨慕字母文字按字母順序查字快,殊不知現在查漢字也完全可以超越字母文字了。
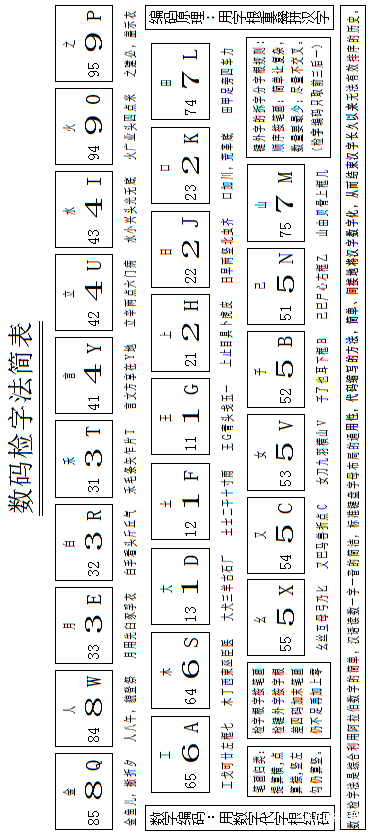
這裏簡單介紹一個名為“字根數碼檢字法”的方案。該方案是用代碼縮寫的方法將漢字數字化,能夠解決上述傳統檢字法的主要問題。
字根數碼檢字法是將標準鍵盤上除Z以外的25個英文字母分為1至9個區,將二百多個字根分佈在各個字母鍵上(詳細形態要見字根表),檢字時用各自的區號代替字根並按規則編四碼,在檢字表中對號入座查讀音。例如“座”字的字根依次是“廣、人、人、土”,檢字編碼是9881,查讀音是zuò,位列第11版《新華字典》678頁。
字根數碼檢字法把所有漢字分為字根字和非字根字兩種。以下是拆字和編碼規則。
(一)字根字,即字本身就是字根,總共有一百多個。例如“日、月、水、火,山、石、田、土”等。
1、字根字拆字規則:將字根字按筆畫順序拆成“橫、豎、撇、點、折”五種單筆畫字根。例如,“方”字應拆成“丶、一、乙(折)、丿”四個單筆畫字根。
2、字根字編碼規則:按筆畫順序編四碼。
(1)如果字根字的單筆畫字根數(即筆畫數)多於四個,取前三個和最後一個進行編碼(即前三後一)。例如“金”字的檢字編碼是3411。
(2)如果字根字的筆畫數少於四個,則在後面補0至四碼。例如“人”字的檢字編碼是3400。
(二)非字根字,即字本身不是字根的大量普通漢字。
1、非字根字拆字規則:順序按筆畫,簡單讓複雜,數量要最少,儘量不交叉。詳細解釋如下。
(1)順序按筆畫:拆字分字根,按筆畫順序進行。例如“武”字應拆成“二、止、乙(折)、丶”四個字根。
(2)簡單讓複雜:一般情況下,筆畫少的字根要讓位於筆畫多的字根。例如“美”字應拆成“點撇、王、大”三個字根。
(3)數量要最少:將字拆分後所得的字根數量要求最少。例如“為”字應拆成“丶、力、丶”三個字根。
(4)儘量不交叉:在滿足以上條件的前提下,字根與字根之間儘量不要交叉。例如“知”字應拆成“撇橫、大、口”三個字根。
這裏所稱的字根,是指各個漢字中相對簡單並符合拆字規則的一部分,一共有兩百多個。每個字的字根都是固定的。
2、非字根字編碼規則:按筆畫順序將字根等編四碼。
(1)如果字的字根數量多於四個,取前三個和最後一個(前三後一)編碼。例如“橫”字的檢字編碼是6618。
(2)如果字的字根數量只有三個,要將最後一筆重複使用一次,作為單筆畫字根來加長編碼。例如“最”字的檢字編碼是2554。
(3)如果字的字根數量只有兩個,編碼先按上條方法處理後再加0。例如“邊”字的檢字編碼是7940,又如“碼”字的檢字編碼是1510。
由於擁有阿拉伯數字的順序,加之漢字讀音是單音節,為漢字的代碼檢索提供了可供利用的優越條件。數碼查字是按照編碼的數字順序直接查找,速度很快。掌握字根數碼檢字法後,針對第11版《新華字典》,利用“字根數碼檢字表”,無論對要查的字是否認識,從眼晴看到字開始,只需幾秒鐘就能查到讀音。例如查“芻”字數碼是8510,讀chú。
不僅如此,根據“字根數碼檢字表”上的讀音,要進一步瞭解生字的意思,所有含有漢語拼音的字典都能利用。
再者,藉助“字根數碼”教識字,因全部“分塊”而易學。例如,將“狗”拆成“犭、勹、口”三個字根,即分為“5、8、2”三塊。這樣用數字代碼幫助記字塊學習漢字,稱謂簡單,記憶爽快。
字根數碼檢字法主要是借鑑了四角號碼檢字法的代碼方法,吸收了王永民教授五筆字型拆字高效(按塊)和筆畫檢字法拆字易學(按筆畫順序,有規律)三者的優點,克服了部首查字首尾脱節(繁瑣)、筆畫檢字法查字太慢(冗長)、四角號碼檢字法歧義太多(易錯)以及五筆字型難學(無律)的缺點,嚴格執行國家頒佈的統一筆順規範,突破了漢字自有字典以來一直沿用的以“囗(方框)”為代表的部首檢字法傳統人為框框的限制(例如,將“國”字的前兩筆跟最後一筆按寫字順序分開成“冂、一”兩個字根處理),提練出了“順序按筆畫,簡單讓複雜,數量要最少,儘量不交叉”這個“將漢字拆分為字根”的規則。由於規則簡單,邏輯性強,沒有歧義性,因此奠定了高效拆分漢字的基礎。
實質上,字根數碼檢字法是綜合利用了阿拉伯數字排列簡單,漢語“一字一音”的簡捷,計算機標準鍵盤佈局的通用性,依靠筆順規範並儘可能快地拆分字塊,採用數字代碼進行縮編的方法,簡便地將漢字數字化,從而結束漢字長期以來無法進行有效排序的歷史。
如果以字根數碼檢字法為主,按字根數碼的順序來編像《新華字典》一樣近萬字的字典,依編碼從1000排到9999,都能井然有序。由於學熟後見到漢字便能快速讀出數碼,且重碼字同碼量比較小,查漢字翻頁基本上是一次到位,原來字典上的檢字表都不用要。與拼音文字比較,查漢字將由世界上最困難的查法變成最簡單的查法。例如,查“書”字,字根數碼是5524,由於0不代表字根,這裏每編一個數碼只是從9箇中挑一個。而查英文“書”的單詞“book”,每次找一個字母要從26箇中找一個,況且常用單詞的字母數平均在7個以上,查找時間自然比較長。
如果學熟了字根數碼檢字法,查一個字只需幾秒鐘,如此這般,只有漢字這種形義文字才做得到。
過去我國大多數成年人不習慣於經常查字典是有原因的。一是根據形義文字的形態,很多字都能猜出幾分意思,例如:囿;二是根據詞中前後字或文中上下文的內容,能夠琢磨出幾分意思,例如:淺嘗輒止。三是以往的查字方法的確比較麻煩,每個人又都有不同程度的墮性,因而很多人是得過且過。
綜上所述,僅從快速查字典這個方面來看,形義文字也頗具神奇魅力,只是以前沒有發現和推廣開來而已。其實,字根數碼檢字法只是突破了一個傳統的框框“囗”,就能讓大眾見到漢字應用的一片新天地。
下圖是字根數碼檢字法簡表,這裏字根沒有嵌入。
十二、漢字快速輸入
在機械打字年代,漢字一直落後於線性文字。進入電子信息時代以後,上世紀八十年代前曾出現危機,後來漢字輸入效率逐漸趕了上來,並且完成了超越,今天甚至到了意音文字望塵莫及的程度。
從編碼角度來説,結構複雜的漢字,藴藏着奇高的離散性優勢,這從上述字根數碼檢字法中就可以看出端倪,四個數字代表一個字,編近萬字的字典,理論上9X9X9X9只有6561個不同的編碼,但重碼度居然不高。
如果用字母代表字根編碼,僅用標準鍵盤上25個英文字母編四碼,25X25X25X25就有390625個不同的字母編碼。由於位置數量有39萬多個,單字、詞彙、常用短句甚至精典長句都可以混編,編十幾萬個常用字、詞、句的編碼,重碼率仍然不高,敲四碼90%以上都會自動上屏。這是華夏輸入法的優勢。
這裏以精典的“中國共產黨黨員入黨誓詞”為例,其對應的編碼為:我志願加入中國共產黨——TFDI,擁護黨的綱領——RRIW,遵守黨的章程——UPIT,執行——RVTF黨的決定——IRUP,嚴守黨的紀律——GPIT,保守黨的秘密——WPIP,對黨忠誠——CIKY,積極工作——TSAW,為共產主義奮鬥終身——YAUT,隨時準備為黨和人民犧牲一切——BJUA,永不叛黨——YGUI。顯然,這12句子中,只有“執行黨的決定”是分兩次輸入(如果編成一次輸入會與“手掌”一詞重碼)。僅由此例就可以大致看出,利用漢字形碼方法來輸入常用詞和精典句子,自動上屏的效率非常高。
上一節説過,非字根字的拆字規則“順序按筆畫,簡單讓複雜,數量要最少,儘量不交叉。”以及字根字“按筆畫順序拆成單筆畫字根”的拆字規則,能夠鎖定所有現代漢字的拆字結果,如果另外按照比數字編碼稍微複雜一點的規則,用字母代表字根就能編定十幾萬個不同的字詞句編碼。如果適當人為控制一點編碼的雷同率,數據可以進一步擴大,數十萬個經典詞句都可以入列,如果相關軟件用熟了,打字真可謂“快如飛”。例如,“十九大報告是”“我們黨團結帶領全國各族人民在新時代堅持和發展中國特色社會主義的政治宣言和行動綱領”,這樣的一個長句,只用FVDJ和TWIW兩組編碼就能自動上屏,後40個字用4個字母就能代表。再如,中國共產黨——KMAI,第十九次全國代表大會——TFVW,大會的主題是——DWRJ,不忘初心——GYPN,牢記使命——PYWW,高舉中國特色社會主義偉大旗幟——YIKM,決勝全面建成小康社會——UEWW,奪取新時代中國特色社會主義偉大勝利——DBUT,為實現中華民族偉大復興的中國夢不懈奮鬥——YPGU。這9句共89個字,敲9個回合4X9共36下,都能自動上屏,都沒有其它重碼。
限於篇幅,這裏僅簡單介紹詞彙和長句子的編碼規則。
總的來説,詞彙的編碼方法是:在單字編碼的基礎上湊四碼。簡言之:打詞彙,湊四碼。
(一)二字詞:各字前兩碼。
二字詞的輸入,取二字各自的前兩個編碼。例如,“兩個”的編碼是GMWH,其中“兩”字湊的是“GM”,“個”字湊的是“WH”。又如,“理想”的編碼是GLSH。
(二)三字詞:前兩字第一碼,尾字前兩碼。
三個字的詞彙,取前二字各自的第一個編碼和最後一字的前兩個編碼。例如,“互聯網”的編碼是GBMQ。又如,“計算機”的編碼是YTSM。
(三)四字詞:各字第一碼。
四個字的詞彙,取各字的第一個編碼。例如,“勇往直前”的編碼是CTFU。又如,“繼往開來”的編碼是XTGG。
(四)五字句:前三字第一碼,尾字第一碼。
五個字及以上的句子,取前三字和最後一字各自的第一個編碼。例如,“不到長城非好漢”的編碼是GGTI。又如,“為實現中華民族偉大復興的中國夢不懈奮鬥”的編碼是YPGU。如果分開輸入“實現中華民族偉大復興”PGKI,“中國夢”KMSS,“不懈奮鬥”GNDU,也都能自動上屏。
另外,打漢字的單字,也可以做到非常高效。
字根字的第一個編碼應該安排為字根所在位置的字母,非字根字的第一個編碼是第一個字根的編碼,根據現代漢字的使用頻率,可以將常用字由高到低設置隊列,只要敲字的第一個編碼,屏幕上就會對應出現十個常用的漢字可供挑選。例如敲G是“一不來到下天事於進兩”,又如敲X是“經比級結給線組強統母”。如此操作,一鍵可選的漢字一共是250個,簡稱一鍵碼,這裏面可以包含最常用的200個漢字。
如果連續敲字的前兩個編碼,屏幕上會出現25X25共計625列可供選擇的6250行字(有的行沒有相對應的單字,詞或句會自動補位),這裏面基本上包含了常用的3千多個漢字,簡稱二鍵碼。換句話説,用這種方法,只要敲兩鍵,常用漢字基本上都會出現在屏幕上。
以上方法也能應用在手機上,只不過每次顯示的字數要少四五個而已,但人們日常在手機上使用的一些字,往往使用頻率非常高,再輔以聯想功能則更加方便。
十三、自信向未來
人在嬰兒階段,感覺到餓、渴、脹、冷、熱、閉、痛、困,通過嘴動、眼動、頭動、四肢動以至於哭叫反映出來,滿足於吃、喝、拉、撒、睡,抗拒於不從,這些都是人腦中還沒有語言功能的簡單觀念或概念在起作用。
嬰幼兒階段,各自在不同的環境中,主要依靠視覺和聽覺,不斷地感知、理解外界的信息,頭腦中慢慢形成很多不同的概念,尤其是語言概念,直至能跟外界進行簡單的交流。
從解剖學上講,人在一歲以後,當喉下降到嗓子裏,才能清楚地發出大多數的人類聲音,之前即使允許説話的神經通道存在,但是缺少相配套的身體器官[33]。人到兩歲以後,語言會出現一個爆發階段,語言能力和理解能力往往有顯著提高。
人識字以後才有文字之類的概念。對於不識字的人來説,與別人交流主要是靠語言概念。實際上,在人的大腦最深處,依然保留着古老的爬行腦,它的功能跟一般的動物沒什麼兩樣,它控制着主體的日常大部分行為,而且還沒有使用語言功能。這是每個人都容易體會、驗證的,有人稱其為主要是無意識的直覺。
前文提到過,在人類的視覺、聽覺、觸覺、嗅覺、味覺、痛覺等六種主要感覺中,視覺的功能最強大,健康人接受信息主要靠視覺。而概念和概念加工是人類頭腦中古老而又永恆的東西。
人類大腦處理視覺圖像信息的能力也遠遠超出聽覺信息。比如,當有人問你上頓飯吃了些什麼東西的時候,人的腦海中首先浮現的是食物的圖像,然後才轉換成語言或文字來回應。
人們想問題都是概念先行,初始既不是文字,更不是語音。在概念不清時,思想觀念處於遊移狀態,思考的過程,實際上就是找尋合適概念的過程,而且,無論説或者寫,之前的狀態都是如此。
中文充分利用了人類信息加工能力最強的視覺系統。漢字不重表音,擺脱了一維線性和表音基本單元數目有限這兩項根本缺陷的束縛,可以充分發揮人類視覺的圖形識別能力[34],從而海量創造新概念,維護好清晰概念。不難想象,如果讓漢字消失,純粹以音表意,且不説割斷了歷史,現代漢語立即就會變得模糊以至混沌,比如説“真愛”與“珍愛”就會大打折扣;尤其是難以自由創造新概念,即使遇到外來新概念也只能將就着挪用,就像囫圇吞棗一樣消化吸收不了核心內容,未來必然是負重難行,逐漸走向新概念深淵。
五四時期,中國知識分子在尋求自強道路時,曾一度認為漢字是文化落後的主要原因,很多名人説過一些過激的話,不少學者還進行過許多漢字拼音化的嘗試,但都沒有成功。新中國成立後,實施了推廣普通話、簡化漢字、採用漢語拼音方案三大語言文字改革,取得了舉世矚目的偉大成就。隨着改革開放中國的快速崛起,漢文化憑藉其深厚的底藴影響越來越大,漢語漢字是否落後的真像逐漸清楚地擺在全世界關注者的眼前。
語言文字作為文化的主要載體和重要組成部分,在很大程度上,塑造着一個民族或者國家的影響力。文化自信,不需要避諱什麼,坦蕩才是王道。漢字文化的自信,關鍵在於抓住自己的本源,本立則道生,源清則流廣。
漢字的本體是筆畫,單字、詞彙、成語的概念都發端於筆畫的建構。筆畫的形式近現代不再有大的變化,但持續構成新概念永遠是漢字文化創新的源頭和優勢。
源頭清晰,源遠流長,海納百川,我們有理由自信。
(一)漢字的單音節魅力無窮。這裏僅舉一例,比如,用漢語背誦45句乘法口訣,總共只有200個音節,較之其他文字要少很多,應用自然也快得多。這也説明,中文的表達可以做到特別簡潔。
(二)中文組詞非常方便。兩字詞可以信手拈來,比如:只要手巴掌一伸,就可以直接數。手指,指尖,指背,指肚,指側,指節;五指,拇指,食指,中指,無名指,小指。又如,漢語可以隨便説:“一節,一截,一段,一格,……”,對此,英語怎麼説呢?a piece,a part of,a chop of?反正你不容易琢磨出來。
(三)中文造詞能夠特別精製。比如,“抬槓”一詞的意思一般是指爭辯,並且多指無謂的爭辯。英語需譯為to argue ofr the sake of arguing或to argue ofr no reason at all。“槓精”的意思是“愛抬槓的人”。英語需譯為a stubbornly argumentative person [35]。其實,作為動詞,“抬槓”的本義是“指綁槓子抬運靈柩”,俗稱“抬棺材”,幹此事時,場境中免不了眾人七嘴八舌廢話多。濃縮為“抬槓”,一是比“抬棺材”三字簡潔,二是避諱“棺材”二字。可見中文造詞不僅需要智慧,甚至需要達到幽默的程度。
(四)中文描述事物的精確度高。比如:塞進去,插進去,放進去,丟進去,扔進去,投進去,拋進去,推進去,打進去……,遣詞造句能細化到非常微妙的程度。
(五)形義文字更適合於快速閲讀。
1、漢字由筆畫構成,形式緊湊便於整體認知。
2、漢字構詞能力強,常用字集中。
3、漢字作為形義文字,同音異義的字差別明顯。
4、多數漢字形義互見,為快速閲讀提供了基本條件。
5、漢字需要復腦認讀,能充分發揮大腦兩半球的功能。
事實上,一般情況下我們看中文書,經常是瀏覽,而不是閲讀,習慣用眼睛掃,一目幾行,由於主要目的是分辨形義,音的參與程度一般很弱,因而效率高[36]。當然,精讀章句則是另外一回事。
(六)學中文先難後易。最開始認識漢字,要求必須記住字的形態、筆畫、聲音,如果沒有形成習慣,確實有一些麻煩,但久而久之,對一些常見的形體沒有必要再去特別地琢磨,形義一體會成為一種覺悟,這裏的覺悟高低就是已經掌握了的字詞水平程度。當義務教育完成後,後發優勢就開始顯現,普通人入門一個很專業的學科都不會有太大的障礙,各個學科的專業詞彙都不難掌握。中文理解新詞一般比認識別新字還要容易一些,因為新詞一般都是由常用字構成的。比如“長方體”,中國的百姓都知道是什麼意思,但在音意文字裏卻是一個一般人都不會説的生僻詞彙。
學習中文,造詞造句是每個人從小就應該練好的基本功,能夠熟練掌握、不斷提高表達功夫,達到精確闡述自己的觀點,精到講述精彩的故事,是各行各業人們畢生的追求,功到自然成。當然,如果沒有自覺,就會怨天尤人。
總之,就憑形義文字現有的優勢,加之其基本沒有過多的繁文縟節式規則,基本沒有出現過閲讀障礙現象,沒有束縛,就像漢語言文字給了我們靈活而又健壯的翅膀一樣,讓所有追夢人都能夠在廣闊的空間裏自由飛翔,因而所有掌握者都應當自豪。
五四運動倡導白話文至今不過百年時間,在語言文字發展的歷史長河中,時間很短,但近代的變革使漢字文化更加生機蓬勃。面對未來,使用者不能因循守舊固步自封,應該不斷地大量創造、吸收新詞新語,儘量用漢語敍述和解釋世界,漢字的潛能會越來越充分地顯現出來,我們應該自信,作為世界上唯一的形義文字,創造和承載文明的底氣十足,即使世界上的各種知識再怎麼樣爆炸性地增長,漢字永遠會與時俱進、兼收幷蓄而從容以對。
參考文獻:
[1]張學新.漢字拼義理論:心理學對漢字本質的新定性[J].華南師範大學學報(社科版),2011,4:5-13.
[2]張學新,方卓,杜英春,孔令躍,張欽,邢強.頂中區N200:一箇中文視覺詞彙識別特有的腦電反應[J].科學通報,2012,57(5):332-347.
[3]藍色暢想.世界上最古老的文字是蘇美爾人楔形文字.快資訊:文字知識.2017-07-19.
[4]教育部 國家語委.GB13000.1字符集漢字折筆規範.語言文字規範:GF2001-2001,2001-12-19.
[5]100FT.北大中文論壇-輸入法討論專區,下載LOFTER客户端.2009-12-04.
[6]用户1914608307.中國漢字不要翻譯為單詞.快資訊.2019/4/15.
[7]徐中舒.甲骨文字典——甲骨文漢字對應表.四川辭書出版社.1993出版.
[8]張學新. 漢字拼義理論:心理學對漢字本質的新定性[J].華南師範大學學報(社科版),2011,4:5-13.
[9]甲骨文金文字數,來源於360百科。
[10]漢字歷代數量,來源於360百科。
[11]張學新. 漢字拼義理論:心理學對漢字本質的新定性[J].華南師範大學學報(社科版),2011,4:5-13.
[12]徐中舒.甲骨文字典——甲骨文漢字對應表.四川辭書出版社.1993.
[13]許慎.説文解字——九上司部.中國書店出版社.
1989.1.
[14]文揚.中國歷史上的政商關係之謎——70年對話5000年(6).觀察者網:2019-03-31.
[15]李仕春.從複音數據看中古漢語構詞法的發展.寧夏大學學報:人文社會科學版,2007(1)(3).
[16]張學新. 漢字拼義理論:心理學對漢字本質的新定性[J].華南師範大學學報(社科版),2011,4:5-13.
[17]李仕春.從複音數據看中古漢語構詞法的發展.寧夏大學學報:人文社會科學版,2007(1).
[18]https://www.zhihu.com/question/24287002/answer/27332102懦夫卡蹲者.2014-11-22.
[19]陳力衞.語詞的漂移——近代以來中日之間的知識互動與共有.來源:觀察者網.2018-10-29.
[20]陳力衞.語詞的漂移——近代以來中日之間的知識互動與共有.來源:觀察者網.2018-10-29.
[21]張學新. 漢字拼義理論:心理學對漢字本質的新定性[J].華南師範大學學報(社科版),2011,4:5-13.
[22]張學新. 漢字拼義理論:心理學對漢字本質的新定性[J].華南師範大學學報(社科版),2011,4:5-13.
[23]張學新. 漢字拼義理論:心理學對漢字本質的新定性[J].華南師範大學學報(社科版),2011,4:5-13.
[24] 周勇翔,周聰,周宏.現代漢語同音詞詞典.北京:商務印書館,2009.
[25]張學新. 漢字拼義理論:心理學對漢字本質的新定性[J].華南師範大學學報(社科版),2011,4:5-13.
[26]劉潔修.成語.北京:商務印書館,1985-6.本文P44
[27]劉潔修.成語.北京:商務印書館,1985-6.
[28]陳德彰.雙語加油站—流量明星.環球時報:2019-04-09(13).
[29]張學新,方卓,杜英春,孔令躍,張欽,邢強.頂中區N200:一箇中文視覺詞彙識別特有的腦電反應[J].科學通報,2012,57(5):332-347.
[30]張學新,方卓,杜英春,孔令躍,張欽,邢強.頂中區N200:一箇中文視覺詞彙識別特有的腦電反應[J].科學通報,2012,57(5):332-347.
[31]張欽,丁錦紅,郭春彥. 名詞與動詞加工的 ERP 差異﹒心理學報,2003,35:753–760.
[32]張學新. 漢字拼義理論:心理學對漢字本質的新定性[J].華南師範大學學報(社科版),2011,4:5-13.
[33][新西蘭]費希爾(Fisch,S.R.).語言的歷史.崔存明,胡紅偉譯北京:中央編譯出版社,2012,3:23.
[34]張學新. 漢字拼義理論:心理學對漢字本質的新定性[J].華南師範大學學報(社科版),2011,4:5-13.
[35]王逄鑫. 雙語加油站——槓精.環球時報:2019-1-8(13).
[36]李零.誰是倉頡——關於漢字起源問題的討論——我手不寫我口.愛思想網.2019-01-19.
致謝:感謝王建明研究員、陶宏開教授、特別是張學新教授的指導和鼓勵。