存內計算能否成為下一代AI芯片的關鍵_風聞
半导体行业观察-半导体行业观察官方账号-专注观察全球半导体最新资讯、技术前沿、发展趋势。2019-12-23 14:11
隨着人工智能的落地和大規模應用,AI芯片也成為了常見的芯片品類。AI芯片相比傳統芯片來説,主要的競爭優勢就在於高算力和高能效比。高算力是指能夠比傳統芯片更快地完成AI計算,而高能效比則是指能比傳統芯片用更少的能量完成計算。
在AI芯片誕生的初期,AI芯片架構主要是針對計算並行性做優化,從而加強計算能力。然而,隨着AI芯片競爭日益激烈,從並行性方面的潛力也已經被挖掘殆盡,這時候AI芯片的性能就遇到了“內存牆”這一瓶頸。
要理解內存牆,還需要從傳統的馮諾伊曼架構説起。馮諾伊曼架構是計算機的經典體系結構,同時也是之前處理器芯片的主流架構。在馮諾伊曼架構中,計算與內存是分離的單元:計算單元根據從內存中讀取數據,計算完成後存回內存。
內存牆對於處理器的限制是多方面的,不僅僅是限制了其計算性能,同時也是能效比的瓶頸 。在AI芯片追求極致計算能效比的今天,內存牆對於AI芯片能效比的限制效應尤其顯著。眾所周知,人工智能中神經網絡模型的一個重要特點就是計算量大,而且計算過程中涉及到的數據量也很大,使用傳統馮諾伊曼架構會需要頻繁讀寫內存。目前的DRAM一次讀寫32bit數據消耗的能量比起32bit數據計算消耗的能量要大兩到三個數量級,因此成為了總體計算設備中的能效比瓶頸。如果想讓人工智能應用也走入對於能效比有嚴格要求的移動端和嵌入式設備以實現“人工智能無處不在”,那麼內存訪問瓶頸就是一個不得不解決的問題。
存內計算:翻越內存牆
內存牆之所以存在,從另一個角度看主要還是由於處理器/加速器芯片和主內存是兩個獨立的模塊,或者換句話説,計算和內存之間距離太遠,因此來回搬運數據代價太高,無論是吞吐量還是能效比方面這種數據搬運都成為了瓶頸。那麼,如何讓內存和計算離得更近一些呢?一個最簡單有效的方法就是“存內計算”(in-memory computing)。
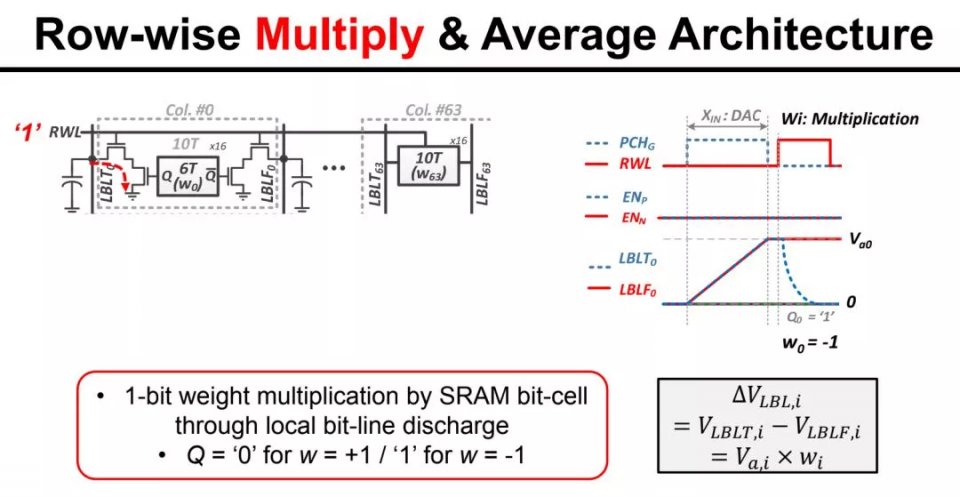
存內計算,顧名思義就是直接在存儲內做計算。其具體實現方式有若干條技術路徑。首先,最直接的就是在現有存儲的基礎上做一些電路上的改動。這類實現方法最簡單,例如2018年MIT Chandrakasan研究組在ISSCC上發表的研究就是這類技術的例子。該研究中,存內計算的主要用途是加速卷積計算,而卷積計算從數學上可以展開成帶權重的累加計算,或者説是多個數的加權平均。因此,存內計算的做法是把權重(1-bit)儲存在SRAM中,輸入數據經過DAC成為模擬信號,並根據SRAM中的對應權重相乘,然後在模擬域做平均,最後由ADC讀出成為數字信號。這類存內計算往往只是修改現有存儲的譯碼器/放大器模塊,並不涉及存儲器件的重新設計,優勢是比較容易和現有工藝集成,但是缺點是能夠帶來的性能提升較為有限,尤其是基於SRAM的方案,一方面SRAM的集成度是有限的,另一方面單比特精度的權重也成為了其應用的限制。
近年來,存內計算已經逐漸成為業界和學界公認的趨勢。拿半導體集成電路領域的“奧林匹克”——ISSCC為例,從2018年開始ISSCC開始設立與存內計算相關的專門session並收錄五篇相關論文,此後存內計算在ISSCC上的相關論文錄用勢頭一直不減,到2020年的ISSCC與存內計算相關的論文數量上升到了七篇。除此之外,半導體器件領域的頂級會議IEDM今年也給了存內計算足夠重視,有三個專門的session共二十多篇相關論文。有趣的是,ISSCC和IEDM上相關存內計算的論文正好對應了前文所説的存內計算的兩種技術路線——ISSCC對應從電路側做技術革新,而IEDM則主要對應器件方向的技術更新換代,通過引入新的存儲器件並基於其新特性來開發高性能的存內計算。其中,IEDM中顯示的範式轉換更引人關注。今年,IEDM的一大看點就是對於摩爾定律到頭之後下一步方向的預測,有一個專門的panel session更是直接以“摩爾定律已死,但是AI永生”為名字,可見業界對於後摩爾定律時代的發展,最看好的是基於AI的新器件。而在AI相關的新器件/新範式中,存內計算可謂是最有希望的一種,由此可見今年IEDM的關於後摩爾定律的主題和錄用數十篇存內計算相關的論文之間存在着緊密的聯繫。
目前,全球存內計算有不少玩家。例如,半導體巨頭TSMC正在推廣其基於ReRAM的存內計算方案,而IBM基於其獨特的相變存儲的存內計算也已經有了數年的歷史。初創公司中,Mythic基於Flash的方案也獲得了軟銀的首肯並獲取了其資金支持。然而,傳統存內計算有一個主要問題,就是計算精度和應用場景之間的矛盾。ReRAM通常只能做到2至3-bit,這即使對於終端用的神經網絡來説也不太夠。Mythic的產品針對服務器市場,然而服務器市場對於計算精度的要求卻相比終端更高,這也成為了困擾存內計算的一個問題。
IEDM上的來自中國的論文可能成為解決存內計算瓶頸的關鍵
如上文所述,存內計算的一個關鍵瓶頸是精度和應用之間的矛盾。如果要解決這個矛盾,我們希望能有一款針對移動端的低功耗存內計算產品,且其計算精度能達到移動端神經網絡的計算需求(>4bit)。
在今年的IEDM上,我們就看到了這樣的技術突破。一家初創公司閃億半導體,與浙江大學、北京大學、華虹宏力合作發表的論文《Programmable Linear RAM: A New Flash Memory-based Memristor for Artificial Synapses and Its Application to Speech Recognition System》恰恰解決了這個矛盾。該論文巧妙地利用晶體管在線性區的特性製備了新型存儲器PLRAM,併成功地設計出了一款可以用在移動終端的超低功耗存內計算芯片,並實現了8-bit精度操作。


該研究讓我們看到了中國半導體行業的崛起,因為在IEDM這樣強手如林的頂尖半導體器件會議上發表文章本身就是對相關技術的肯定。更可喜的是,該研究已經在閃億進行商業化,我們認為閃億擁有的技術首先能克服存內計算的計算精度和應用場景之間的矛盾,可以把存內計算低功耗的優勢發揮到極致,而同時其高精度計算又保證了可以兼容大多數神經網絡。同時,閃億選擇的IoT和可穿戴式市場也是一個正在蓬勃發展的市場,這些市場非常適合用全球領先的新技術去撬動新的應用,從而讓存內計算真正落地走向千家萬户。我們希望能看到更多像閃億這樣的高精尖半導體技術商業化的案例,而當市場上出現眾多這樣的充滿活力的高新技術半導體公司時,中國半導體的春天也就到了。