騰訊優圖提出半監督對抗單目深度估計
【環球網科技綜合報道】8月6日消息,記者從騰訊方面獲悉,騰訊優圖實驗室團隊在單目深度估計上取得了新的研究進展。
騰訊優圖與廈門大學聯合團隊,共同提出了半監督對抗單目深度估計,有望充分利用海量的無標籤數據所藴含的信息,結合少量有標籤數據以半監督的形式對網絡進行訓練。據悉,該研究成果已被人工智能領域最頂級的國際期刊TPAMI收錄。
長期以來,基於深度卷積神經網絡的分類、迴歸任務大多依賴大量的有標籤數據來對網絡進行訓練。而在實際的算法部署中,往往只有海量的無標籤數據以及非常少量的標籤數據。如何充分利用這些少量的標籤數據,使其達到和大量有標籤數據下訓練的模型相近的效果,對學術界和工業界來説一直都是一個難題。
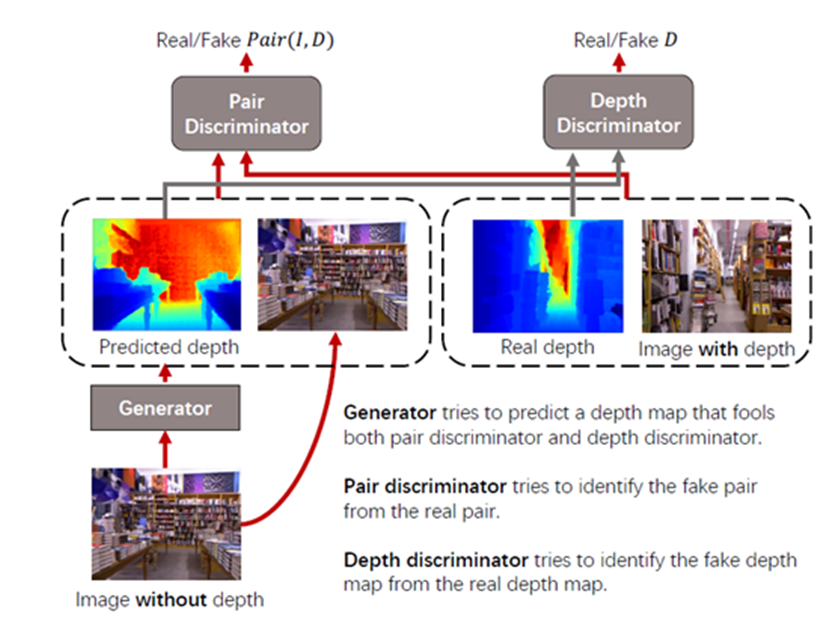
據騰訊優圖的研究員介紹,該項研究的核心難點在於,如何從無標籤數據中獲取監督信息。傳統方法一般需要同一場景的圖像序列作為輸入,通過構建立體幾何關係來隱式地對深度進行重建。這種方法要求同一場景至少包含兩張以上的圖像,一般需要雙目攝像頭或視頻序列才可以滿足。騰訊優圖與廈門大學聯合團隊,提出在一個對抗訓練的框架中,解除圖像對判別器對真假樣本必須為同一圖像的要求,“真樣本對”採用有標籤數據的RGB圖像以及對應的真實深度圖,“偽樣本對”採用無標籤RGB圖像以及用生成器網絡預測出的深度圖,由判別器網絡區分預測出的深度圖與對應RGB直接是否符合真實的聯合概率分佈,進而從無標籤數據中收穫監督信息。與此同時,通過添加深度圖判別器,來約束預測的深度圖與真實深度圖的分佈一致性。該方法輸入可以為任意無關聯圖像,應用場景更加廣泛。而從實驗結果也發現,當主流的深度估計網絡作為一個生成器網絡安插在半監督框架中時,都可以收穫顯著的效果提升。
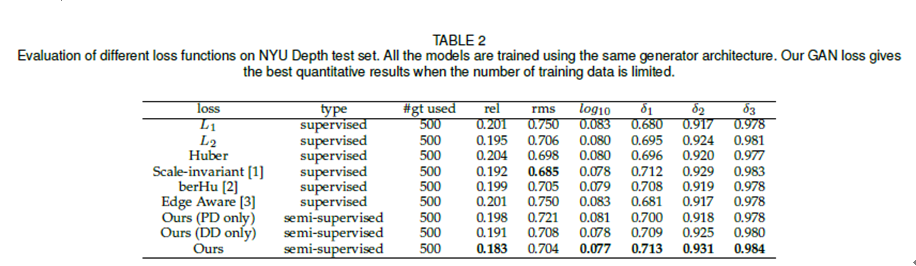
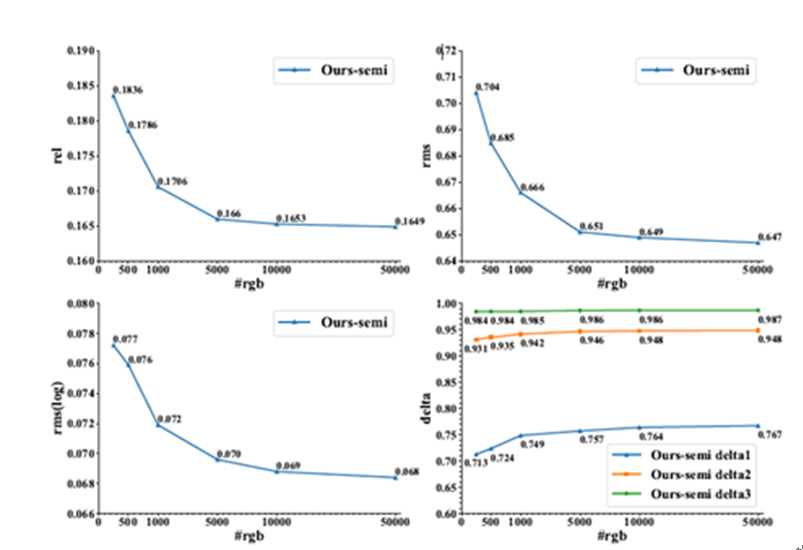
 在研究的量化指標上,利用半監督對抗框架,當有標籤數據很少(500張)的情況下,僅使用250張無標籤RGB圖像就可以收穫優於其他state-of-the-art方法的效果。當固定有標籤數據量(500張),持續增加無標籤RGB圖像可以進一步對效果帶來提升,最終當利用五萬張無標籤RGB圖像後,該方法在各項指標上都遠超當前的state-of-the-art方法。
在研究的量化指標上,利用半監督對抗框架,當有標籤數據很少(500張)的情況下,僅使用250張無標籤RGB圖像就可以收穫優於其他state-of-the-art方法的效果。當固定有標籤數據量(500張),持續增加無標籤RGB圖像可以進一步對效果帶來提升,最終當利用五萬張無標籤RGB圖像後,該方法在各項指標上都遠超當前的state-of-the-art方法。