ISSCC 2020:高速串口解析_風聞
半导体行业观察-半导体行业观察官方账号-专注观察全球半导体最新资讯、技术前沿、发展趋势。2020-02-28 09:59
來源:本文由公眾號半導體行業觀察(ID:icbank)授權轉載自公眾號【haikun01】 ,作者賈海昆,謝謝。

1、業界開始衝刺單通道112Gbps的高速串口;
2、這個方向非常吃先進工藝;
3、受工藝、成本限制,學術界沒有辦法跟工業界在同一層面競賽;
4、56Gbps的接口架構穩定,基於DSP的方案佔主導。
一年過去了,這些趨勢依然是成立的。
今年這個session有八篇論文。
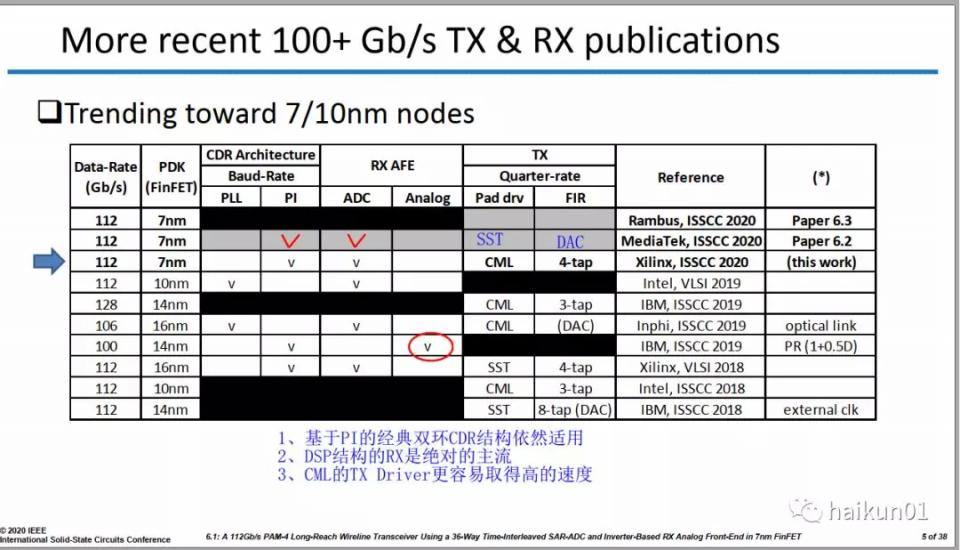
從分佈來看,五篇來自工業界、三篇來自學術界,學術界的論文可以説是另闢蹊徑,沒有在主流路線上競爭更高的速度。從工藝來看,三篇7nm、一篇10nm、一篇16nm,這五篇均來自於工業界,還有來自於學術界的兩篇40nm、一篇65nm。從速度來看,有三篇112Gbps,其中兩篇是完整的TRX,一篇是TX。去年的ISSCC還沒有達到112Gbps的RX,今年一下出來兩篇,都是Long Reach,再考慮到博通、Cadence、以及我前東家eTopus這些已經有112Gbps的產品或demo但沒有發表論文的公司,可以推測出工業界在這個方向的軍備競賽是多麼的激烈!
這次我們來看第一篇論文,來自Xilinx的112Gbps Long Reach PAM4 TRX。
1、TX設計
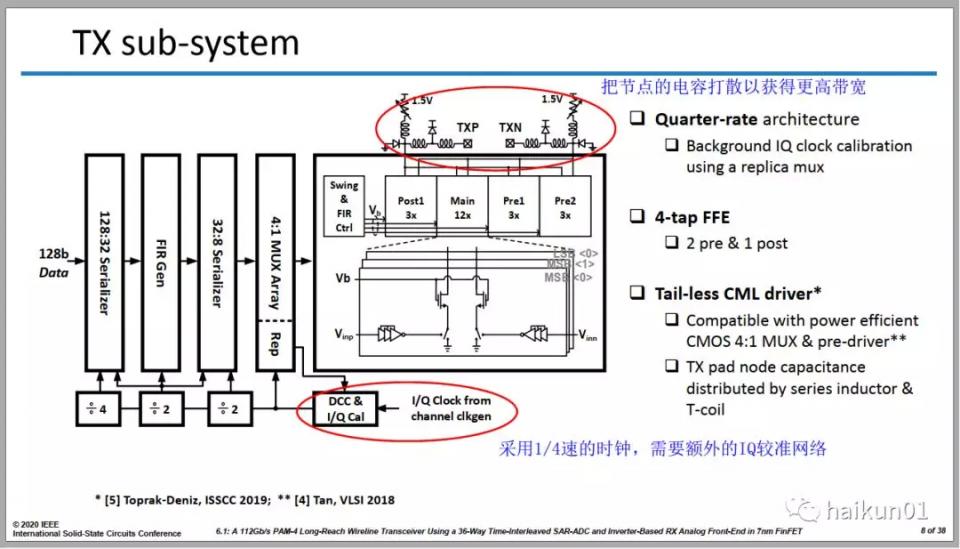
這一頁的另一個亮點是輸出匹配網絡,從56Gbps到112Gbps,對於輸出節點帶寬要求變大一倍。我在之前講寬帶匹配的文章裏提到過,**帶寬優化的一個思路是把寄生電容打散,用電感進行隔離。**這裏採用的就是這種思路,兩個diode之間用電感隔離開,獲得更高的帶寬。
2、RX設計
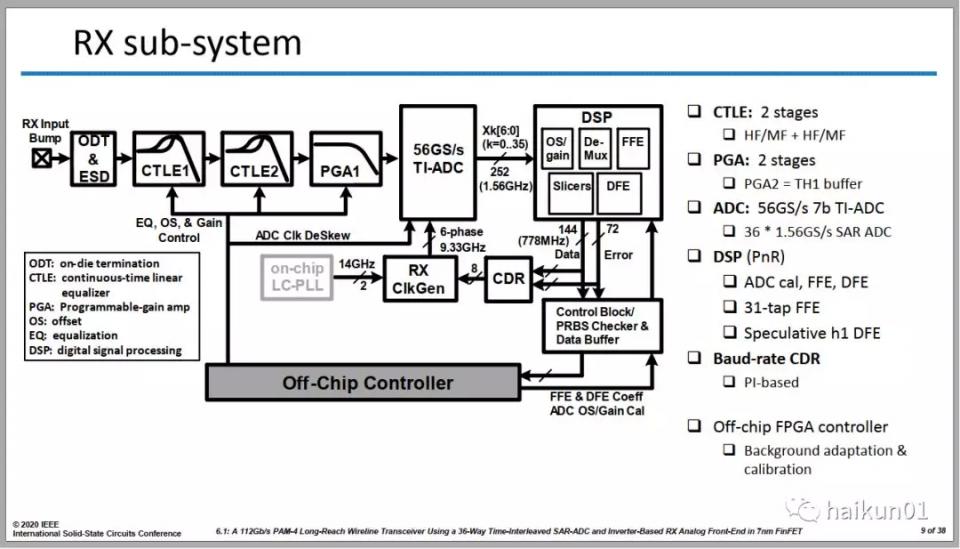
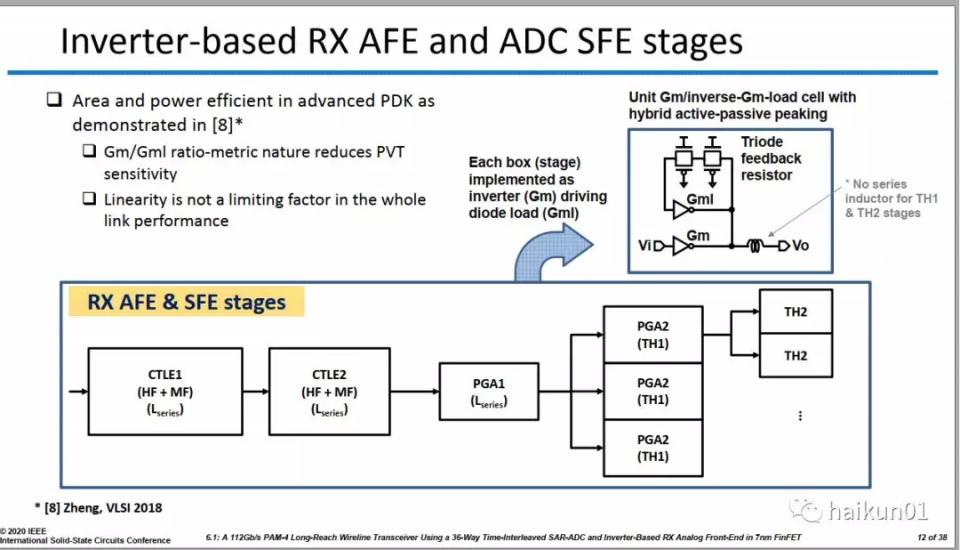
112Gbps的CTLE其實非常非常難做,不僅需要保證帶寬、可配的peaking強度,好需要保證一定的線性度。一般的CTLE都是線性放大器的設計,有為電流源、放大管、共模反饋等等,堆疊的晶體管多了,每個晶體管所佔的電壓空間變小,線性度變差。那怎麼辦呢?**我們要減少堆疊晶體管的數目,減少到最後不就變成了反相器麼?**那麼問題就來了:
**反相器怎麼去控制它的增益?**反相器本身的增益是極不穩定的。沒關係,我再給它加一個diode接法的反相器作為負載,這樣反相器的增益變成了兩個gm的比值,雖然不如電阻的比值,但也比較精確了。
**要怎麼去做peaking呢?**傳統的做法是在放大管源端做電容負反饋,但反相器的源端已經接地了,沒法在做負反饋。沒關係,我們可以在diode接法的反相器柵端加一個RC低通濾波,這樣也可以實現peaking,相當於active inductance,這種做法在去年的ISSCC也有用到過。
**怎麼實現peaking可配?**我可以改RC低通濾波的電容值或電阻值,從而改變等效active inductance的值,也就改了peaking的值了。
這樣一步步推理過來,全反相器的設計已經是成立的。而且一個額外的好處是,這種做法消除了電容和電阻,整個版圖會非常工整,這一點對於7nm這樣的先進工藝很重要,等到過DRC的時候自然會懂!
PPT中給出的測試結果,CTLE的性能很好,最大17.5dB的peaking,帶寬超過30GHz,而且仿真和測試結果之間只相差了不到0.5dB。這也仿的太準了!Amazing!根據前面的分析和這裏的測試結果,全反相器的RX前端在賬面上效果非常不錯,至於有沒有一些量產方面的坑,我沒有做過測過,不敢妄加評判。
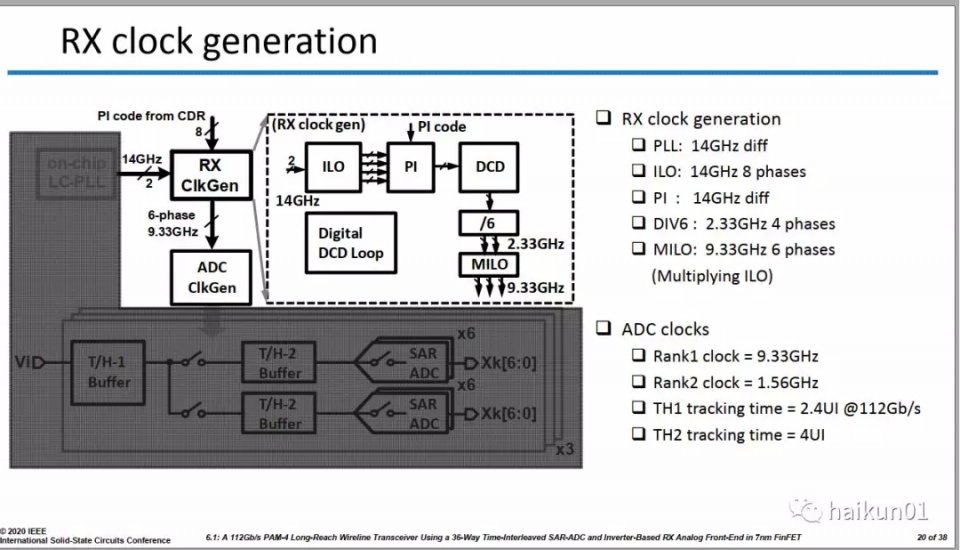
在基於DSP的RX設計中的一個關鍵點是插值結構的選擇。我在去年的總結裏提到:
從技術上來説,56G的高速接口架構已經較為穩定,主流選擇是:RX基於DSP,Time Interleaved ADC,一般先4到8的Track/Hold,每個Track/Hold帶若干個ADC的Slice,TX採用Half Rate。均衡方面差不多都是CTLE、1-TAP DFE、若干TAP的FIR,以及TX-FFE。那56G接下來的技術挑戰就是低功耗、以及更強大的Adaptive功能。對於112G的高速接口,我覺得現在大家追求的目標是先做出來再説,功耗什麼的留給以後再優化,在架構選擇上可以看到一些趨勢,但還沒有穩定下來。
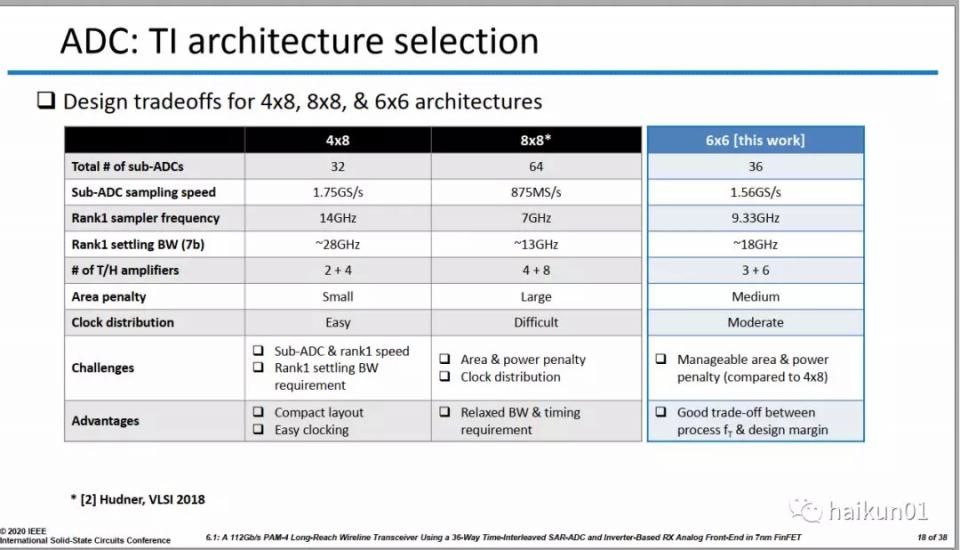
假如我們用16nm做了一個56 Gbps的RX,其中有四個Track Hold,每個帶8個ADC Slice。現在我們要用7nm去做112 Gbps的RX,應該選什麼結構呢?
**第一種做法是還是4x8的結構。**這樣每個ADC slice的速度需要提高一倍,而且Track Hold的帶寬也要提高一倍。**這樣相當於把速度壓力大部分都給了ADC。****從16nm到7nm,速度也就增長了30%左右,而這裏ADC的速度需要提高兩倍!**做起來不容易。
**第二種做法是選擇8x8的結構。**這樣每個ADC Slice的速度保持不變,但整體數目變多了一倍。Track Hold的數目也變多了一倍,對前一級的電容負載變大了不止一倍。想想不太合理,這種做法相當於把速度壓力全部都丟給前級,ADC一點兒也不分擔,儘管工藝速度變快了。
這篇論文裏給了第三種選擇,6x6的結構,這樣ADC和前級給自都分擔一點速度的壓力,似乎是一個更好的折中選擇。
3、總結
在這篇論文的分析裏,我無數次提到了系統架構的選擇,不是囉嗦,而是想傳達這樣一個觀點:系統架構的選擇至關重要。
相比起來,調一個具體的電路容易多了,你能很快的掃描參數,很快的看到結果,無非是誰掃描的更細心一點或更高效一點。在選擇系統架構的時候,這些電路都還沒有呢,性能怎麼樣也不知道,難度有多大也不知道,只能依據過往的一些經驗拍板。等實現到一大半發現結構選的不合適已經晚了,資源已經投入在裏面,想調頭非常不容易。而且架構選擇還不僅僅是技術,還要考慮公司已有的技術積累、承擔風險的能力、這款產品的定位、項目的工期等等商業和政治因素**。****因為試錯成本高,所以對經驗的要求非常高。**那怎麼才能快速增長經驗呢?無他,平常多思考多積累,多分析別人的工作,以及,多來看看我的文章。
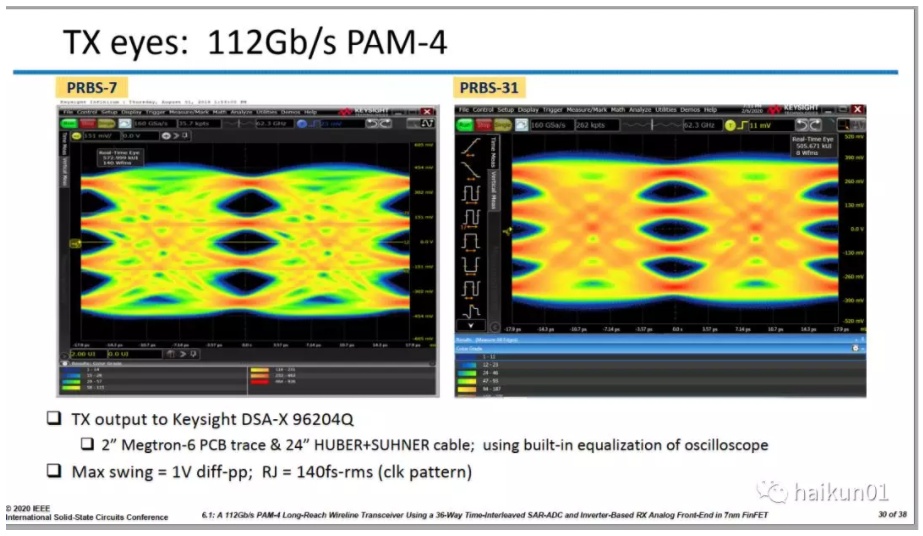
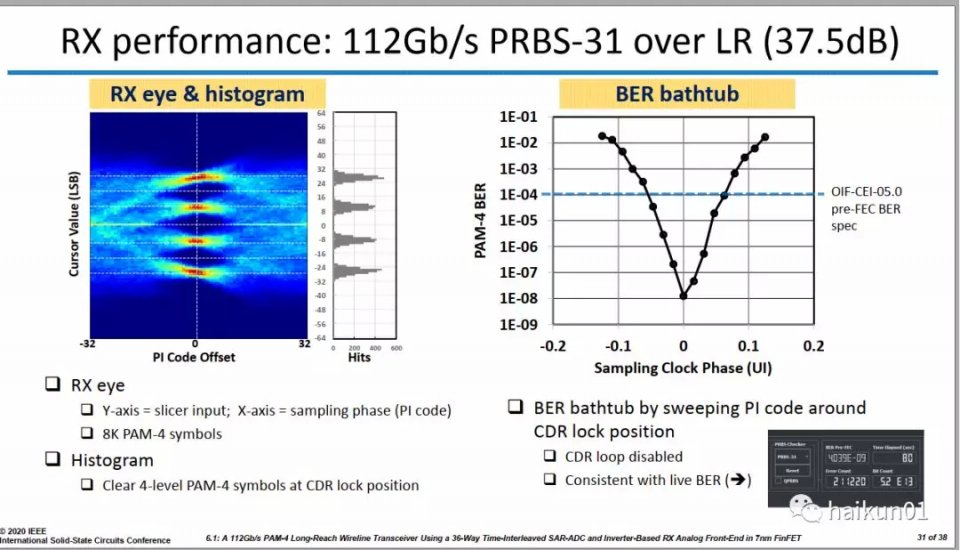
最後,我們再來看看這款芯片優秀的測試結果吧!
優秀的眼圖: