亞馬遜服務器芯片詳解,性價比吊打競爭對手_風聞
半导体行业观察-半导体行业观察官方账号-专注观察全球半导体最新资讯、技术前沿、发展趋势。2020-03-11 15:57
來源:內容由半導體行業觀察(ID:icbank)翻譯自「anandtech」,作者:Andrei Frumusanu,謝謝。
自亞馬遜發佈其第一代基於Graviton Arm的處理器內核以來已經一年半了,它在AWS EC2中作為所謂的“ A1”實例公開提供。儘管該處理器在性能上並沒有給人留下深刻的印象,但這釋放了他們未來幾年的信號和跨出了第一步。

亞馬遜為雲服務設計定製SoC的努力始於2015年,當時該公司收購了以色列的初創公司Annapurna Labs。Annapurna以前曾致力於以網絡為中心的Arm SoC,這些 SoC主要用於NAS設備等產品。在亞馬遜的領導下,該團隊的任務是創建定製的Arm服務器級芯片,而新的Graviton2是他們的首次重磅嘗試。
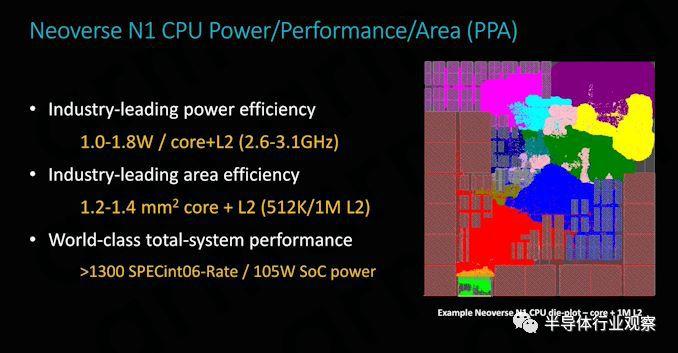
儘管我們能夠在雲端測試新芯片組,但該公司仍在為此其設計的某些方面的神秘。為此在我們的文章中,Amazon不太願意透露SoC的總功耗。Arm預計64核2.6GHz實施的功耗約為105W,以及Ampere最近披露的其80核3GHz N1服務器芯片的功耗為210W,考慮到該芯片的時鐘頻率更為保守,我們估計Graviton2必須在估計值低至80瓦之間,而悲觀的投影則介於110瓦之間。
使用EC2在雲中進行測試
鑑於Amazon的Graviton2是專門為滿足亞馬遜需求而設計的垂直集成產品,因此我們有必要在其預期的環境中測試新芯片組(除此之外,它還無法以其他任何方式使用!)。在過去的幾週中,我們已經獲得了對Amazon Web Services(AWS)彈性計算雲(EC2)新的基於Graviton2的“ m6g”實例的預覽訪問權限。
對於不熟悉雲計算的讀者來説,從本質上講,這意味着我們已經在Amazon的數據中心中部署了虛擬機,該服務以Amazon聞名於世,現在已佔該公司收入的主要份額,為一些最大的互聯網服務提供了動力。
決定此類實例功能的重要指標是其類型(本質上決定了底層硬件所採用的CPU體系結構和微體系結構)以及可能的子類型。在Amazon的情況下,這是指專門用於特殊用例的平台的變體,例如具有更好的計算功能或具有更高的內存容量功能。
在今天的測試中,我們可以訪問專為通用工作負載設計的“ m6g”實例。“6”的命名是代表亞馬遜第六代EC2硬件,帶有Graviton2的產品是目前唯一使用這個名稱的平台。
在vCPU中定義實例吞吐量
除了實例類型之外,定義實例功能的最重要的其他指標是其vCPU數量。“虛擬CPU”本質上是指虛擬機可用的邏輯CPU內核。亞馬遜提供的實例數量從1個vCPU到最多128個,在最受歡迎的平台中最常見的實例有2、4、8、16、32、48、64和96。
Graviton2是不帶SMT的單路64核平台,這意味着最大可用vCPU實例大小為64。
但是,這也意味着,在談論SMT附帶的平台時,我們在比較中有點像蘋果和橘子的難題。當談論64個vCPU實例(在EC2語言中為“ 16xlarge”)時,這意味着對於Graviton2實例,我們將獲得64個物理核心,而對於AMD或Intel系統,我們將僅獲得32個具有SMT的物理核心。我敢肯定會有一些讀者會考慮這種比較“不公平”,但是就交付吞吐量而言,這也是亞馬遜的定位,最重要的是,不同實例類型之間的等效定價。
今日比賽
今天的文章將重點介紹Graviton2的兩個主要競爭對手:AMD EPYC 7571(Zen1)驅動的m5a實例和Intel Xeon Platinum 8259CL(Cascade Lake)驅動的m5n實例。在撰寫本文時,這些是兩個x86現有人員可用的最強大的實例,並且應提供最有趣的比較數據。
需要注意的是,我們很希望能夠在此比較中包含基於AMD EPYC2 Rome(c5a / c5ad)的實例;亞馬遜宣佈他們去年11月一直在進行此類部署,但可惜該公司不願意與我們分享預覽訪問權限(給出的一個原因是Rome C型實例與Graviton2的M型相比不是一個很好的比較)實例,儘管這實際上沒有任何技術意義)。隨着這些實例越來越接近預覽可用性,我們將在另一篇文章中進行研究,以補充競爭格局中這一重要難題。
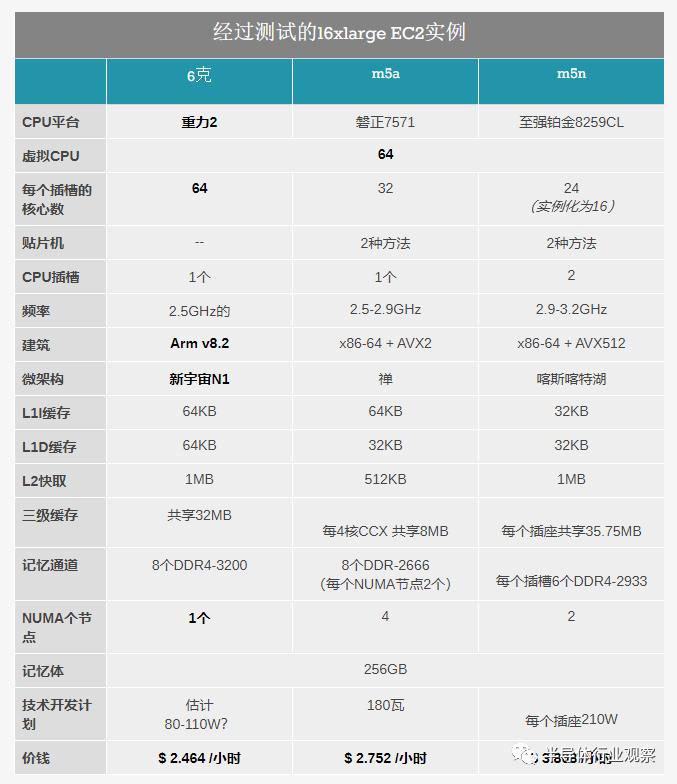
在談論更高vCPU數量的實例時,其他方面是您可以接收跨越多個套接字的VM。由於EPYC 7571有32個內核,所以AMD的m5a.16xlarge仍能夠在單個插槽上部署VM,但是英特爾的至強系統在這裏使用了兩個插槽,因為EC2中目前沒有部署英特爾的硬件,但它可以在一個插槽中提供所需的vCPU數量。
EPYC 7571和Xeon Platinum 8259CL都是未公開發售的零件,甚至都未在任何一家公司的SKU列表中列出,因此它們是Amazon等用於數據中心部署的自定義零件。
AMD部件是基於32核Zen1的單插槽解決方案(至少對於我們測試中的16xlarge實例而言),在輕線程環境中,時鐘頻率為2.5 GHz,最高可達2.9 GHz。該系統的特殊性在於它受到AMD的四芯片MCM系統的一定限制,該系統具有四個NUMA節點(每個芯片一個和2通道內存控制器),這一特性已在基於EPYC2 Zen2的較新系統中消除。我們沒有具體的數據確認,但我們懷疑這是根據SKU編號的180W部件。
英特爾至強鉑金8259CL基於較新的Cascade Lake世代CPU內核。此特定部分也特定於Amazon,每個插槽包含24個啓用的核心。為了達到16倍大的64個vCPU數量,EC2為我們提供了雙插槽系統,每個插槽上實例化了24個內核中的16個。同樣,我們對此事沒有任何確認,但這些部件的每個插座的額定功率應為210W,或總計420W。我們必須提醒自己,儘管我們確實可以訪問系統的全部內存帶寬和緩存,但在我們的實例中我們只使用了66%的系統內核。
這裏的緩存配置特別有趣,因為平台之間的情況相差很大。實際CPU本身的專用緩存相對來説是不言自明的,並且Graviton2在這三者中確實提供了最大的緩存容量,但在其他方面與Xeon平台相同。如果我們按線程劃分可用緩存,則Graviton2能做1.5MB,領先於EPYC的1.25MB和Xeon的1.05MB。Graviton2和Xeon系統具有明顯的優勢,即它們的最後一級緩存在整個插槽中共享,而AMD的L3僅在4核CCX模塊之間共享。
在具有實際多個進程的並行處理工作負載中,系統之間的NUMA差異並不重要,但是它將對多線程以及單線程性能產生影響,並且Graviton2的統一內存體系結構將在一些場景。
最後,實例之間的定價存在很大差異。Graviton2系統的價格為每小時2.46美元,在價格上領先於AMD系統,並且比基於Xeon實例的每小時3.80美元的價格便宜得多。儘管在談論價格時,我們必須記住,交付的實際價值也將極大地取決於系統的性能和吞吐量,我們將在本文的後面部分對此進行詳細介紹。
我們感謝亞馬遜為我們提供了對m6g Graviton2實例的預覽訪問。除了為我們提供訪問權限之外,Amazon或任何其他提及的公司都對我們的測試方法產生了影響,我們自己為EC2實例測試時間付費。
CPU芯片拓撲
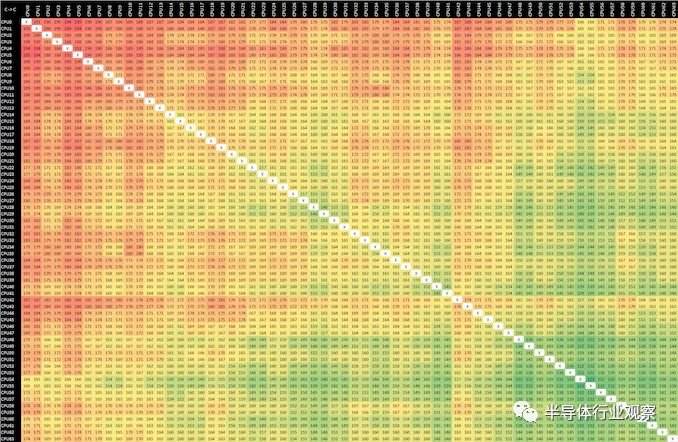
解釋了各種雲實例的硬件配置可能會發生很大變化,即使在紙上它們具有相同的交付“ vCPU”數量,將更多地關注CPU拓撲以及由此產生的方面(例如核心)將是很有趣的到核心的延遲。我對一些僵化或不準確的公共工具感到沮喪,最近我有時間編寫一個新的自定義微基準來測試CPU內核的同步延遲,展現一些緩存一致性以及當前設計的物理佈局。
下表是核心到核心的同步延遲(以納秒為單位)。
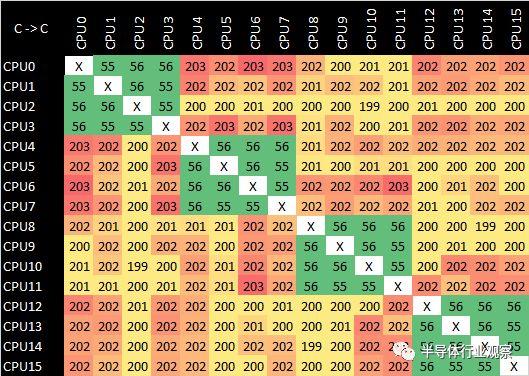
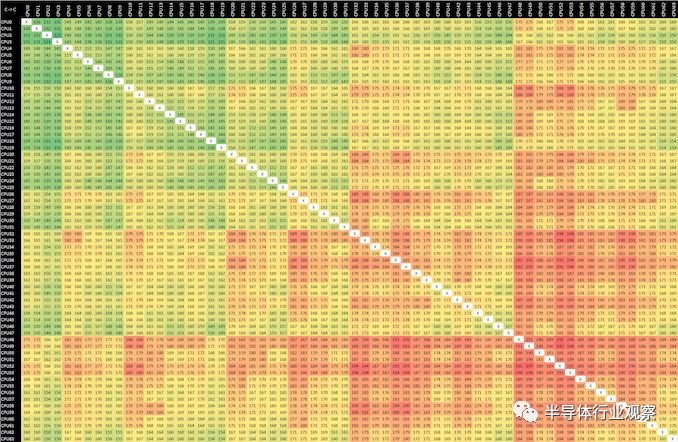
經過反覆試驗,我發現結果在各個運行過程中並不一致。更改CPU親和力確實會對結果產生更大的影響,直到我瞭解發生了什麼。
成本分析-x86大屠殺
Graviton2展示了它可以在性能和吞吐量方面保持極佳的表現,甚至在許多測試中都領先於競爭對手。但是,有時您不太在乎性能,而只是想以最便宜的方式完成一些工作負載,此時價值就發揮了作用。
亞馬遜確實暗示了這一點,並指出新芯片每美元的性能要比競爭對手高40%。如簡介中所述,對於64個vCPU數量為16倍的大型實例,m6g(Graviton2),m5a(EPYC1)和m5n(Xeon Cascade Lake)的每小時成本分別為2.464美元,2.752美元和3.080美元。
將完成各種SPEC測試所需的時間轉換為小時,然後乘以小時成本,最終得出了每個固定工作負載成本指標:
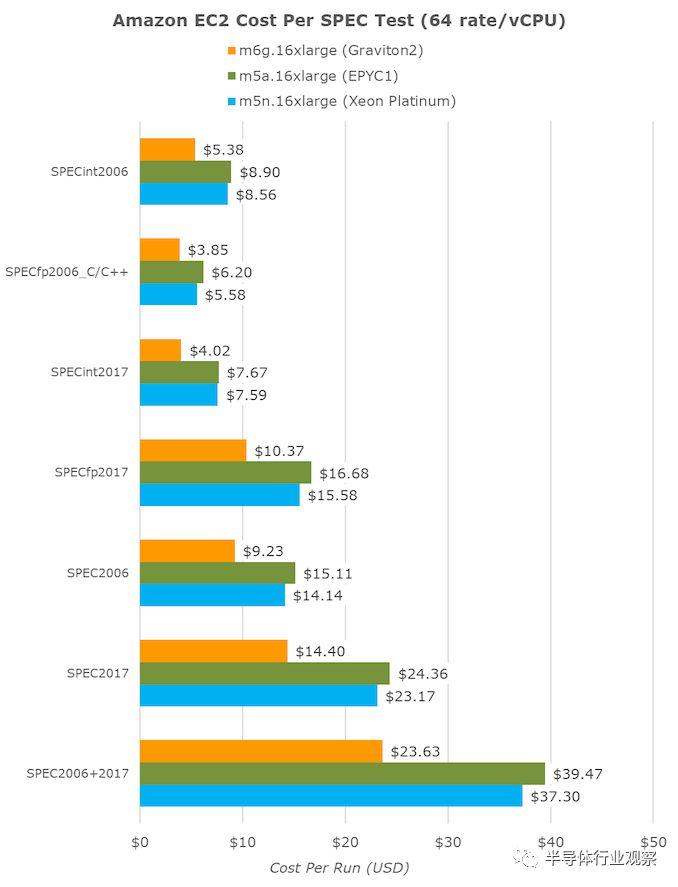
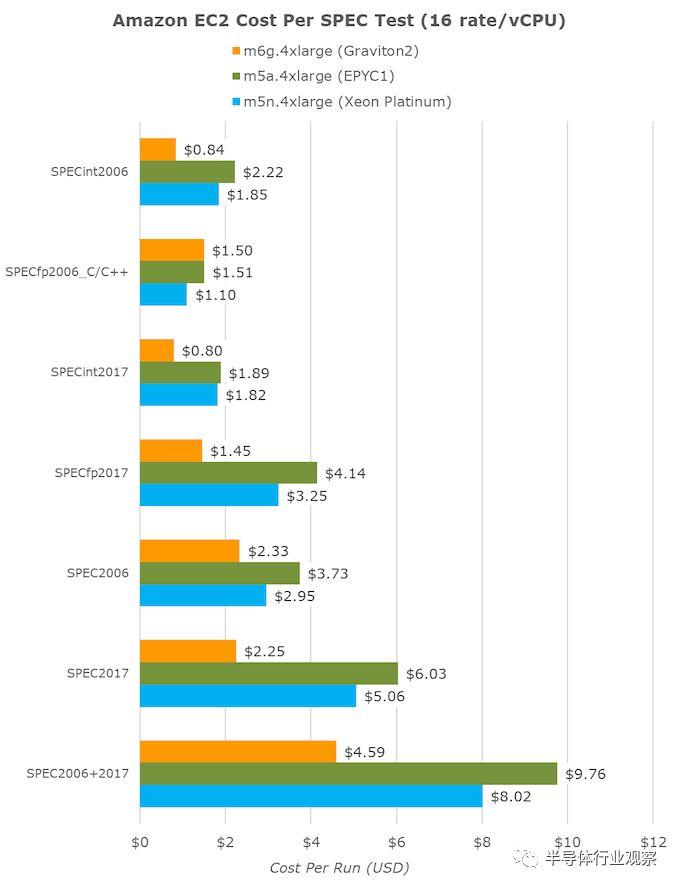
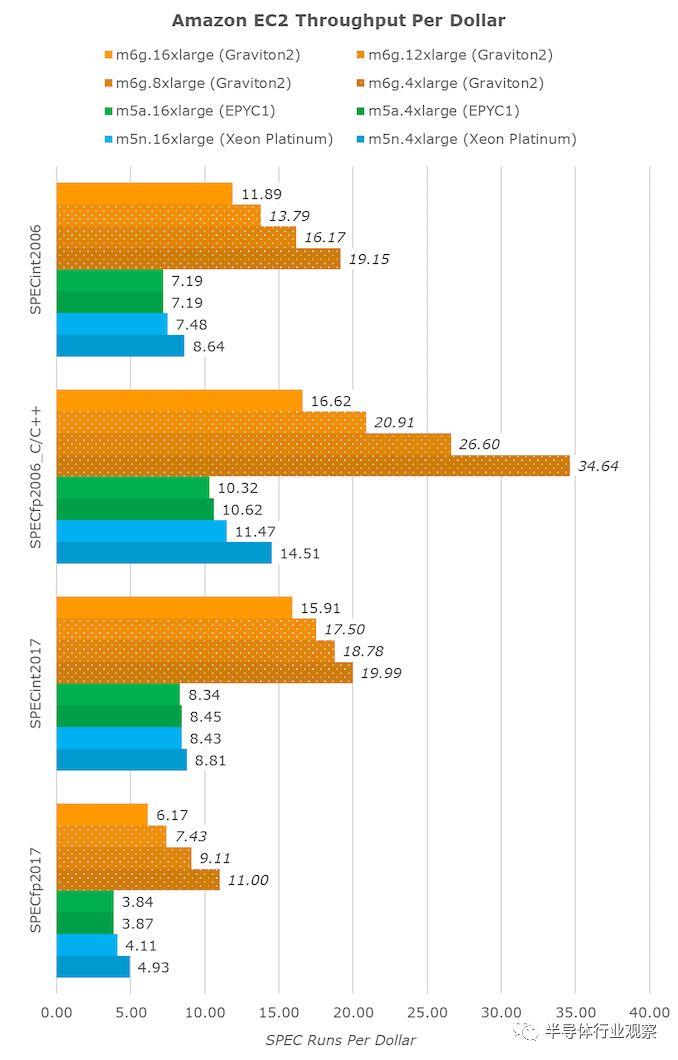
vCPU實例的大小越小,Graviton2的價值似乎就越高,因為隨着vCPU數量的增加,它的性能將線性下降,但是較大的vCPU實例的成本將呈線性增長,這幾乎在AMD系統中根本不存在,而只是微不足道。存在於Xeon實例中。
同樣,Graviton2在這裏的縮放比例在生產實例中可能會有所不同,但是鑑於您不能只砍掉一半的芯片(或者在英特爾的情況下只能訪問兩個插槽之一),而且亞馬遜似乎沒有做任何事情對芯片共享資源的靜態分區,我確實認為在現實世界中很可能會遇到這種性能和價值指標。
即使忽略較低的vCPU實例,亞馬遜也能夠兑現每美元提高40%的性能的承諾,這對AWS和EC2生態系統來説是一個巨大的改變。