關於硅光芯片,英特爾跨出重要一步_風聞
半导体行业观察-半导体行业观察官方账号-专注观察全球半导体最新资讯、技术前沿、发展趋势。2020-03-18 15:26
來源:內容由半導體行業觀察(icbank)編譯自「thenextplatform」,作者:Timothy Prickett Morgan,謝謝。
在未來某個時間點,數據中心網絡方面的性能提升必然會到達一個天花板,屆時摩爾定律將失效。為了規避這個問題,很多研發工作正在進行中。例如在交換機和路由器ASIC碰壁的時候,我們就應該利用硅光子技術來幫助提高網絡設備的密度和能效,以便我們繼續建立網絡。
作為業界的領頭羊,英特爾從事硅光子學研究已久,而其連接小組的成員則由前Barefoot Networks首席執行官Craig Barratt領導(英特爾於去年6月收購了該公司以建立其以太網交換業務),他們正在炫耀一些現在剛剛商業化的技術。按照他們的規劃,其將光學器件和硅光子學封裝在一起的技術即將進入市場。英特爾Connectivity Group內的硅光子產品部門(SPPD)總經理Hong Hou和Barefoot Networks部門總經理Ed Doe向我們介紹了Intel和Barefoot的一些進展。
近年來 隨着應用變得更加分散和相互依賴(不僅由於容器,而且肯定會因容器而加劇),數據中心內部網絡的帶寬需求和基數也呈爆炸式增長。如下圖所示 :

以典型的超大規模數據中心為例。Hou告訴The Next Platform,在這情況下,系統擁有超過100,000台服務器和50,000多個交換機。這可能比構建超大規模應用所採用的大規模Clos架構所需的交換機數量要多得多。
但在Hou看來,自從他在英特爾從事硅光子技術業務以來,他所關心的是,這些超大規模數據中心之一需要超過100萬個光收發器,這些光收發器並不便宜。佔了數據中心基礎架構不小成本。統計顯示,將節點連接到交換機和交換機之間的光纖線末端的光收發器在超大規模數據中心上的花費在1.5億美元至2.5億美元之間,然後將它們運營的所有數據中心加起來,這實際上開始每年每年僅在光收發器上的花費就增加了數十億美元。順便説一下,這些光收發器約佔這些數據中心整體網絡預算的60%,超過交換機,NIC和電纜等設備的總和。

Hou解釋説:“這些光收發器都需要在幾個月內就具有一致性和可擴展性,以使雲服務提供商能夠調試數據中心,將其投入服務併產生收入。” “傳統的精品光學器件使用分立元件,因此無法提供如此快的製造可擴展性。而且,為了滿足這種水平的客户需求,對於傳統的光學供應商而言,資本支出可能太重了。”這與英特爾已經提出五年多的觀點一致。
為了解決以上問題,英特爾從二十多年前就開始進行硅光子學研究,直到2016年,公司才將其第一批硅光子光學收發器投入使用,並一直在悄然提高產量。到2018年底,它已經出貨了第一百萬台,到2019年底,它已經賣出了300萬台,僅在2020年第一季度就計劃再增加50萬台,保持每年200萬台的速度。以下是英特爾生產的兩種不同的硅光子光學收發器:

後一個收發器中的片上激光器額定温度在-40攝氏度至85攝氏度之間,這意味着它可以在設備保持乾燥但不一定與現代數據中心處於相同温度的廣泛室外環境中使用,Hou説,更重要的是,與其他供應商提供的行業標準光學收發器相比,這些新型收發器的缺陷率大約為百萬分之二十八,與現有的競爭對手的百萬分之一千相比,有很大的提升。Hou表示,超大規模者,雲構建者,電信公司和服務提供商不喜歡維修或更換設備,因此產生了共鳴,這就是為什麼英特爾在單模光纖100 Gb /秒光收發器中擁有第一的市場份額的原因。

但是最終,您真正想要做的是在交換機ASIC封裝上安裝硅光子端口,在交換機端整合收發器,儘管英特爾沒有討論這一點,但是您可以在服務器NIC端做同樣的事情SmartNIC設計中也帶有大量CPU或FPGA。
大約八個月前,在Barefoot Networks被收購之後,英特爾連通性部門的交換機和硅光子學人員開始這樣做,使用“ Tofino 2”交換機ASIC在交換機上測試了這一想法,這個chiplet設計的芯片總帶寬為12.8 Tb / sec。而Tofino 2芯片被共同封裝的100 Gb / sec光學tiles所包圍:
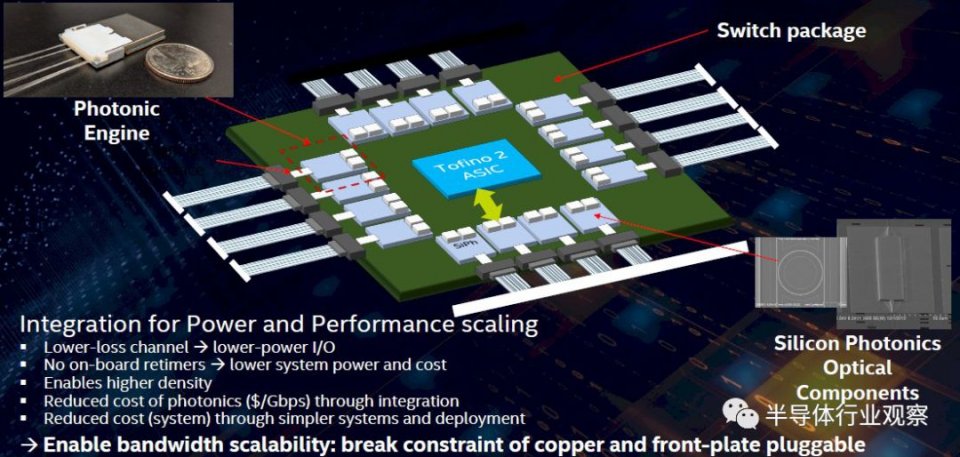
這比使用在交換機機架中具有外部激光器的光開關要好得多(比在交換機前面板中具有重定時器將其掛接到交換機ASIC中的光模塊要好得多)。因為他們擁有更加搞的密度和更加低的功耗。通過降低功耗,現在可以更快地實現開關ASIC上的SerDes加速,然後將所有組件的速度提高兩倍。
英特爾演示的光子引擎運行速度為1.6 Tb /秒(使用PAM4編碼的16個通道以100 Gb /秒的速度運行),但可擴展到每瓦3.2 Tb /秒,這意味着可以在未來的Tofino芯片上進行前端處理具有25.6 Tb /秒,51.2 Tb /秒,甚至102.4 Tb /秒的總交換帶寬。Tofino 2芯片沒有100 Gb / sec的SerDes,但是後續的Tofino NG芯片可能會在今年晚些時候面市,而其後續的兩款產品也將面世。在開關電路達到摩爾定律極限之前,這可能是最後一個速度提升到更快的SerDes(100 GHz,用PAM4編碼)。將光學器件與硅光子學集成將成為關鍵,並且可以肯定地將其與100 GHz SerDes的速度相結合,並且可能與後來的50 GHz的下一代產品相提並論。
考慮到所有這些,在光學器件上節省功耗和金錢將意味着允許開關ASIC燒得更熱,變得更大,而這將需要在5納米或3納米世代左右進行。這樣,開關/收發器綜合體的整體散熱和成本仍將在成本和散熱方面下降,這就像英特爾所主張的那樣,是使摩爾定律得以維持的一種方式。