中國的基尼係數是多少?_風聞
观察者网用户_239226-2020-05-13 14:49
根據官方發佈基尼係數的《中國住户調查年鑑》,從2003年到2018年,中國的基尼係數走勢是這樣的:
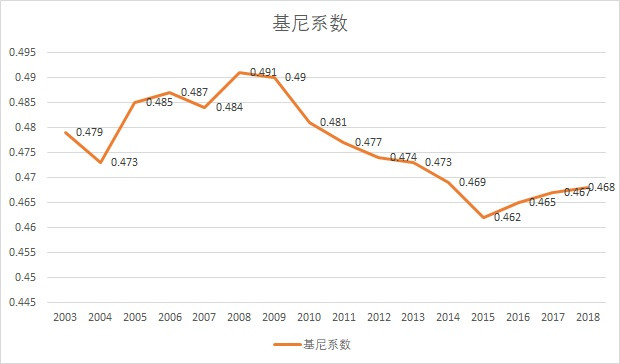
在2008年前上升,從2009到2015年下降,隨後再次上升。最新的基尼係數是2018年的0.468。
當然我們都知道,有很多微觀調查數據的基尼係數都和官方發佈的基尼係數不太一樣。這裏我們主要會用到這樣幾份數據:
1,CLDS,2016年調查
“中國勞動力動態調查” (China Labor-force Dynamics Survey,簡稱 CLDS)是“985”三期“中山大學社會科學特色數據庫建設”專項內容,CLDS的目的是通過對中國城鄉以村/居為追蹤範圍的家庭、勞動力個體開展每兩年一次的動態追蹤調查,系統地監測村/居社區的社會結構和家庭、勞動力個體的變化與相互影響,建立勞動力、家庭和社區三個層次上的追蹤數據庫,從而為進行實證導向的高質量的理論研究和政策研究提供基礎數據。
2,CHFS,2017年調查
中國家庭金融調查(China Household Finance Survey,CHFS)是中心最早開展的全國大型抽樣調查,旨在收集家庭的資產與負債、收入與支出、保險與保障、人口與就業等方面信息,全面追蹤家庭動態金融行為。目前,中心已經成功實施三次調查。2011年,收集家庭樣本8438户,樣本具有全國代表性;2013年,收集樣本28141户,樣本在全國代表性的基礎上增加了省級代表性;2015年之後,樣本擴大到40000餘户,具有全國、省級和副省級城市代表性。
3,CFPS,2018年調查
中國家庭追蹤調查(China Family Panel Studies,CFPS)旨在通過跟蹤收集個體、家庭、社區三個層次的數據,反映中國社會、經濟、人口、教育和健康的變遷,為學術研究和公共政策分析提供數據基礎。CFPS重點關注中國居民的經濟與非經濟福利,以及包括經濟活動、教育成果、家庭關係與家庭動態、人口遷移、健康等在內的諸多研究主題,是一項全國性、大規模、多學科的社會跟蹤調查項目。CFPS樣本覆蓋25個省/市/自治區,目標樣本規模為16000户,調查對象包含樣本家户中的全部家庭成員。CFPS在2008、2009兩年在北京、上海、廣東三地分別開展了初訪與追訪的測試調查,並於2010年正式開展訪問。經2010年基線調查界定出來的所有基線家庭成員及其今後的血緣/領養子女將作為CFPS的基因成員,成為永久追蹤對象。CFPS調查問卷共有社區問卷、家庭問卷、成人問卷和少兒問卷四種主體問卷類型,並在此基礎上不斷發展出針對不同性質家庭成員的長問卷、短問卷、代答問卷、電訪問卷等多種問卷類型。
我們把這三份數據按照國家統計局的算法計算,可以得到這樣一組基尼係數:
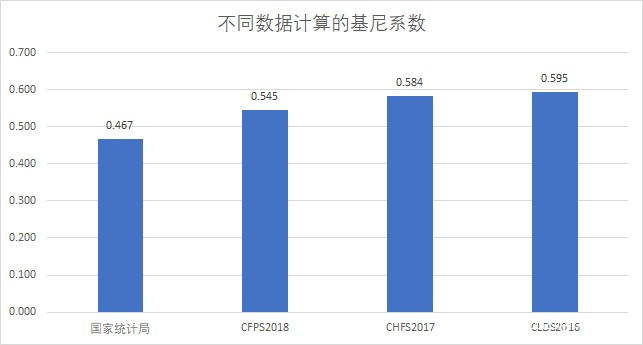
可以看到,每一個數據算出的基尼係數,都比國家統計局的0.467更高,其中最低的CFPS也有0.545,而CLDS甚至接近0.595。
問題出在哪裏呢?誰的基尼係數才是對的?那我們要看看,這幾個數據到底都長什麼樣。
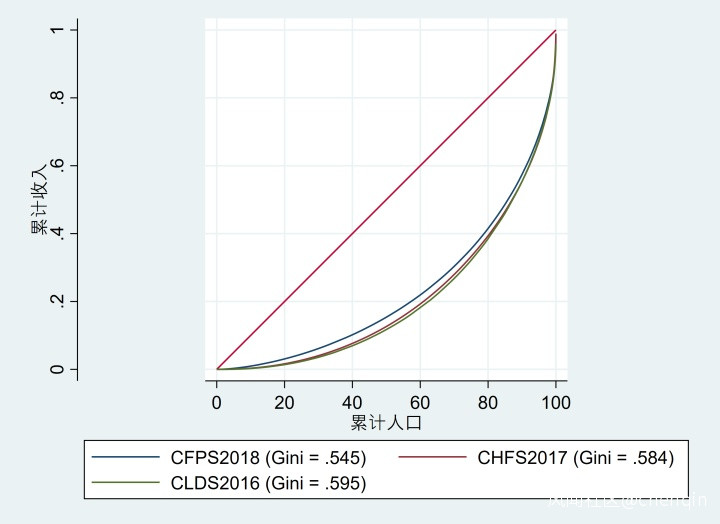
上圖呈現了以上三個微觀數據的基尼係數洛倫茲圖,橫軸標識收入從低到高的人口累計佔比,縱軸表示這部分人口的收入累計佔比。可以看到上圖的三條線都經過了(80,0.4)曲線,意味着收入最低的80%人口占了社會總收入的40%。用這三項數據計算,中國的基尼係數分別達到0.545、0.584和0.595。
那麼,統計局的數據結果如何?我這裏有調查總隊2016年在四川、上海、廣東、遼寧四地的微觀住户調查數據,把CFPS、CLDS和CHFS數據限制在四川、上海、廣東和遼寧樣本,拿來和統計局住户調查做一個對比,結果如下:
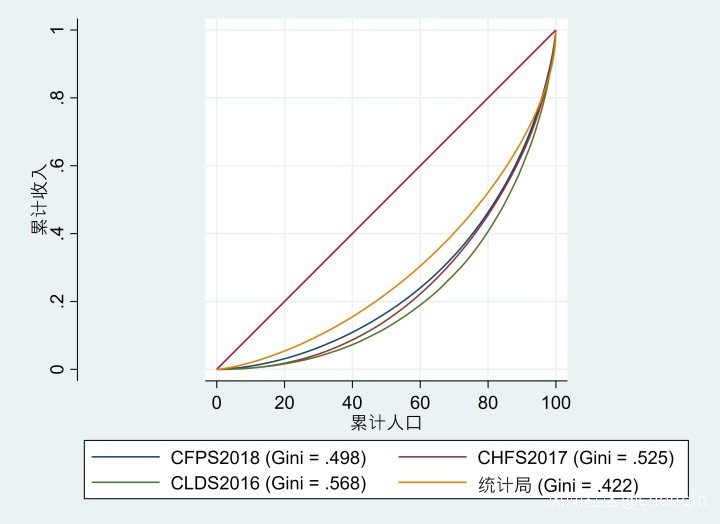
結果看來,四省基尼係數都要比全國要小一些(地區更少且地區貧富差距更小的情況下,基尼係數更低),其中統計局的基尼係數從全國層面的0.465下降到0.422,CFPS和CHFS也都下降了0.05左右,分別達到0.498和0.525。CLDS仍然在0.568。
我們這裏可以得到第一個猜想:
用微觀數據計算基尼係數,在同樣口徑的情況下,統計局的基尼係數要比各項微觀數據計算的結果低0.08到0.15左右。
接下來就來了第二個問題:各項微觀數據算出的基尼係數為什麼要比統計局調查的結果更高呢?
我們在答案的第一幅圖中的99處加入一條線,他們代表收入最低99%人口可佔據的收入比例,見下圖:
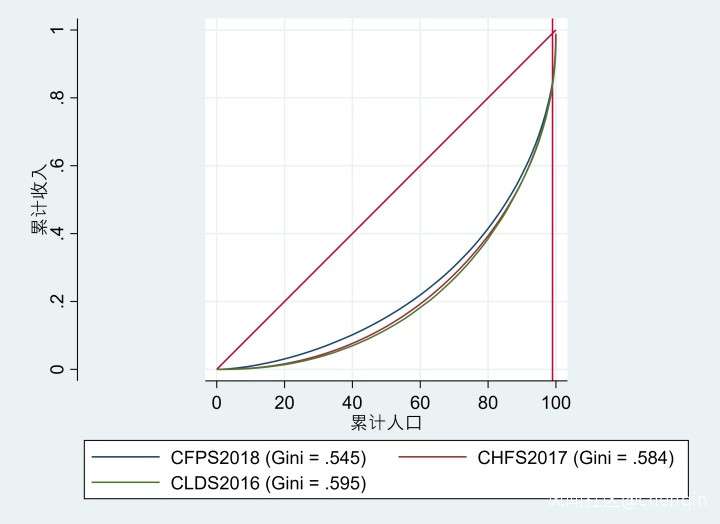
可以看到,在累計人口到了90%的時候,收入曲線上移的速度陡然加快,累計人口從99到100時,累計收入上升了10%以上。三個數據的前1%人口和前0.1%人口分別佔社會總收入比值如下:
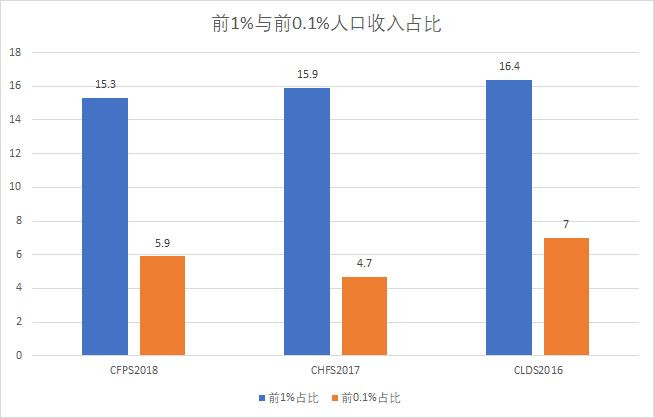
按照這個比例計算,在這些微觀數據中,前1%收入水平是平均收入的15-16倍;前0.1%的收入水平是平均收入的50-70倍。
那麼,統計局調查到的前1%人口和前0.1%人口,其收入佔比是多少呢?
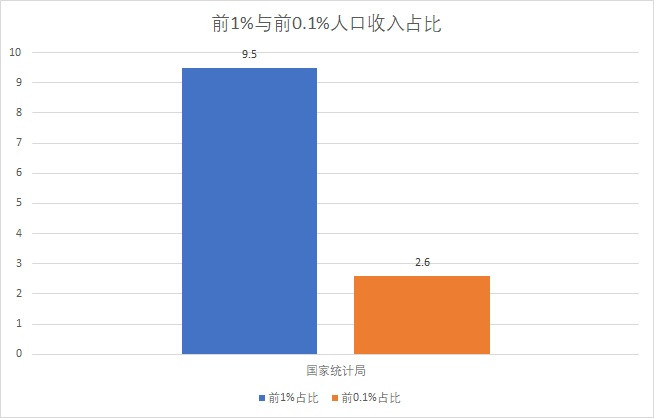
統計局調查到的住户中,前1%人口的收入只是社會平均收入的9.5倍;前0.1%人口的收入只有26倍。這要遠低於CFPS、CHFS和CLDS的調查結果。
如果把這三組數據的前1%收入去掉,則會出現下圖:
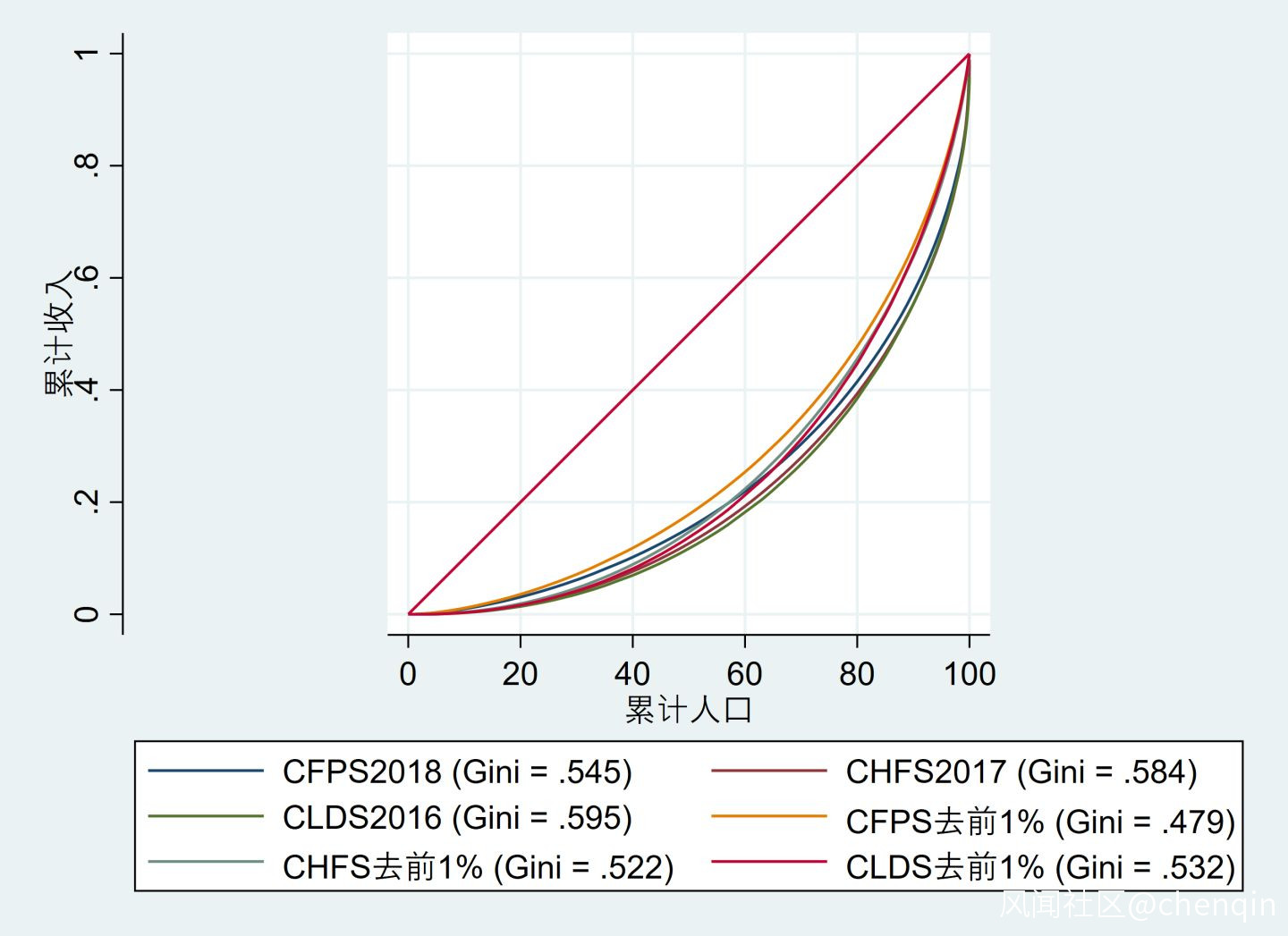
可以看到,此時各數據的基尼係數都比之前降低了不少,CFPS的基尼係數還剩0.479,已經接近統計局的全國水平;CLDS和CHFS也下降到0.532和0.522。
因此,我們可以得到第二個問題的答案:有沒有調查到富人,是統計局基尼係數和其他微觀調查數據基尼係數產生差異的主要原因。
但順勢我們又有了第三個問題:統計局或各項微觀數據,誰調查到的富人規模才能正確反映社會現狀?
這裏我們需要藉助一些外部數據庫,《2018胡潤財富報告》
這份數據「採用微觀和宏觀的調研方法調研。微觀調研上參考各個地區高檔住宅數量、最近三年豪華汽車銷量、個人所得税申報人數、企業註冊資本和其他高檔消費等相關指標。宏觀上參考國家統計局最新公佈的中國GDP、GNP數據,並結合洛倫茲曲線模型進行宏觀分析統計」,估算了全國高淨值人羣的規模,他們發現,截止至2017年12月31日,中國大陸資產千萬的家庭達到了161萬户;資產億元上的家庭達到了11萬户。由於採用了宏觀數據下推,這個估計應該説比較準確。
在三份微觀數據中,僅有CHFS調查了家庭資產,在4萬户CHFS被調查家庭中,資產在千萬元以上的家庭有522户,按抽樣權重計算並放大到全國,共可推算出380萬户千萬元以上資產的家庭,是《2018胡潤財富報告》推算的2倍多。如果按照人口占比調整(胡潤財富報告按照每户人數相同計算),千萬元以上資產家庭的户數進一步降低到320萬户,是《2018胡潤財富報告》的2倍。
但億元以上資產的家庭呢?在調查中有522户千萬以上資產家庭,那麼其中應當有幾十户億元家庭吧?
很遺憾,一户也沒有。因為CHFS為了保護隱私,對每一户的資產進行了截尾,所有資產超過3000萬的家庭,資產都記為3000萬元;收入高於500萬的家庭,收入都記為500萬。在前文也可以看到,CHFS的前1%人口收入和另兩個數據差不多,但前0.1%人口收入就要低於另外兩份數據,原因就在於這個截尾。
但截尾前的原始數字並不是完全不能推算出來,CHFS有很複雜的數據結構,一些指標報告了原始值,例如房產等,他在數據庫中也記錄了原始值。我們利用這些原始值重新推算截尾前的家庭資產,結果發現,共有6户被調查對象在恢復了截尾前數據後得到了億元以上的資產,按權重調整後推算全國,應有4.6萬户家庭資產在億元以上。
兩相對比,有這樣的結果:
千萬元資產——CHFS,320萬户;胡潤財富報告,161萬户
億元資產——CHFS,4.6萬户,胡潤財富報告,11萬户。
這個對比説明CHFS的調查還是相對比較準確的,尤其是對於佔比如此低的極富人口調查,數量級能對得上,已經很不容易。
接下來就是激動人心的時刻:CHFS調查到的富人——我們認為他比較接近真實水平——和統計局調查到的富人,其收入差別有多大?
我們可以算出,CHFS調查中最富有的前1%家庭的的每户人均收入情況是:
中位數為70萬元,平均值114萬元,最高值為800萬元。
那麼,在統計局的微觀數據中,收入最高的前1%家庭,類似的指標是?
中位數25.2萬元,平均值33.7萬元,最高值為157萬元。
答案來了,統計局的基尼係數較低,並不是因為基尼係數真的很低,而是他的調查並沒有覆蓋到那羣最富的人。統計局數據中的99%分位數,相當於CHFS截尾前數據的97.3%;CHFS截尾前數據的99%,在統計局數據中可以拍到CHFS截尾前數據的99.9%;統計局的最高收入水平,僅相當於CHFS截尾前數據的99.7%,其上還有千分三更富有的家庭,不在統計局的調查樣本之內。
而加上在統計局數據中被大大稀釋的前1%富人,才能反映我國相對真實的基尼係數,真實的貧富差距。
現在,讓我們給出最後一組計算——前文中的基尼係數,我們都用了截尾後數據,那麼如果用恢復了截尾前原始情況的CHFS數據,能算出多高的基尼係數呢?結果如下:
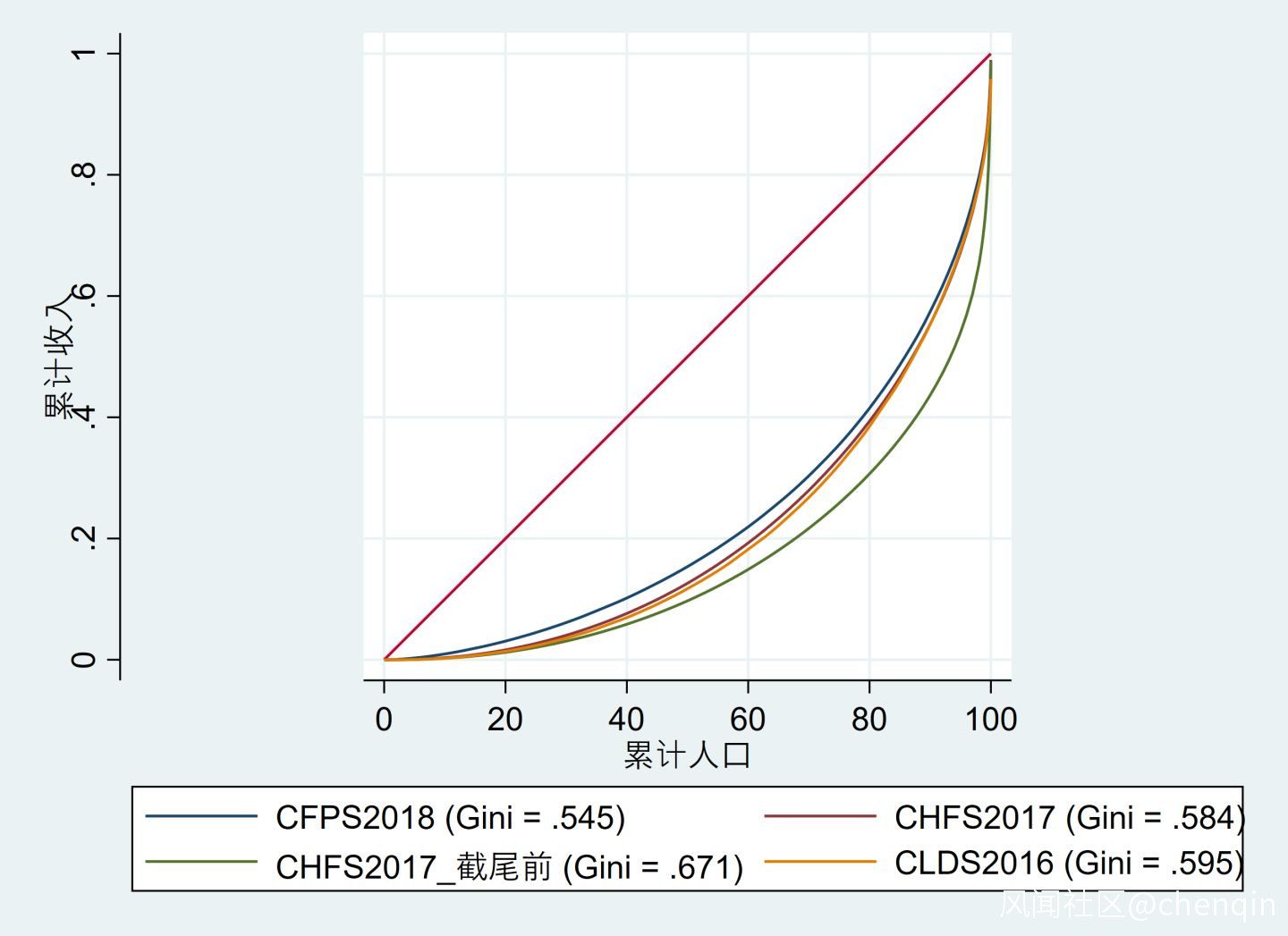
將3000萬元以上資產和500萬元以上收入的家庭恢復到原始值,基尼係數達到了0.671!考慮到CHFS對富人的抽樣水平較高,在千萬元資產和億元資產的家庭數量的估計上與其他數據更一致,我認為這個數字更接近中國的真實水平。
綜上所述,中國的基尼係數有不同的結果:
如果在統計局口徑(幾乎不包括前1%人口),基尼係數約為0.47;
如果包含富人,但是沒能包含那些最富有的人口(如CFPS、CLDS和截尾後的CHFS),則基尼係數約為0.55到0.6之間;
如果不僅包含了富人,還包括了那些億萬富翁,包括那些人均收入達到了平均水平上百倍的人(如截尾前的CHFS),那麼中國的基尼係數會超過0.6,達到0.67。