無處不智能:AI數據的“消費升級”,剛剛開始_風聞
脑极体-脑极体官方账号-从技术协同到产业革命,从智能密钥到已知尽头2020-05-27 19:10
“新基建”的哨聲吹響,想必大家已經從各個渠道感受到了產業智能化的火熱。
這一次,AI不再停留於“人工智能又碾壓人類了”的科幻劇情,而是化身為社會通用型技術,各種家居、汽車、商超、3C產品等領域,都開始高頻出現帶有AI身影的宣傳。
其中,人工智能三要素——數據、算法、算力中,最基礎、最核心的部分——數據,自然也就成為烹飪產業智能化這道美味所必不可少的原材料,也愈加受到更多矚目。
如果我們將產業智能化的紅利,看做是等待切分的蛋糕。那麼坐在電腦前對圖片或文字一點點打上標籤的數據標註師,可能就是在智能沃土上種植小麥的人。
這些處理好的食物,被算法工程師拿到後投餵給機器,教會它們認識什麼是貓,什麼是狗,行人和紅綠燈的區別,“這幾天天天天氣不好”表達了什麼意思……

聽起來,AI數據的“種植”是不是挺簡單的。確實,在人工智能前期發展階段,AI數據採集和標註,也常常被看做一個“沒有壁壘”的事情,甚至稱之為新時代的血汗工廠。
但就如粗谷吃多了總會開始追逐健康、有機、精加工,AI數據行業也早已在我們目之所及的地方,開啓了一次“製造升級”。
產業智能化的滋味,你和數據都想了解
雖然AI數據不是算法訓練的唯一要素,但絕對是不可或缺的一部分。
一方面,AI數據更豐富且廉價的領域,更容易誕生出AI的火苗。比如機器翻譯發展了數十年,積累了非常多的雙語對照語料,因此一遇機器學習便化龍,深度神經網絡的引入很快讓翻譯系統的效果全面超越了以統計模型為基礎的SMT(統計機器翻譯)。如今,NWT神經機器翻譯早已是智能語音產品的標配了。
另外,AI數據的質量也決定了AI產品是否貼合使用場景,影響着用户體驗乃至產品生命週期。在挖掘人工智能產業化富礦的時候,對AI數據的重視,再怎麼強調都不為過。
由此,也誕生出了專業的第三方AI數據產業鏈,來滿足高質量、大規模的數據需求。
不過,當人工智能高歌猛進的時候,AI數據產業的掣肘也接踵而至。

首先,傳統的爬蟲或眾包模式,數據採集的多而淺,難以滿足高性能、高精準算法對數據的需求。舉個例子,在金融等場景中,銀行對人臉識別算法的精準度要求可能是99.99%,才能達到保護客户財產安全、防範安全風險的級別,傳統的平面臉部數據顯然是不夠的,需要維度更加豐富、角度更加多樣的3D臉部圖像才能訓練出所需的算法。
此外,機器學習的數據依賴,也增加了AI訓練的直接成本。無論是採集或購買數據本身的支出,還是調用數據增強等技術來增加數據樣本,背後都是不小的成本。
至於AI學術界剛剛興起的膠囊網絡、少樣本甚至零樣本學習等,雖然能不必再為數據規模而掣肘,但目前都還在實驗室階段,在產業落地上的成熟和穩定性都不可預知,距離實用還有很遠的距離。所以在當下,以深度神經網絡為核心的機器學習,依然是人工智能走向產業化的技術託舉。這也決定了對AI數據的飢渴,將在一段時間內始終伴隨AI行業的發展。
從產業化與工程化的邏輯視角來看,今天企業想要打造出效果與口碑受到肯定的AI產品,可能購買的通用型“麪粉”已經不能滿足挑剔的用户了,還得學會自己耕種數據的沃土。
夜來南風起,小麥覆隴黃:AI數據場景化的成熟時
新基建的風潮一來,AI數據產業也以超乎預期的速度在飛馳生長。
原因無他,數字技術與千行萬業的融合,是今天中國普遍展開的主基調,而數據更是遍灑在大地上的種子,等待完成一場智能的豐收。
那麼,到底需要怎樣的種植邏輯,才能讓它們茁壯生長,有資格進入生產車間,最後變成滋養社會智能的高營養食品呢?答案或許也隱藏在中國人的“耕種天賦”裏:
第一,尊重規律的專業化。
我們知道,一些有實力的科技大廠如BAT,往往都自建數據中心,來完成算法的精進。而對於更廣大的企業來説,面對的是一片數據的洪潮,爆炸式創新也必然帶來爆發式增長的數據規模,有預測顯示,到2025年有80%的計算來自於AI計算,涉及的數據也有180ZB之多,比現在增長了4倍。要在如此龐大且複雜的數據羣落裏,找出最適宜自家土壤的“種子”,顯然不是一件容易的事。

此前就有谷歌工程師在被問到眾包平台M-Turk(在公開平台發佈任務,參與者自由申領)的效果時,聲稱“回收的數據良莠不齊”。
用一句AI界的話來説,“garbage in,garbage out”,如果餵給算法垃圾食材,在無監督學習的情況下,就很有可能發展出讓產品口碑崩盤的病灶。
比如此前市面上就出現過一款針對青少年的智能音箱,在對話時突然冒出了髒話。原來是訓練時沒有對數據集做好清洗,導致不良數據混了進去,讓AI化身“祖安人”,廠商不得不臨時全面停止調用,重新進行大規模的內部審查。
要是再一不小心用到了被限制的數據,比如歐盟GDPR通用數據保護條例的紅線,那不僅失去了當年的收成不説,很可能還要搭上一大筆賠款。真是谷歌聽了沉默,Facebook聽了流淚。
難以把控的數據質量,很可能讓企業的心血直接變成秋風中的寂寞。所以,更為專業的數據採集與標註平台,也就成為珍惜天時地利的AI企業者們所需要的夥伴。
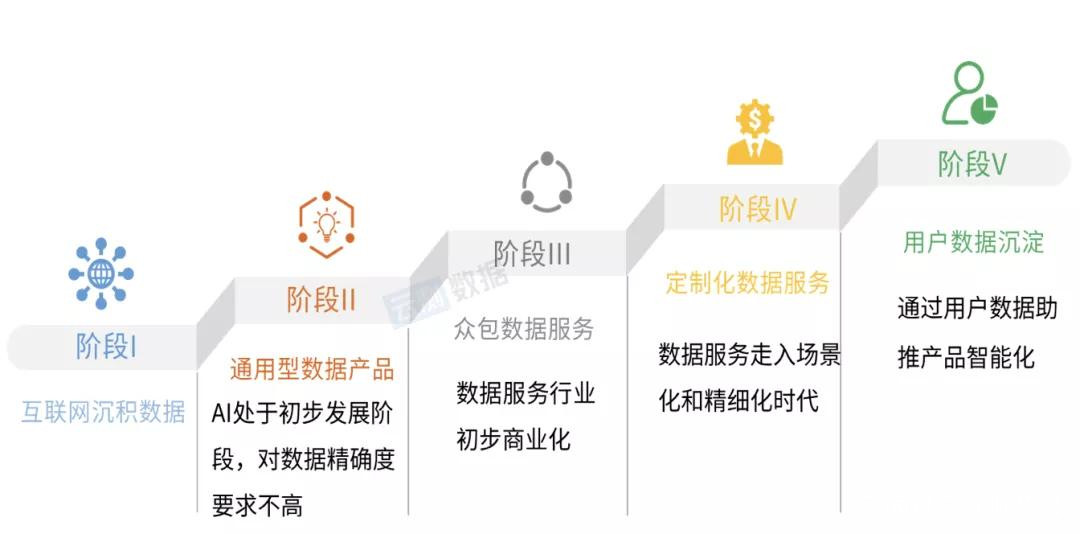
第二,因地制宜的場景化。
在商業AI數據平台中,“基於AI落地場景”是一個相對較新的模式。
是開源數據集不香,還是通用數據不便宜呢?場景化數據開始流行,或許與AI計算產業接下來發展可能觸碰到的一個矛盾點有關,那就是競爭。
我們知道,目前AI已經成為一種通用目的技術GPT,這也代表着它會以更廣泛地姿勢融入人類社會,在此基礎上生髮出新產品新技術,甚至更新生產和組織方式。
既然是GPT,就意味着泛AI算法不再稀缺,而是遍佈在日常生活中的水和空氣。如何在AI產品上與同業者拉開競爭身位,從AI數據上重新奠定自己的核心優勢,就成為科技企業們的必然選擇。
舉個例子,以前的商超門店大家都沒有智能化,如今則幾乎每家店都在嘗試引入零售智慧解決方案。這種情況下,一個零售商超的企業主,掌握了自己的獨家的場景化數據,也就能夠更精準地認識自己的經營狀況。比如在此基礎上了解顧客面對貨架、在場內走動的表情,能夠輔助判斷陳列方案以及個性化的營銷推送,進一步提高轉化和復購。

這種更高級別的場景化數據,想要獲取並交付給算法端去使用,並不是一件簡單的事。
雲測數據總經理賈宇航舉了一個例子,比如在線上訂票這樣的對話場景中,會有許多種表達方式,“有去XX的航班嗎”“幫我查一下機票”……如何讓AI助理在不同的表達中都能明白對方的意圖,就需要AI數據服務企業與訂票平台仔細地對接需求,並在標註時往適當的方向去拆解和作業,這樣才能因地制宜,讓大量高質量的數據轉化為垂直行業的智能養料。
一個有意思的數據是,儘管今天我們已經聽到了太多AI的新聞,但AI與行業結合的整體滲透率只有4%。在未來很長的一段時間內,對於數據場景化的押注,值得重點關注。
第三,提升能效的工程化。
當然,伴隨着數字經濟進入成熟期,二話不説就對AI一擲千金的情況已經不存在了。企業在選擇數據模式時,勢必會考慮投入產出比。
那麼場景化數據的重工重時,是否能夠讓產業智能化達到最大化回報呢?
答案是,不一定。場景化數據的成本並不低,“有多少人工,就有多少智能”在這裏體現得淋漓盡致。曾經有某AI算法平台的工作人員告訴我,為了訓練出一個精準識別人體動作的模型,他們合作的3D建模數據方會聘請人員,在姿勢採集中心拍攝好CV數據,因為數據量太大,只能放在硬盤裏,靠工作人員不斷往返兩地,將數據送到實驗室。
聽起來是不是一點也不“高科技”?
所以,工慾善其事必先利其器,隨着場景化AI數據產業的發展,工程化能力的提升、效率工具的引入,才會讓場景數據的整體成本接近商業平衡點,降低AI企業的成本風險。
顯然,對於AI數據的場景化,既是產業AI的必由之路,也密佈着大量的冰層等待鑿穿。
穿透數據冰層:雲測數據在產業端如何種植AI
當社會經濟體與智能技術開始耦合,場景化數據的產業服務者也開始展露頭角。
目前來看,成立於2011年的Testin雲測,旗下AI數據採集標註品牌——雲測數據已經成為了中國市場AI數據場景化的首選。
在AI數據的土壤上遍佈的冰層,是如何被雲測數據一一剷除的?
1.手把鋤犁的硬件。
場景化數據的採集與標註,有不少硬骨頭。比如NLP、CV(計算機視覺)等,既需要標註者精準理解相關語義,又要結合具體的產業需求進行標註。
為了保證AI數據的高質量交付,雲測數據在華東、華北、華南設有數據標註基地和數據採集場景實驗室,用來保障AI數據的專業化、場景化與精細化。
賈宇航(雲測數據總經理)給我們舉了一個例子,為了幫助疲勞檢測系統精準判斷駕駛員的狀態,疲勞狀態的數據是必不可少的。因此,雲測數據會還原駕駛場景中的疲勞駕駛狀態,來幫助採集到貼合真實場景的疲勞數據。讓訓練算法模型能夠精準識別並及時預警,來保護人員的行車安全。
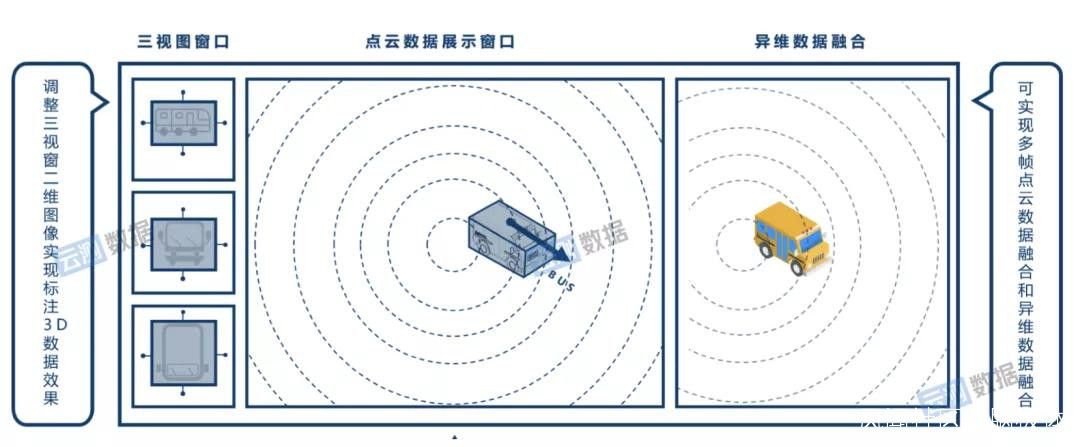
除此之外,為了提升AI數據的標註能效,雲測數據還開發了不少工程化工具,不斷提升數據標註工具的技術含量。
比如雲測數據自研的數據標註平台上,就對3D點雲的標註系統優化了渲染引擎,可以融合多幀點雲數據和異維數據,讓數據視圖一目瞭然,保證整個過程的流暢和快捷,從而減輕標註員的重複勞動壓力。
2.潤物無聲的軟件。
在AI的世界裏,我們總是在強調硬件——更大的算力,更好的數據,更優的算法。是不是擁有這些就意味一切呢?事實顯然並非如此,否則Deepmind早就是商業化最成功的AI公司。
從技術概念到產業落地之間的管理邏輯,就如同產業之上的春雨,“隨風潛入夜, 潤物細無聲”。
我們都知道“好雨知時節”,“好”在哪裏?
好在適時而下。比如Testin雲測在企業服務領域積累了近9年的經驗,其管理模式也讓數據採集與標註不再是枯燥的流水線作業,十分注重對標註人員的培養,以應對越來越高標準的數據要求。
例如,雲測數據會專門招聘一些法律、金融等垂直領域的相關人員,對標註人員進行專業知識的培訓,使其能夠從產業端的視角去揣測語料中的具體意圖,進而對數據進行更加細緻的標註,以滿足客户的精度訴求。
此外,在管理流程上,雲測數據也做到了任務的合理派發,不同類型數據的人員不混用、多層交叉質檢等等。
正是這樣的“軟實力”,不僅鑄造了雲測數據的能力優勢,也拉高了整個行業的人員素質和業務標準,轉化為滋養整個AI產業的雨水。

3.捍衞底線的信念。
如果你聽説過三聚氰胺、地溝油之類的食品安全事件,那麼AI領域一旦出現數據安全問題,損害的可能就是數萬人的財產和人身安全。
舉個例子,不少數據都是企業的最高級機密,如果不慎從第三方平台手中流出,不僅可能讓企業聲譽掃地,還可能成為競爭對手的利劍,造成搬起石頭砸自己腳的局面。
目前來看,AI數據行業還沒有形成統一的安全保障規範和標準,所以,企業的自我意識、技術措施就顯得尤為重要。
就雲測數據而言,就設置了一系列安全保障機制,比如對於客户的定製數據在交付後絕不留底、絕不復用,徹底清刪杜絕了泄露隱患;
另外,在數據採集時也會與被採集方簽訂數據授權協議,讓AI企業拿到的數據都合規合法,沒有侵犯隱私風險的後顧之憂。
防火牆設置、內部信息系統、終端不聯網、USB接口封死等機制,也從源頭保護了客户的數據安全。
賈宇航(雲測數據總經理)也曾多次公開表示,無論是 AI 公司還是數據服務公司,眼光都要長遠一些,採用未經授權的數據當然可以控制成本,野蠻發展終究會造成不良後果。
雲測數據的業務場景覆蓋了智能駕駛、智慧城市、智能家居、智慧金融、新零售等多個領域,無不是對數據安全要求奇高的領域。作為AI數據服務的頭部企業,雲測數據的安全探索,可以看做是在安全合規層面對整個行業交上的參考答案。
對於數據安全底線的捍衞,也是這個新興產業的生命線。

從雲測數據的耕耘之中,不難發現,解鎖AI數據的每一步縱然充滿難題,但也是形成產業壁壘的關鍵過程。
像雲測數據這樣持續為AI訓練注入安全高質的數據“養料”,這些都將轉化為產業的優勢積累,並撬動智能時代的無限可能。
對數據沃土的耕種,才能讓我們在AI風起時,得見一片片豐收的麥浪。