唐駁虎:北京新病毒序列公佈,很像台灣樣本_風聞
大牧_43077-2020-06-21 12:11
唐駁虎:北京新病毒序列公佈,很像台灣樣本
本文轉載自:鳳凰網(ID:ifeng-news)
文/鳳凰新聞客户端榮譽主筆 唐駁虎
核心提示:
1、根據國際知名的Nextstrain團隊製作的病毒演化樹,與北京新發病毒基因序列最相近的,是3月17日台灣上報的樣本。因此不少網民驚呼“台灣投毒”。
2、但該團隊有很多不同算法和擴展的病毒庫,如果調整算法,親緣關係較近的就變成丹麥和捷克上報的病毒。
3、但總體看由於數據缺失較多,這一團隊的基因組序列只能大致定位。但根據科學事實和社會邏輯,可以推斷出北京輸入性疫情的四個源頭。
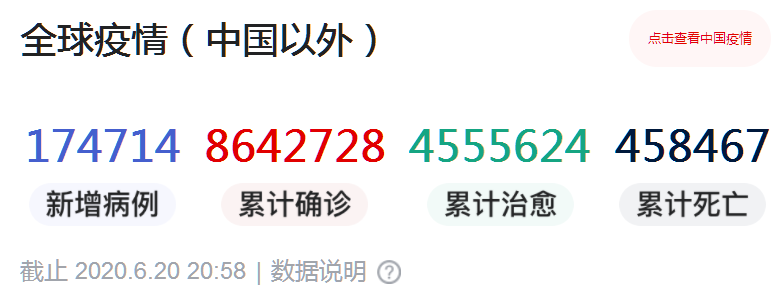
正如預期地那樣,在北京疫情得到迅速控制的同時,對病毒溯源的好奇也為公眾所關注。
那麼,導致此次北京疫情的病毒從哪裏來?如何暴發?這既是一個科學問題,也關係到下一步疫情的防控策略。
在新發地人員流動是個天量、市場裏多處檢出病毒環境樣本的背景下,通過常規的流行病學調查已經沒有可能。
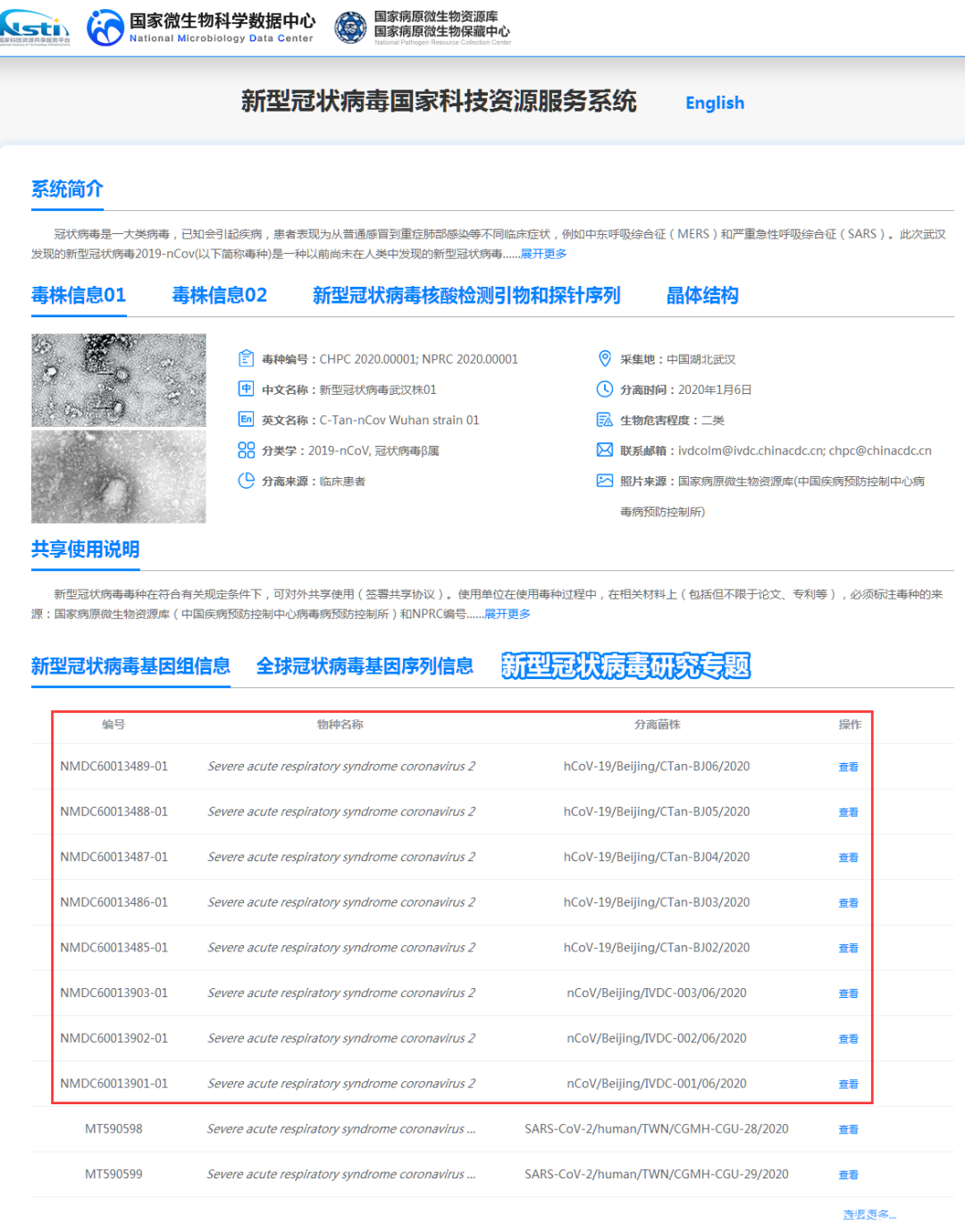
6月18日(週四)晚,中國疾控中心(CDC)通過“新冠病毒國家科技資源服務系統”,也就是中科院微生物所承辦的國家微生物科學數據中心,正式發佈了3組2020年6月北京新發地新冠疫情及病毒基因組序列數據。
這個新聞已經在第二天被廣為報道了,但實際上,19日中國CDC又提交了5組序列。雖然由於新發地疫情是單點爆發,彼此之間差異不大,2~3組就夠了。不過還是將信息彙總如下。
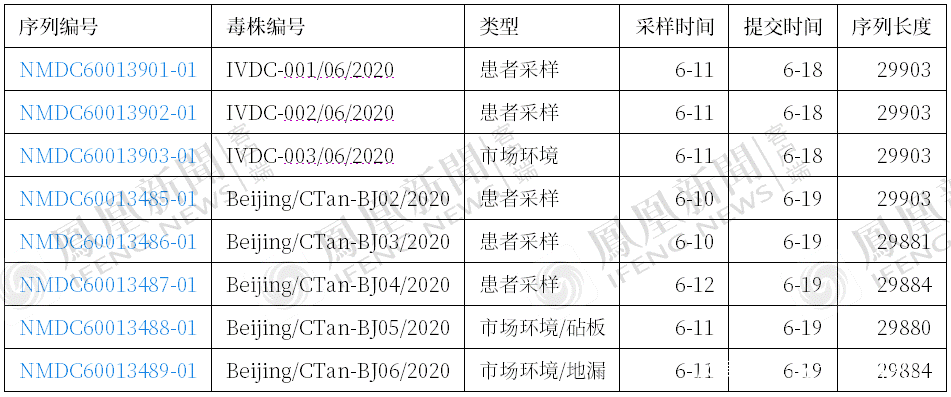
雖然編號不同,但從採樣時間(6月10日、11日)上看,應該就是在01、02號患者,也就分別是“西城大爺”、食品研究院員工身上採到的。
因為01號患者“西城大爺”是10日下午因間斷髮熱,獨自騎車佩戴口罩,到宣武醫院發熱門診就診檢查並隔離治療。當天深夜,經過近6小時核酸PCR擴增檢測,初檢為陽性。
6月11日凌晨2時,北京市疾控中心接到西城區病例標本,立刻對標本進行復核,早晨7時許,市疾控中心複核送檢樣本確認,核酸陽性。
02號患者食品研究院員工,是在9日,本人感覺不適,出現咽痛、發熱、咳嗽、流涕等症狀,到社區所在的博愛醫院發熱門診就診,並做核酸檢測。
由於首次採集樣本量太少,10日通知重新採集。11日醫院初檢結果出來,為陽性。
他的同事、03號患者作為密接者,被轉運到定點醫院隔離排查,已經是12日凌晨的事情了。
02、03號患者直到12日中午,才複核確認為陽性。所以,6月10日、11日的採樣樣本,應屬於01、02號患者。
同時,6月11日當天,就已經對新發地市場的環境進行了採樣,這説明“西城大爺”的敏鋭,為北京疾控爭取了24、甚至48小時寶貴的時間。
當然,病毒序列只有專業人士才能看得懂。同時,只有互相比較,才能得出分析結論。
但是生物信息技術的飛速發展,給我們提供了非常便利的工具,可以讓每個受過高中教育的人,都能自己瞭解、分析出病毒溯源。

GISAID與Nextstrain
之前在2月份就介紹過,國際公開共享的基因數據庫,最重要的有這麼幾組。
GenBank是美國國家生物技術信息中心(National Center for Biotechnology Information ,NCBI)建立的基因序列數據庫,面向所有生物信息。
GISAID的全稱是Global Initiative of Sharing All Influenza Data(全球共享所有流感數據倡議),由德國聯邦食品和農業部及其下屬的德國聯邦動物研究所運營。
這是2009年全球流感期間創建的數據庫,由世衞組織等倡議,目的即如其名,最開始的時候專注於流感,後來則逐漸擴大為呼吸道傳染病,及其他病毒信息。
由於病毒特性,在這次疫情中,德國的GISAID國際流感數據庫是各國學者上傳最集中的數據庫,可謂是全球標準。
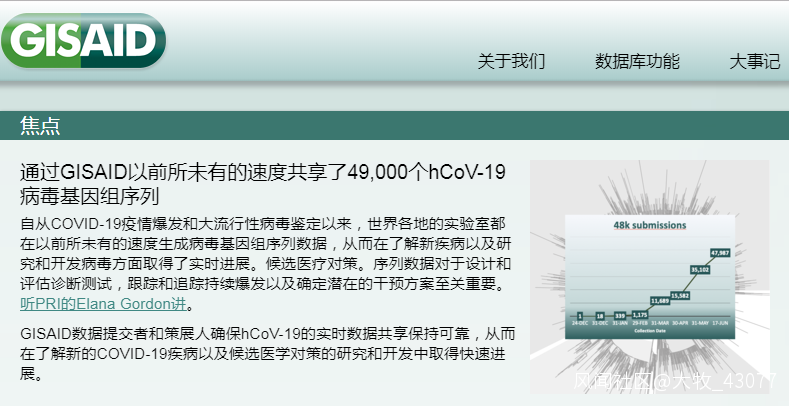
在2月底,GISAID還只是有21個國家共享了128組病毒測序數據。而隨着全球大暴發,現在GISAID上的新冠測序已經超過4.9萬組了,如實反映了全球大暴發的規模。
但是,專業的病毒序列,普通人肯定是完完全全徹徹底底看不懂的。
因此,美國西雅圖弗雷德·哈欽森癌症研究中心的Trevor Bedford等病毒進化專家團隊,組織了一個名為Nextstrain的項目。
Nextstrain項目力圖通過生物信息學,也就是分析基因序列變化。把不同的病毒放在一起,看哪個病毒突變的更多,變化更多的一般是進化更新後的病毒,突變少的更接近原始的病毒,
這個分析尤其是關注變化的特定位點,打個比方,比如某個樣本在第20000點位出現了一個變化G-T。
那麼之後採集到的新樣本,如果同樣在第20000點位有G-T的變化,則可以認定,都是之前這個病毒的子代。
因為根據概率學,其他新冠病毒同樣在此處出現獨立變化的概率只有三萬分之一。

Nextstrain計算的起點,是2019年12月24日武漢採集,2020年1月11日上傳的第一份樣本序列(左下角),以及早期序列
而且實際計算中,變化遠不止一處。比如某個病毒在第15000、20000、25000點位都有特定變異。
那麼可以肯定,第5000及15000、20000、25000,還有第10000及15000、20000、25000出現變異而且後3個位點變異相同的病毒,必然都是前序病毒的子代。
生物信息學在病毒變異上的強大分析能力,催生了“基因組流行病學”,可以通過病毒全基因組序列的演變,去追蹤病毒的傳播、演化。
這是一份非常強大的工具,就如同刑偵上基因測序與特定位點的應用一樣。
Nextstrain不僅通過算法,自動分析病毒傳播演變,還通過網站,提供了可視化的病毒演化樹。
因此,不僅為廣大普通公眾、一般生物研究者提供了便利,也為GISAID所認可、合作。
在GISAID官網上,顯著的入口便是Nextstrain呈現的可視化界面鏈接,而其本行——面向註冊專業人員上傳下載病毒序列數據的入口反而放在了不起眼的地方。

病毒的演化樹,告訴了我們什麼?
在Nextstrain,用近3000個病毒序列自動呈現了新冠病毒大流行的全景。
根據病毒的重大變異,人們把迄今為止的病毒,分組為19A、19B,20A、20B、20C幾組大簇。前面的數字表示出現年份。
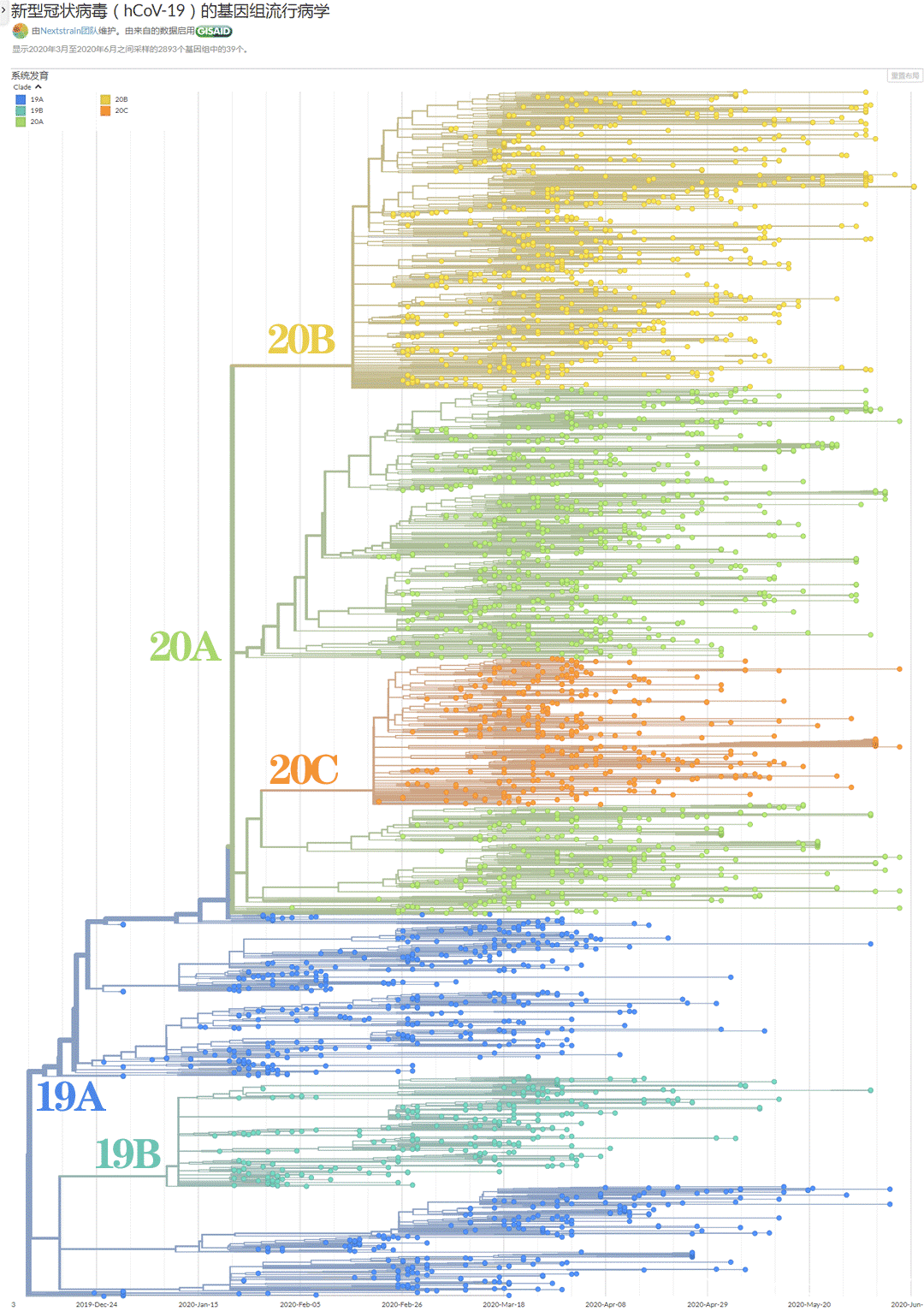
19系列,主要在亞太地區傳播(圖中藍色),同時部分擴散到美國西海岸(紅色)。
20系列在2月下旬開始被科學家們測報上傳,主要在歐洲地區傳播(土黃色),同時部分擴散到美國東海岸(紅色)、拉美(橙色)。
還有相當部分20B、20C系列,通過國際航班,迴流到了亞太(藍色),比例還不小。

圖注:根據各大洲設色的病毒演化傳播圖,藍色亞太,青色大洋洲,綠色非洲,土黃色歐洲,橙黃色南美,紅色北美。
在此前的轉述性報道里,北京的新發病毒測序,被描述為“來自歐洲”,後來又被補上幾句“但和歐洲目前主要流行的比又有些不同,它比歐洲流行的更加古老”。
這些概述用語過於含糊,令人捉摸不透。
但是現在中國CDC已經同時向世衞組織以及GISAID提交了北京新發病毒基因組序列,所以我們就能便利地瞭解病毒在病毒演化樹中的位置。
雖然確信北京新發病毒屬於20B大簇,但在這次公佈的信息中,和之前預想的又有些不同。

病毒來自台灣?
有了病毒序列,有了Nextstrain,也就能夠定位北京新發病毒在病毒演化樹中的精確位置。

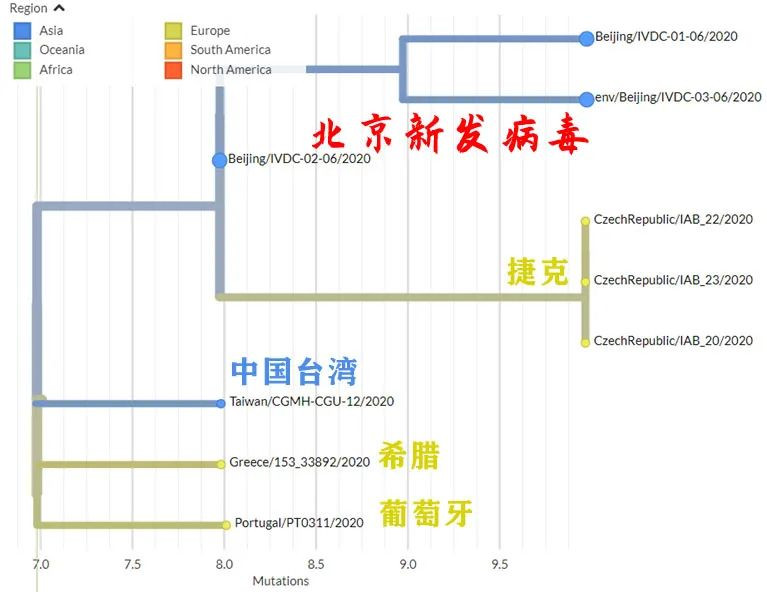
20B大簇定位,北京新發病毒在右上角。將白色區域放大,得到下圖。
發現,上圖白色區域放大後依然繁雜。

繼續放大上圖白色區域,得到下圖。

放大上圖白色(北京新發病毒本簇)與淺灰色(相鄰簇),得到下圖。
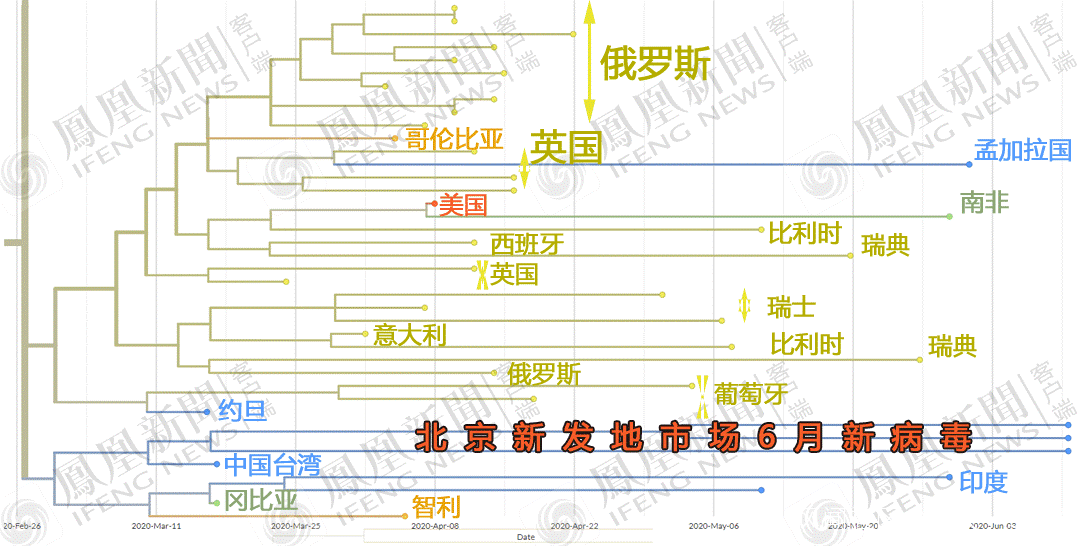
繼續放大北京新發病毒本簇,得到下圖。
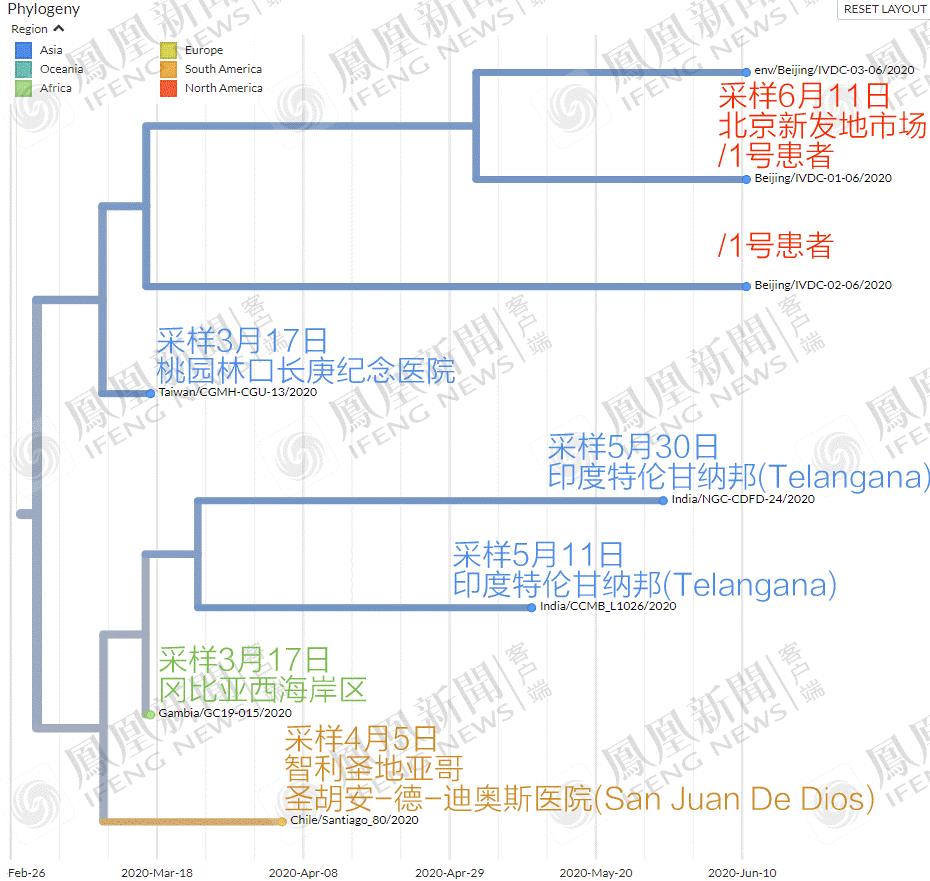
結果發現,與北京新發病毒最近的,居然是3月17日的台灣樣本?
這個編號為“Taiwan/CGMH-CGU-13/2020”的病毒序列,由桃園林口著名的長庚紀念醫院採集上報,不知道是不是桃園國際機場入境的採樣。
(1976年,台塑集團董事長王永慶為紀念其父王長庚,在台北創辦了長庚紀念醫院。經過30多年的發展,長庚醫院已擁有台北、林口、基隆、高雄等7個院區,8300多張病牀,成為台灣最大的醫學中心。
特別是位於桃園縣龜山鄉中山高速公路林口交流道口旁的林口長庚紀念醫院,更是以4215張病牀,成為台灣規模最大的醫療機構。)
於是乎,不少網民驚呼“台灣投毒”?

另外的算法,另外的可能
但是,Nextstrain有不同的算法,收入的病毒庫也一直在調整。在另一個算法下,結果就較為不同了。

20B大簇。放大圖中白色(北京新發病毒本簇)與淺灰色(相鄰簇),得到下圖。

放大上圖白色(北京新發病毒本簇)與淺灰色(相鄰簇),得到下圖。

親緣關係較近的就變成丹麥、捷克了,台灣3月檢出的病毒在較遠位置。

Nextstrain與GISAID,都還只是管中窺豹
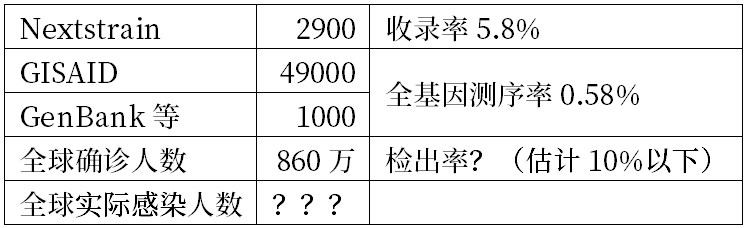
要知道,Nextstrain作為面向公眾的可視化工具,受限於性能和可讀性,只能在一個視圖中處理約3000個基因組。
所以Nextstrain一直在精簡、調整數據庫裏的重複的、不重要的序列,並及時收入新的重要數據(比如剛剛發佈的北京新發病毒),讓全部數據保持在2900個以下。
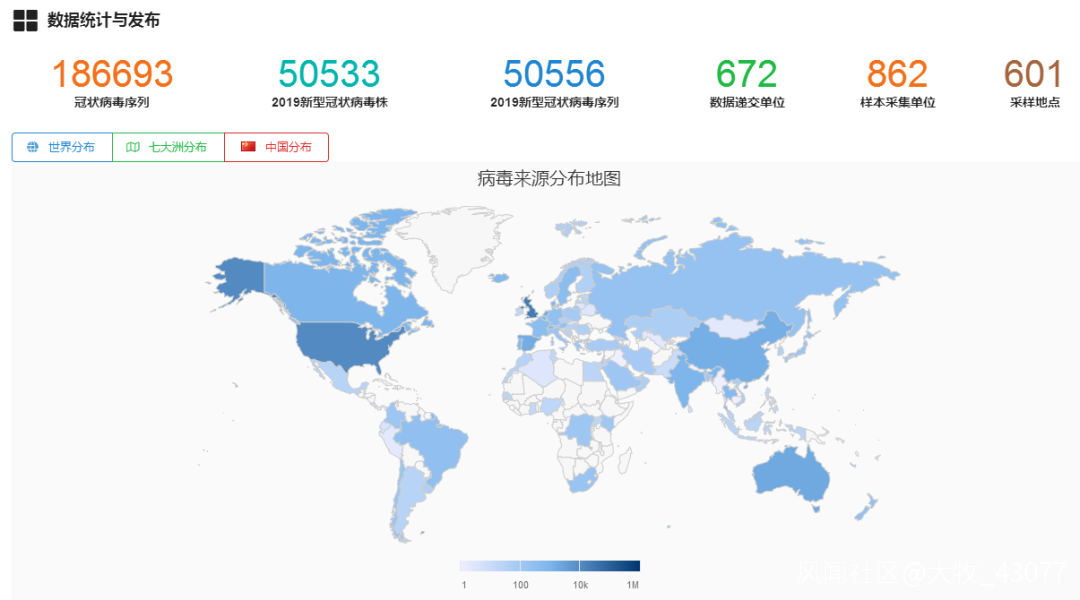
而GISAID目前已超過4.9萬個病毒基因序列。另外據中國國家微生物科學數據中心彙總統計,在GenBank還有超過1000個序列數據,全球已公佈的病毒基因組超過5萬個。
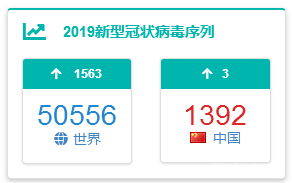
所以,Nextstrain的收錄率只有5.8%。而已經公佈的5萬個全基因組數據,相對目前全球超過860萬核酸確診人數,又是一個比例很小的數據。

目前的4種可能
所以,在測序數據缺失較多的情況下,病毒基因組序列只能大致定位,還不能確認北京的病毒到底來自什麼地方。
但是專業的生物信息學家,利用GISAID數據庫(20倍數據),一定能得出比我們利用Nextstrain自動算法更精確一些的結果,只是需要時間。
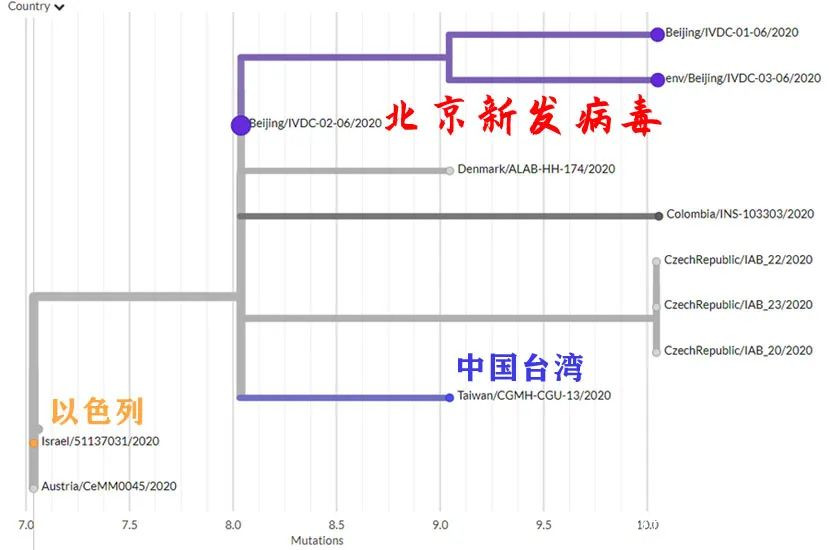

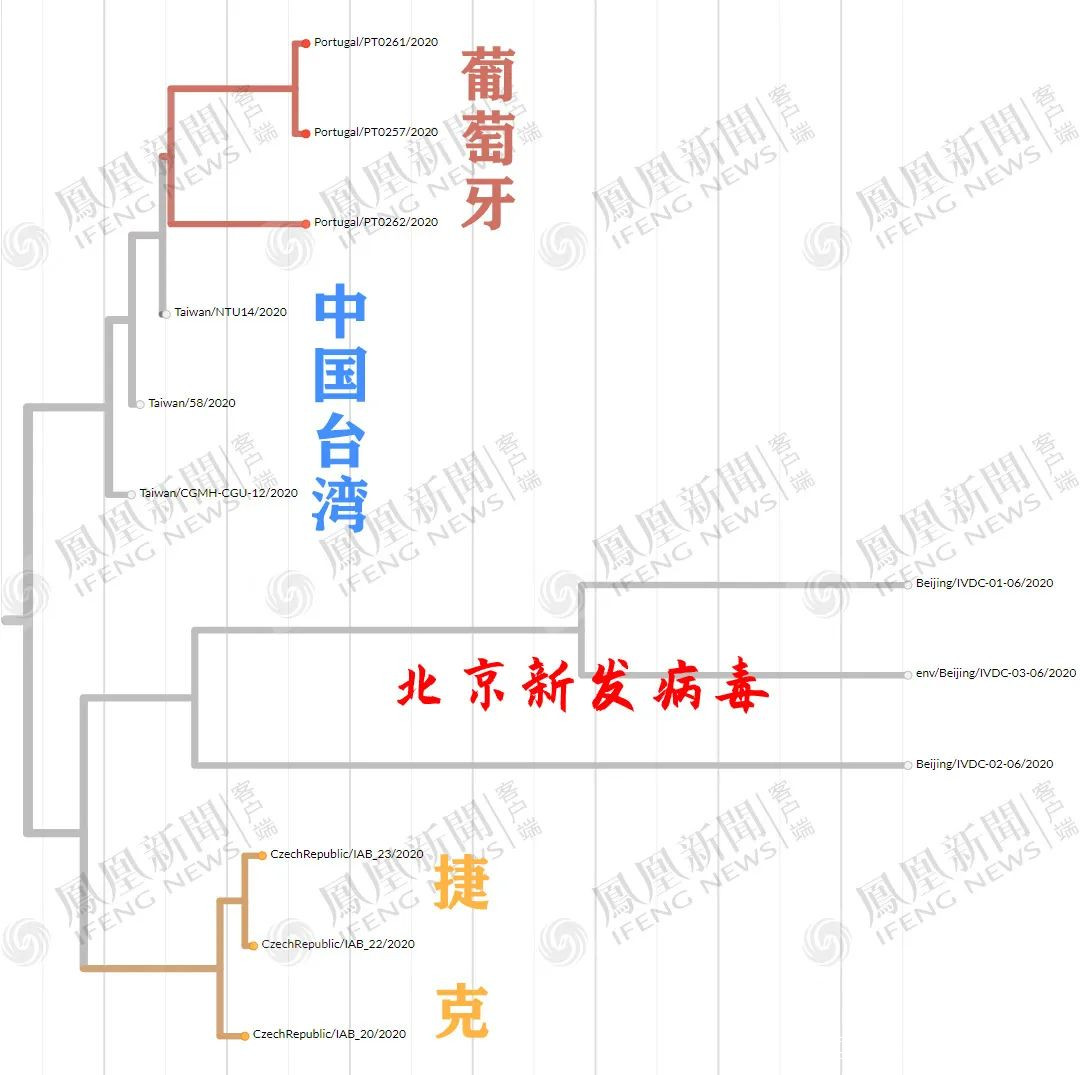
但是,目前無論是什麼算法,北京新發病毒都與台灣所驗出的病毒序列,以及亞太地區的20B迴流流行簇相關性高,其次是丹麥、捷克、葡萄牙等歐洲國家。
根據病毒序列的科學事實,以及合乎常理的社會邏輯,已經可以總結出這次北京輸入性疫情的可能源頭,可能性從大到小依次排列:
1、東亞國家和地區之間的人員流動導致了此次北京疫情。
從病毒序列看,北京新發病毒屬於20B歐洲簇的迴流亞太分簇,尤其與台灣3月檢出的病毒有親緣關係,這個需要重視。
從社會邏輯看,東亞人才有去龐大新發地購買生鮮的習慣和需求。
駐京的西方人,都是在外國人聚居的朝陽區特色農貿市場採買,這裏才有他們所需的特色食材、配料。吃的東西大部分都太不一樣了。
而且東亞人到新發地購物活動,很不引人注意,難以令當事人在後來的流行病學調查中回憶起來。
2、智利冷凍三文魚,3月底的某一批次受到感染工人污染,在運到中國及解凍加工之後,先後引發了北京新發地、天津五星級酒店後廚疫情。
但也就僅此一批,其他的都不含病毒,所以查不出來。
3、從歐洲返回/入境的人員引發疫情。有較小的可能性。
4、病毒經由3月俄羅斯、4月初綏芬河入境,後隱秘傳播到北京。
這個可能性最小,因為根據基因測序結果,北京新發病毒與俄羅斯流行的病毒沒有關聯。

病毒不可能無中生有,能夠感染病毒,肯定是接觸了攜帶病毒的人或物,或者去過存在病毒的環境。
最後還是要提醒大家,在全球絕大部分國家政府放棄抵抗的背景下,世界疫情、中國防控肯定要一直持續到疫苗大規模生產。
在這一段“漫長時期”,保持好自身的防護措施,仍然是每個人的必備措施。