一文看懂緩存_風聞
半导体行业观察-半导体行业观察官方账号-专注观察全球半导体最新资讯、技术前沿、发展趋势。2020-08-28 15:44
來源:內容由半導體行業觀察(ID:icbank)編譯自「techspot」,作者:尼克·埃文森(Nick Evanson),謝謝。
從廉價筆記本電腦到價值一百萬美元的服務器,任何一台計算機中CPU都有一個叫做“緩存”的東西。當然緩存的級別往往有所不同。
緩存很重要,不然也不會無處不在。但是緩存到底有什麼作用,為什麼是不同級別的呢?
而且12路路組相連到底意味着什麼?
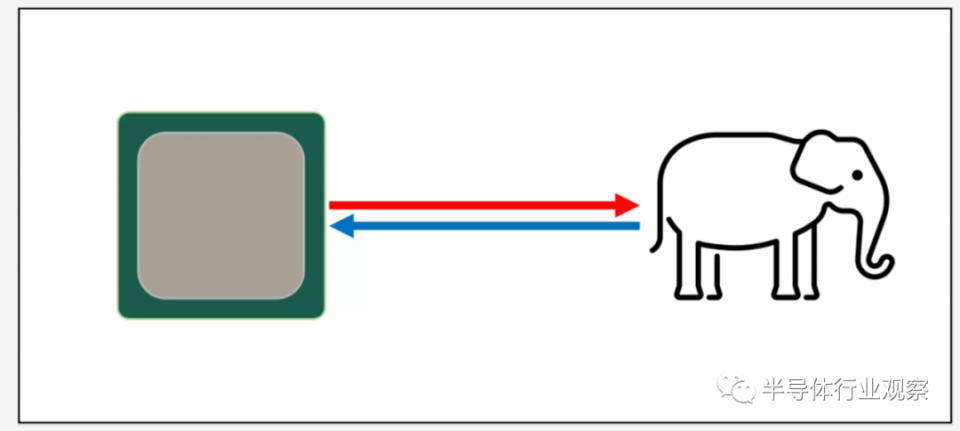
緩存到底是什麼?
TL和DR很小,但卻非常快並位於CPU的邏輯單元旁邊。當然,我們需要了解更多有關緩存的信息。
讓我們從一個虛構的,神奇的存儲系統開始説起。這個存儲系統速度極快,可以一次處理無限的數據,並始終保持數據安全。對它來説甚至不存在任何需要遠程操作的東西,但是如果的確存在,處理器的設計將更加簡單。CPU僅需要具有用於加法,乘法等的邏輯單元,以及用於處理數據傳輸的系統。這是因為我們的理論存儲系統可以立即發送和接收所需的所有編號;沒有一個邏輯單元會等待數據處理。
但是,眾所周知,實際上不存在任何上述魔術般的存儲技術。反之,我們擁有硬盤驅動器或固態驅動器,即使其中最好的驅動器也無法遠程處理典型CPU所需的所有數據傳輸。原因在於,現代CPU的運行速度非常快-它們僅需一個時鐘週期即可將兩個64位整數值相加,而對於以4 GHz運行的CPU,則僅為0.00000000025秒或四分之一納秒。同時,旋轉硬盤驅動器僅需數千納秒即可在內部磁盤上查找數據,更不用説傳輸數據了,而固態驅動器仍需數十或數百納秒。
顯然,此類驅動器無法內置在處理器中,因此這意味着兩者之間將存在物理隔離。這隻會增加數據移動的時間,使情況變得更糟。因此,我們需要的是另一個數據存儲系統,它位於處理器和主存儲之間。它需要比驅動器更快的速度,能夠同時處理大量數據傳輸,並且離處理器更近一些。
如今它已成為現實,叫做RAM。每個計算機系統都有一些用於上述目的的裝置。而幾乎所有這類存儲都是DRAM(動態隨機存取存儲器),它能夠比任何驅動器更快地傳輸數據。但是,儘管DRAM速度極快,但它無法存儲儘可能多的數據。
美光公司是DRAM的少數製造商之一,其中一些最大的DDR4存儲器芯片可容納32 Gbit或4 GB數據。最大的硬盤驅動器的容量是此容量的4000倍。因此,儘管我們提高了數據網絡的速度,但仍需要附加系統(硬件和軟件),以便確定應將哪些數據保留在有限數量的DRAM中,以備CPU使用。或者至少可以將DRAM置於芯片封裝中(稱為嵌入式DRAM)。不過,CPU很小,所以您不能在其中塞太多。
絕大多數DRAM位於處理器旁邊(插入主板)。在計算機系統中,它始終是最接近CPU的組件。然而,這還是不夠快。DRAM仍需要約100納秒的時間才能找到數據,但至少每秒可以傳輸數十億比特。看來我們需要另一級存儲器,才能進入處理器單元和DRAM之間。
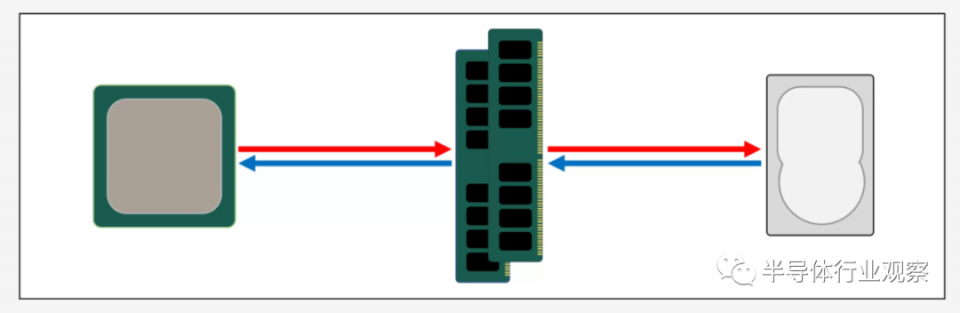
左級輸入:SRAM(靜態隨機存取存儲器)。在DRAM使用微觀電容器以電荷形式存儲數據的情況下,SRAM使用晶體管做同樣的事情,並且它們的工作速度幾乎與處理器中的邏輯單元一樣快(大約比DRAM快10倍)。
當然,SRAM有一個缺點,那就是空間。
基於晶體管的內存比DRAM佔用更多的空間:對於相同大小的4 GB DDR4芯片,您將獲得不到100 MB的SRAM。但是,由於它是通過與創建CPU相同的過程製成的,因此SRAM可以直接在處理器內部構建,並儘可能靠近邏輯單元。每增加一個環節,我們就增加了數據移動的速度,從而增加了存儲量。我們可以繼續添加更多的環節,每個環節更快但簡潔。
因此,我們對高速緩存下了一個更為專業的定義:它是全部位於處理器內部的多個SRAM塊,通過以超快的速度發送和存儲數據來確保邏輯單元保持儘可能繁忙。
對這個定義滿意嗎?很好-因為從現在開始它將變得更加複雜!
高速緩存:多層停車場
如上所述,需要緩存是因為沒有一種神奇的存儲系統可以滿足處理器中邏輯單元的數據需求。現代的CPU和圖形處理器包含許多SRAM塊,這些SRAM塊在內部組織成一個層次結構,即一系列高速緩存,其順序如下:
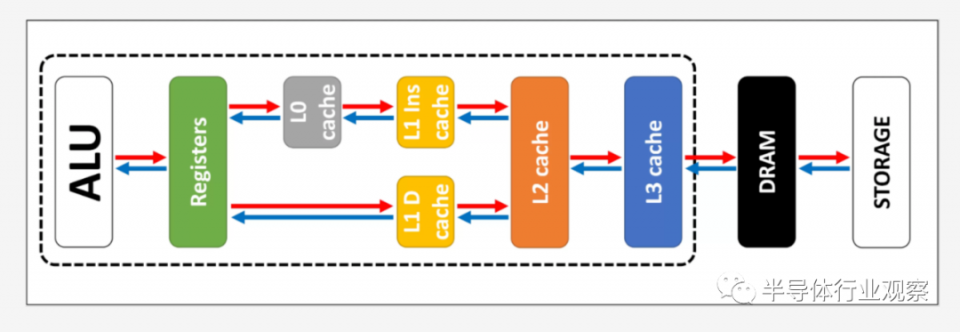
在上圖中,CPU由黑色虛線矩形表示。ALU(算術邏輯單元)在最左邊;這些是為處理器提供動力,處理芯片運算能力的結構。從專業角度來講,它不是緩存,而最接近ALU的內存級別是寄存器(它們組合在一起成為一個寄存器文件)。
其中的每一個都擁有一個數字,例如64位整數。該值本身可能是有關某物的一條數據,一條特定指令的代碼或某些其他數據的內存地址。
台式機CPU中的寄存器文件非常小-例如,在Intel的Core i9-9900K中,每個內核中有兩個存儲區,而一個整數存儲區僅包含180個64位寄存器。另一個寄存器文件,用於向量(數字的小數組),具有168個256位條目。因此,每個內核的總寄存器文件略低於7 kB。相比之下,Nvidia GeForce RTX 2080 Ti的流式多處理器(GPU等效於CPU內核)中的寄存器文件大小為256 kB。
寄存器是SRAM,就像高速緩存一樣,但是它們和它們所服務的ALU一樣快,可以在一個時鐘週期內輸入和輸出數據。但是它們的設計並不是要容納太多數據(僅存儲其中的一部分),這就是為什麼附近總是存在一些更大的內存塊的原因:這是1級緩存。
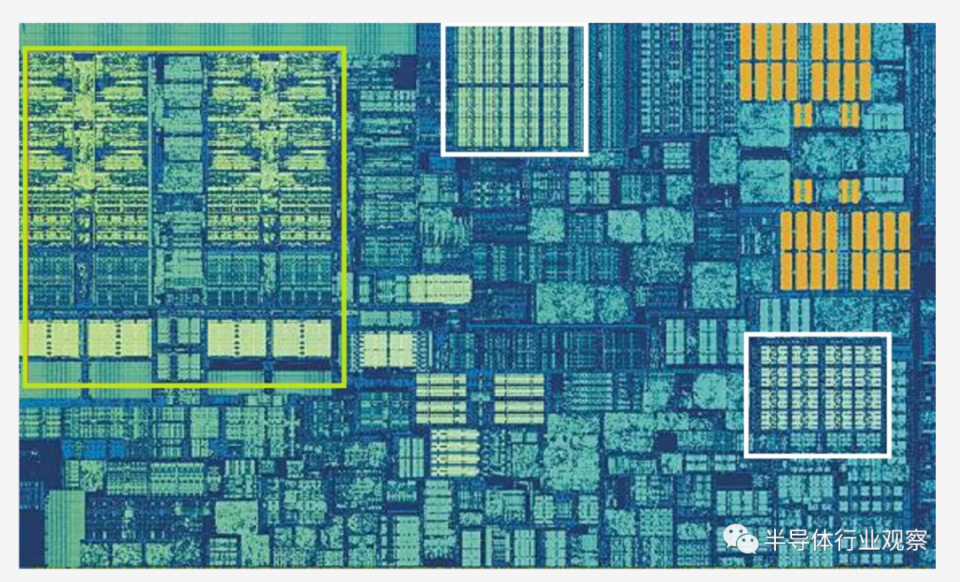
上圖是英特爾Skylake台式機處理器設計的單核的放大照片。
可以在最左側看到ALU和寄存器文件(以綠色突出顯示)。圖片的頂部中間是白色的1級數據緩存。它容納的信息並不多,僅為32 kB,但是與寄存器一樣,它非常靠近邏輯單元,並以與它們相同的速度運行。
另一個白色矩形表示1級指令高速緩存,大小也為32 kB。顧名思義,該命令存儲了各種命令,這些命令可以分解成較小的所謂的微操作(通常標記為μop),以供ALU執行。它們也有一個緩存,您可以將其歸類為0級,因為它比L1緩存小(僅進行1,500次操作)並且更近。
您可能想知道為什麼這些SRAM塊這麼小?為什麼它們不是一兆字節大小?數據和指令高速緩存一起佔用的芯片空間幾乎與主要邏輯單元佔用的空間相同,因此使其增大將增加芯片的整體尺寸。
但是它們僅保留幾kB的主要原因是,隨着內存容量的增大,查找和檢索數據所需的時間也會增加。L1高速緩存必須達到真正意義上的快,因此必須在大小和速度之間達成折衷-最多需要大約5個時鐘週期(較長的浮點值)才能從該高速緩存中獲取數據,以備使用。
但是,如果這是處理器內部唯一的緩存,則其性能將突然崩潰。這就是為什麼它們都在內核中內置了另一級內存的原因:二級緩存。這是一個通用的存儲塊,保存着指令和數據。
它總是比級別1大很多:AMD Zen 2處理器的最大容量為512 kB,因此可以保持較低級別的緩存的良好供應。但是,這種額外的大小需要付出一定的代價,而與1級相比,從此緩存中查找和傳輸數據大約要花費兩倍的時間。
追溯到最初的Intel Pentium時代,Level 2高速緩存是一個單獨的芯片,其位於小型插入式電路板上(例如RAM DIMM)或內置在主板中。最終它像奔騰III和AMD K6-III處理器一樣,一直運用於CPU封裝本身,直到最終被集成到CPU裸片中。

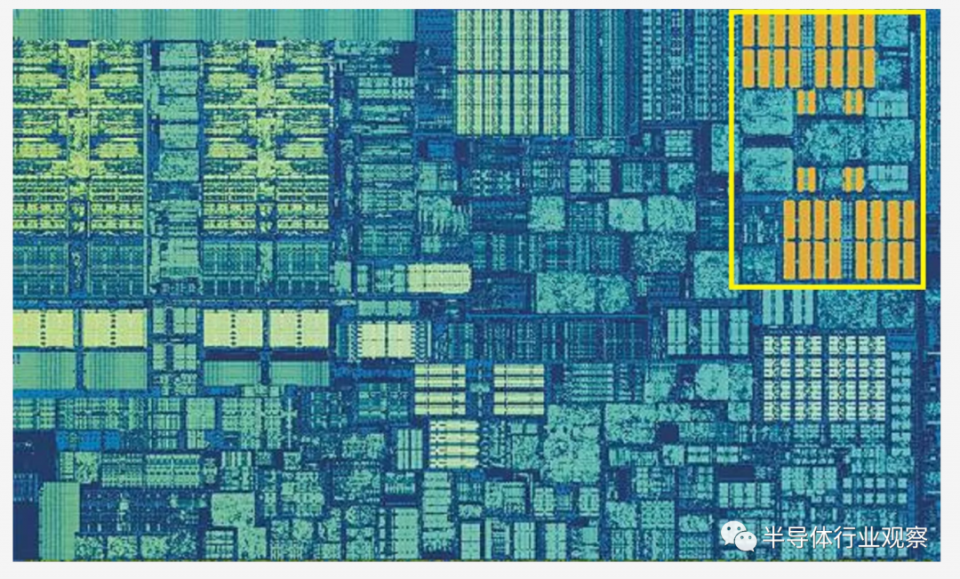
由於多核芯片的興起,這項發展很快之後又有了另一個級別的緩存,以支持其他較低的級別。
上圖是Intel Kaby Lake芯片,其左中間有4個內核(集成GPU佔據了右側一半的裸片)。每個內核都有其自己的“專用”組1級和2級緩存(白色和黃色高亮顯示),但它們也帶有第三組SRAM塊。
3級高速緩存即使直接圍繞一個內核也可以與其他內核完全共享-每個都可以自由訪問另一個L3高速緩存的內容。它 內存更大(在2到32 MB之間),但也慢得多,平均超過30個週期(尤其是在內核需要使用相距一定距離的緩存塊中的數據時)。

在下面,我們可以看到AMD Zen 2架構中的單核:白色的32 kB 1級數據和指令緩存,黃色的512 KB 2級緩存和紅色的4 MB巨大塊L3緩存。
不只是一個數字
高速緩存兩個環節:其一是來提高性能通過加速向邏輯單元的數據傳輸,其二是保留常用指令和數據的副本。緩存中存儲的信息分為兩部分:數據本身以及它最初位於系統內存/存儲中的位置。此地址稱為緩存標籤。
當CPU運行要從內存讀取數據或向內存寫入數據的操作時,它首先檢查1級緩存中的變量。如果存在所需的數據(緩存命中),則幾乎可以立即訪問該數據。當所需標籤不在最低緩存級別中時,即緩存未命中。
因此,在L1高速緩存中會有一個新標籤,其餘的處理器體系結構將接管,盡數瀏覽其他高速緩存級別(如有必要,一直返回主存儲驅動器)以查找該標籤的數據。但是要在L1緩存中為該新標籤騰出空間,必須將其他內容始終引導到L2中。
這導致了幾乎恆定的數據改組,所有這些都只需要幾個時鐘週期即可實現。實現此目的的唯一方法是在SRAM周圍構建一個複雜的結構,以處理數據管理。換句話説,如果一個CPU內核僅由一個ALU組成,則L1緩存會簡單得多,但是由於ALU有數十個(其中許多將處理兩個指令線程),因此緩存需要多個連接來保持一切都在進行中。

您可以使用免費程序(例如CPU-Z)來檢查為自己的計算機供電的處理器的緩存信息。但是所有這些信息意味着什麼?一個重要的元素是關聯的標籤集。這與規則有關,這些規則取決於由系統內存中的數據塊複製到緩存的方式。
上面的緩存信息適用於Intel Core i7-9700K。它的1級高速緩存每個都分成64個小塊,稱為集合,並且每個小塊進一步劃分為高速緩存行(大小為64字節)。集相關意味着將來自系統內存的數據塊映射到一個特定集合中的高速緩存行上,而不是自由地在任何地方進行映射。
8向告訴我們,一個塊可以與一組中的8條緩存行關聯。關聯性級別越高(即“方式”越多),則當CPU搜尋數據時,命中高速緩存的機會就越大,並且減少由高速緩存未命中引起的損失。缺點是它增加了複雜性,增加了功耗,還可能降低性能,因為有更多的緩存行要處理一個數據塊。

高速緩存複雜性的另一方面在於如何在各個級別上保留數據。規則是在包含策略中設置的。例如,英特爾酷睿處理器具有完全包含的L1 + L3緩存。例如,這意味着第1級中的相同數據也可以在第3級中。這似乎在浪費寶貴的緩存空間,但是好處是,如果處理器在搜索低級標籤時出錯,數據就會丟失,而不需要遍歷更高的級別來找到它。
在同一處理器中,L2緩存是非包含性的:存儲在其中的任何數據都不會複製到任何其他級別。這樣可以節省空間,但確實會導致芯片的存儲系統必須搜索L3以找到丟失的標籤(實際上總會比這個更大一些)。受害者緩存與此類似,但是它們習慣於存儲從較低級別推出的信息-例如,AMD的Zen 2處理器使用L3受害者緩存,該緩存僅存儲來自L2的數據。
還有其他用於緩存的策略,例如何時將數據寫入緩存和主系統內存。這些稱為寫策略,當今大多數CPU使用回寫式緩存。這意味着,當將數據寫入高速緩存級別時,在使用其副本更新系統內存之前會有一個延遲。在大多數情況下,只要數據保留在高速緩存中,此暫停就會一直運行。只有將其引導後,RAM才會獲取信息。

對於處理器設計者而言,選擇高速緩存的數量,類型和策略都是為了平衡對更大處理器能力的需求與增加的複雜性和所需的芯片空間。如果有可能擁有20 MB,1000路完全關聯的1級高速緩存,而芯片又不大的離譜(並消耗相同的功率),那麼我們都將擁有配備這種芯片的計算機!
在過去的十年中,當今CPU中最低的緩存級別並沒有太大變化。但是,級別3緩存的大小仍在繼續增長。十年前,如果您幸運地擁有一台售價999美元的Intel i7-980X,則可以獲得12 MB的內存。如今,您只需花一半的錢就能得到64 MB。
簡而言之,緩存是不可或缺的,也是尖端技術的體現之一。我們沒有研究過CPU和GPU中的其他緩存類型(例如轉換查找緩衝區或紋理緩存),但是由於它們都遵循我們在此介紹的簡單的級別結構和模式,因此聽起來可能並不複雜。
您是否擁有一台在主板上具有二級緩存的計算機?子板中的那些基於插槽的Pentium II和Celeron CPU(例如300a)怎麼樣?您還記得您的第一個共享L3的CPU嗎?請在評價部分留下您的意見。