大數據如何塑造材料科學家的新世界?_風聞
中科院物理所-中科院物理所官方账号-2020-09-14 08:02

01
大數據塑造你我的世界
中午,工作結束的你點起了外賣。打開軟件,發現列表推薦的前幾家都是你愛吃的。於是,你享受了一頓愉快的午餐。
下班時,北斗導航系統為你規劃了一條與平時不同的路線。回到家後,你發現今天的駕駛意外順利,平時總會遇到的堵車沒有發生。
晚上,你打開昨天外語課的作業。你的作文又沒有及格。不過,批改軟件早已把文章的錯誤盡數標出,並提出了更好的修改,加深了你對語法的理解。

信息社會,大數據無處不在
擁有掌控這一切的能力,正是數據。確切來説,是“大數據”。當今信息社會中,每個人的生活都會留下一串數據,而萬物的互聯互通也都是基於各類數據。醫生依靠大數據做出更精確的診斷,法官依靠大數據在簡單案件上節省精力,而軟件公司則通過大數據為你定製出最個性化的服務……我們每個人,都在貢獻數據,同時被大數據所塑造。
從這點來講,材料科學家們也不例外。在材料科學領域,數據作為記錄材料信息的一種方式,已經變得越來越普遍。過去,材料科學是實驗室中的不斷進步的。為了製造出穩定、明亮的電燈,愛迪生做過幾千次試驗,才發現了合適的燈絲材料鎢。而現在,人們發現材料中原子及排列可以決定材料的內在性能,更多理論模擬的方法可供利用,很多材料性質可直接預測。材料科學家們便像“鋼鐵俠”一般,隨心所欲地創造新型材料。

像鋼鐵俠一樣研究材料科學
實驗技術結合計算機模擬來研究材料組份、結構和性能,已成為一種快捷有效的常規方法。特別是很多情況下,普通實驗手段幾乎失效,計算材料學可以充分發揮其優勢。不僅如此,當材料大數據積累到一定程度時,越來越多的內在規律將被揭示,各式各樣、種類繁多、功能強大的新材料將會浮出水面。就像“人類基因組計劃”破解了生命的密碼,基於材料計算和數據庫的“材料基因組計劃”,將會極大地加速材料的研發**,降低材料發現的門檻和成本,促進人類社會的進步**[1]。新材料研發模式正在從“經驗型”向“預測型”轉變。

理論計算可以使材料研發過程速度加快,成本降低
隨着的信息技術的發展和材料模擬領域的進步,人們可以通過高通量計算在短時間內獲得大量數據,並利用它來篩選和設計新材料,從而大幅加速材料研發速度,降低材料研發成本。
02
材料基因:從出現到百花齊放
材料的進步代表人類的進步。早在20世紀80—90年代,國內外不斷有科學家提出有關材料基因的基本理念。“材料基因組計劃”由美國在2011年率先提出,旨在利用在材料計算、模擬和數據挖掘方面的突破,提高新材料發現的速度,降低成本,進一步發揮實驗技術的效能。此概念一經提出便引起重大反響。以鋰離子電池材料開發為主要方向的勞倫斯伯克利國家實驗室的Kristin A. Persson教授和Gerbrand Ceder教授系統性地把材料基因的思想用於鋰離子電池材料的開發,發現了許多性能優異的新型電極材料,是早期材料基因工作的代表。[2]不僅如此,該國家實驗室的科學家們劃時代地將所有涉及的晶體結構的計算數據統一放置在了一個數據庫平台中。數據平台的出現有效減少了重複計算的次數,增加了計算機智能判定,為後續的科研工作者提供了極大的便利。這個數據平台就是Materials Project [3]。

若干業界領先的世界級材料數據庫
針對不同類型或功能的材料,人們研究的熱點往往有所不同。於是,更多的材料數據庫出現了。為了在大數據範圍內研究各類合金的性質和功能,西北大學的科學家們建立了OQMD數據庫[4];為了發現更多新材料,杜克大學的Aflow數據庫應運而生[5]。石墨烯的成功剝離使人們拓寬了對低維度材料的認識,經過十幾年的發展,來自瑞士洛桑大學的課題組已經建立起二維材料數據庫[6],涵蓋所有已知二維材料的性質。美國、歐洲、日本的眾多課題組都已加入各類材料數據庫的開發,材料基因組在科研界掀起了熱潮。
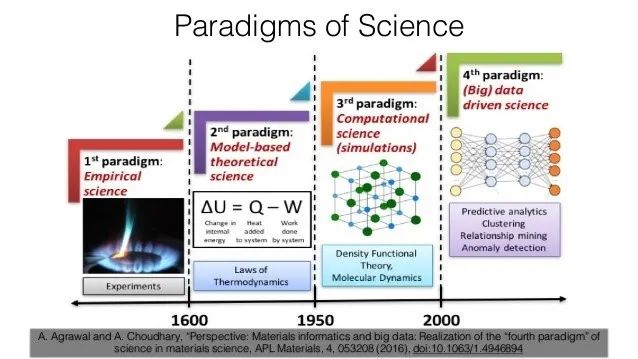
材料科學的發展新趨勢:從“基於實驗的經驗型模式”向“基於數據的預測型模式”轉變
國外如火如荼,國內也毫不遜色。2016年初,科技部正式發佈“材料基因工程關鍵技術與支撐平台”的重點研發計劃,很多大學和科研院所都搭建起具備材料計算和材料合成的設備,加入材料基因探索的浪潮。[1] 近年來,針對某些具體問題或性質的材料基因計算研究論文相繼上線,國內對材料大數據的研究已初具規模。
但是,與擁有大量基礎的歐美相比,我國在材料計算方面有着全方位的差距。然而,新材料的研發與應用反映了一個國家的科技競爭能力,對國家安全和社會經濟發展有着重大意義;只有全面、精確、規模化的材料數據庫的建成,才有可能更有效地指導新材料的研發和突破。在這一點上,中科院物理所近期上線的“Atomly”數據庫,一步到位地填補我國沒有世界級材料數據庫的空白。
03
Atomly上線,
或是材料基因研究的下一塊拼圖
Atomly(https://atomly.net), 是中科院物理所最新原創的材料數據庫。作為材料數據庫中的“後起之秀”,它不僅集各個前輩之大成,而且還在某些方面超越了它的前輩們,甚至實現了諸多創新功能。Atomly的特點如下:

Atomly.net數據庫上線,主界面如圖所示(需註冊)
1. “更多、更強”的數據
到目前為止,Atomly已經計算了14萬多種材料的相關數據,這些材料包含了經過數據庫比對去重後的無機晶體結構數據庫 (ICSD) 中的大部分結構,該數據庫在實驗合成及晶體研究領域久負盛名,也包含了一大批以往DFT計算研究中提出的假想結構。因此,Atomly內含的材料數據不僅全面,而且和材料實驗的聯繫十分緊密。

Atomly材料數據庫目前的數據條目統計
在此基礎上,我們得到了其中14萬多種材料的詳細電子結構信息(能帶,態密度等)以及近4萬組熱力學相關的相圖。這些數據可以讓人們更深入地瞭解材料的相關性質,並能充分利用這些精度統一的信息去助力新材料的研發與探索。

Atomly數據庫目前涵蓋的信息
2. 個性化計算服務Run4U
材料數據庫的用户們,物理背景往往並不相同,有些用户不熟悉第一性原理計算軟件,或者想便捷的瞭解我們數據庫中未包含結構的性質。因此,我們開發了Run4U這一功能。這一功能支持用户在線自主上傳新的結構,我們的後台會對這些結構進行初步的篩選,如果數據庫中真的沒有包含,就會自動進行第一性原理計算,2-3天后用户便可在列表中看到想要的計算結果。使用Run4U功能時,用户無需購買軟件、計算資源,也無需掌握學習DFT的計算細節;同時,計算的結果可以自動被後台分析入庫,可複查、複用。Run4U的設計對用户非常友好,其流程如下圖所示。
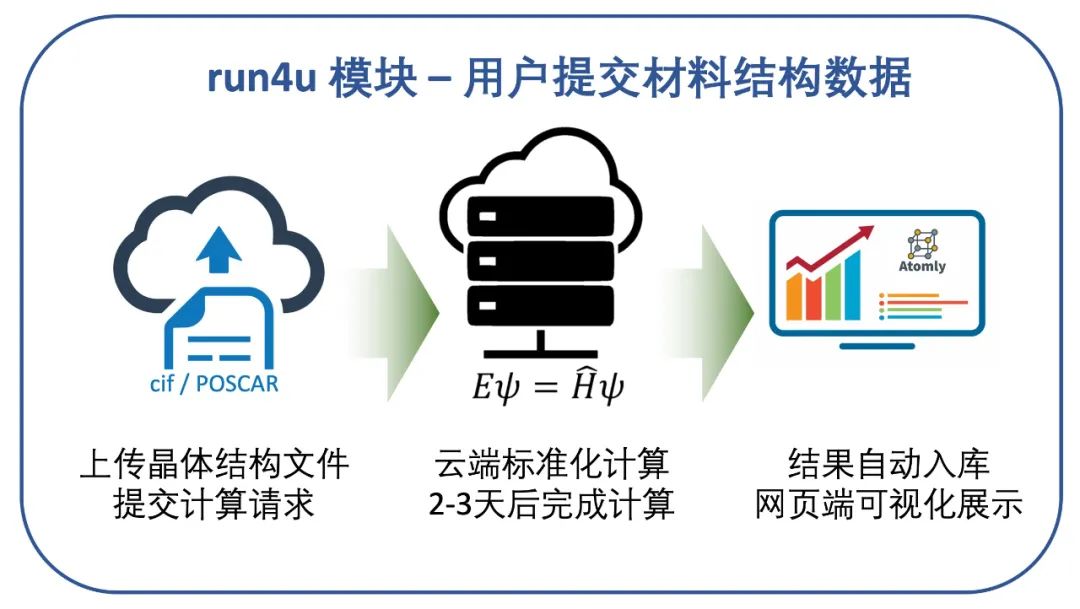
run4u,用户提交結構並計算
3. 創新型材料設計方法

“地毯式”全庫材料搜索示意圖
(1)通過高通量計算生產材料數據,進一步從數據出發搜索新材料。此類方法已有成功案例:過去70年人類平均每年發現3.3個氮化物材料,加州大學伯克利分校的Ceder組通過高通量計算等材料大數據方法,一年內發現92種有可能材料,並用實驗合成7種。[7]
(2)機器學習勢函數作為近年來迅速發展的學科,正在逐漸展示其優越性。在分子動力學中,對於傳統勢函數而言,往往缺乏一定的精度,這導致在時間步長的積累之下,勢函數帶來的“誤差”將逐步積累,最終將給出一個錯誤的結果。而機器學習則可以利用DFT計算的數據進行擬合,得到的模型可在給定相應構型的情況下,預測出相應的物理屬性,例如能量,力等。基於Atomly材料數據庫內的大量數據,我們開發了一套精準的機器學習勢函數工具包(Highly Accurate Artificial Intelligence Force Field, 簡稱HAAIFF),可以精確擬合分子動力學中所需的體系能量,原子受力等參量。在保證精準的前提下,我們對程序包進行了優化,使其可在GPU上進行訓練以及預測,極大的提高了該機器學習勢函數的速度,為運行分子動力學提供了便利。使用户同時獲得密度泛函理論計算的精度和經典分子動力學的速度。該工具包可供用户進行自行使用,同時,為了節省用户收集DFT計算數據帶來的成本,我們提供了由該工具包訓練的機器學習勢函數庫,用户可在這些函數庫的基礎上,再次二度訓練,以此既可以節省收集數據時間,又可以擴增機器學習勢函數適用範圍。以下為HAAIFF訓練金屬鎢體系例子(含BCC和FCC的超胞結構,展示了HAAIFF高精度的特性)。我們將於不久的未來發布這一方法及程序包。

HAAIFF實現高精度勢函數訓練
(3)通過分析大量材料數據,通過機器學習歸納出形成能預測模型,可用迅速判斷新材料的形成能和結構穩定性等,從而指導新材料設計、合成難度程度預測等。

通過對atomly數據庫學習得到的材料形成能預測模型
04
迅速達到巔峯,
物理所材料基因未來可期
放眼全球,材料計算已經成為指導新材料研發的常規方法,而各類新奇的材料數據庫像雨後春筍一般不斷被開發、報道。這其中最具代表性的計算材料數據庫,便是前文中提到了Materials Project、OQMD和Aflow。但是,這些庫近年來發展明顯放緩,數據質量也參差不齊。例如,OQMD包含大量易於計算的合金材料,但對離子化合物的相圖刻畫非常不全面;Materials Project****只有50%的結構擁有電子結構信息,且近期數據增長放緩。

材料數據庫幕後的軟件體系
材料基因工程是物理所近期佈局的重要發展領域,藉助物理所在材料計算方向的積累和特色,結合了物理所、松山湖材料實驗室、懷柔材料基因平台的優勢力量,Atomly發展迅速,從開始構建到上線的1年多時間內,已經完成了對14萬個材料的高精度計算,每個材料的電子結構等基本信息方面十分全面且精確,迅速站在了世界材料數據庫界的巔峯。就目前而言,初版上線的Atomly整體已非常優秀。但是,Atomly的上線僅僅是一個開始。目前仍有數以萬計的新結構正在計算,各材料的介電函數、聲子譜等重要且獨特的物理信息也正在上線的路上。在擁有材料大數據積累的前提下,機器學習等更多新型人工智能方法將使材料數據庫的整體性和優越性不斷完善和提高,為新材料的研發提供更加智能的捷徑。
材料科學蓬勃發展,材料探索永無止境**。**Atomly還有很大的成長空間,物理所材料基因研究未來可期。Atomly將保持世界巔峯水準,與其他優秀的材料計算數據庫一道,為我國乃至全世界材料科學家們探索材料基因、研發新型材料打下堅實的基礎。
備註:
文中提交的材料計算基礎設施及數據庫由中國科學院物理研究院、松山湖材料實驗室、懷柔材料基因組研究平台的科學家共同完成。

懷柔材料基因組研究平台
參考:
[1] 材料基因/孟勝,劉行編著;遼寧省科學技術協會組編.—北京:科學普及出版社,2017.2
[2] Aydinol M K, Kohan A F, Ceder G, et al. Ab initio study of lithium intercalation in metal oxides and metal dichalcogenides[J]. Physical Review B, 1997, 56(3): 1354.
[3] Jain A, Ong S P, Hautier G, et al. Commentary: The Materials Project: A materials genome approach to accelerating materials innovation[J]. Apl Materials, 2013, 1(1): 011002.
[4] Saal, J. E., Kirklin, S., Aykol, M., Meredig, B., and Wolverton, C. “Materials Design and Discovery with High-Throughput Density Functional Theory: The Open Quantum Materials Database (OQMD)", JOM 65, 1501-1509 (2013).
[5] Curtarolo S, Setyawan W, Hart G L W, et al. AFLOW: an automatic framework for high-throughput materials discovery[J]. Computational Materials Science, 2012, 58: 218-226.
[6] Mounet N, Gibertini M, Schwaller P, et al. Two-dimensional materials from high-throughput computational exfoliation of experimentally known compounds[J]. Nature nanotechnology, 2018, 13(3): 246.
[7] Sun W, Bartel C J, Arca E, et al. A map of the inorganic ternary metal nitrides[J]. Nature materials, 2019, 18(7): 732.