預測不準確?_風聞
非凡油条-非凡油条官方账号-深度解读全球政治财经动向的前因后果2020-11-05 12:58

技術有其邏輯
個人信息保護法已經來了,但是已經沒人抱有希望,該拿到的都得到了,不該拿到的也悄悄留下了。
畫個像,錄個音,慢慢開啓攝像頭,記錄下你的路徑,保存下你的輸入歷史,真正做到了百花齊放。
海量的數據養育了人工智能,那人類的角色究竟是什麼?
答案呼之欲出,人肉乾電池,餵養數據培育巨頭,獻完青春獻子孫,忠貞不二愛國情。
今天就好好跟大家嘮嘮我們為啥會變成人肉乾電池。
我想先給大家説幾個人名,圖靈、香農、貝塔朗菲和維納。
圖靈在二戰破譯德軍密碼的時候搞出了圖靈機,香農闡明瞭信息論,告訴我們信息是如何流動的,貝塔朗菲發展了系統論,也就是認為工程需要複雜條件和要素的合理配置,維納是控制論的代言人,信息流通也好,複雜計算也好,都不是無目的的狂想,而是奔着某種目標去的。比如錢學森老先生,就是工程控制論的行家裏手。
正是在這些人的鼓搗下,我們今天的計算機、互聯網媒體才真正發展起來,但是因為他們的理論門檻過高,長時間裏這些人和事並不為人所知,也只有圖靈因為圖靈計算機科學獎還算盛名在外。
而今天我們説到大數據和人工智能,好像都是非常fashion的概念,2016年阿爾法狗戰勝李世石真正讓AI成為人盡皆知的新名詞,而這些大師和他們的所學好像更是非常久遠的存在。
其實這是錯覺,第一屆人工智能大會是在1956年於英國達特茅斯召開,基本上和大師們是同時代的存在。

**☉**圖靈死於毒蘋果,原因就不多説了
理論是理論,現實中計算機組成的集大成者,採用的都是馮·諾依曼架構,這位老兄在參加曼哈頓工程的時候就意識到,當時的計算機結構有點問題,主要是不通用。
這裏的不通用的意思就是以往的計算機是特定類型的計算工具,而且用途單一僅是用於計算的機器,比如今天的超級計算機,功能很強大,但要是拿來打遊戲顯然是不太行的。
就這麼理解吧,超級計算機就是算盤的終極態。
而馮諾依曼架構簡單來説,就是分門別類,把計算機各部分該幹啥都預先設計好,需要哪塊就用哪塊,管輸入就專管輸入,計算就靠CPU(中央處理器),比如文字處理,一般就用CPU就夠,但要是打遊戲或者畫圖,最好還是配塊GPU。
所以現代的計算機不單單是用於計算的機器,這也是現代計算機可以通用化的真正原因,個人PC、芯片製造商也就此發家。
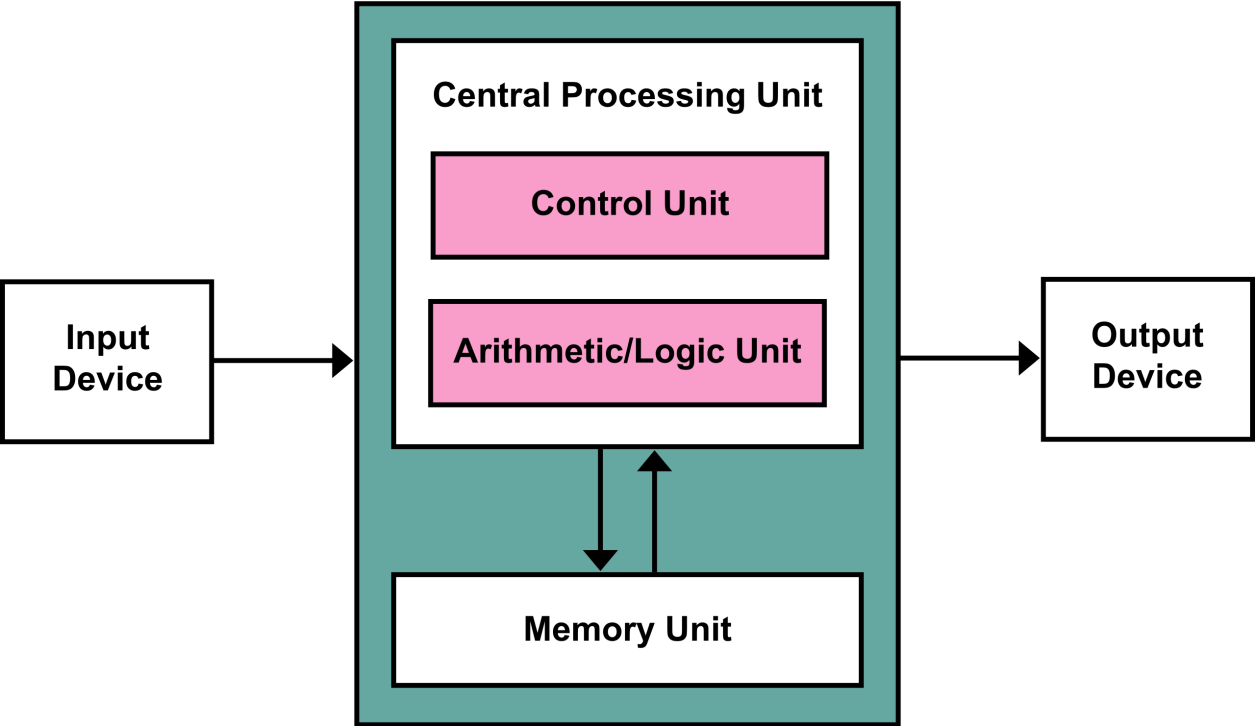
**☉**手機、電腦和超算,基本都在這個框架下各自發展。
機器總歸是要幫助我們處理信息完成工作的,這時候需要召喚二進制。所有的信息和數據,不管文字還是視頻從底層來説,都是0和1組成的,所以Word文檔能和虛幻引擎在一台電腦上共存。
也有不信邪的,比如蘇聯老大哥搞過三進制,0和1,還有個-1,1958年造出過三進制計算機Сетунь,但是老大哥市場化動力不足,最終項目無疾而終,起了個大早,趕了個晚集。
至於那些量子計算機、光學計算機等奇形怪狀,先挖個坑,有空再嘮。
到這個階段,計算機算是發展的明明白白了,在技術的推動下,人類進入了互聯網文明,發展出了互聯網經濟,工業時代需要的是電力和石油,而信息時代需要的是數據。
大自然當然是長不出數據來的,唯一能“供電”的,就是你我以及諸位了。所以不要覺得是大數據時代我們的個人隱私才具有價值,它們一直都是寶貴的財富(生產要素),只是大數據和人工智能讓這一切變得更顯性和便捷了。
從計算機走向消費品的那一刻起,就註定會有這麼一天,這是技術發展的自生邏輯,不因我們的個人意志而改變。
孩子大了
現代計算機和人工智能起源於20世紀中葉,到現在已經是長大成人,按照馮諾依曼的架構原理,需要處理的內容是越來越多,那就加模塊。
水多了加面,面多了加水。
第一次注水,是GPU的出現,原名叫做 Graphics Processing Unit,直譯為圖形處理器,俗稱顯卡,是CPU發展到一定階段出現的補充物。
CPU一般負責通用計算,簡單理解就是算數,但是隨着計算機的發展,尤其是Windows系統的攻城略地,圖形化界面(GUI)以及立體模型的需求越來越多。這其實也符合人性,DOS系統和原生Linux那種對着命令敲代碼的電腦用法,絕對不如直觀的東西看着舒服,普通老百姓顯然不會喜歡。
有需求就有市場,1999年英偉達發佈GeForce 256,而且GPU這個名字也是從此開始大規模運用。具體參數就不報了,今天看來就是玩具,重要的是它開創了GPU這個概念。
今天在電腦上配有獨立顯卡還能當個賣點,但是手機一般就會搞集成設計,比如SoC,高通、海思家的產品都是如此,這是因為手機空間有限,一寸空間一寸金,能省就省。
另一個原因就是手機是純圖形化的,對於GPU的運算需求更普遍。我想大家沒見過拿着手機敲代碼的吧。
現在,還是英偉達,花了69億收購了以色列Mellanox後推出了新的數據處理單元DPU,即Data Processing Unit,產品名BlueField-2、BlueField-2X,英偉達這次目的很明確,再複製一把GPU的輝煌。
**☉**人類的本質是復讀機,有需求就造一個
先別激動,成不成還兩可呢,數據時代肯定會到來,巨頭們都在跑馬圈地,但未必DPU就會是最後的贏家,因為入局的實在是太多了。
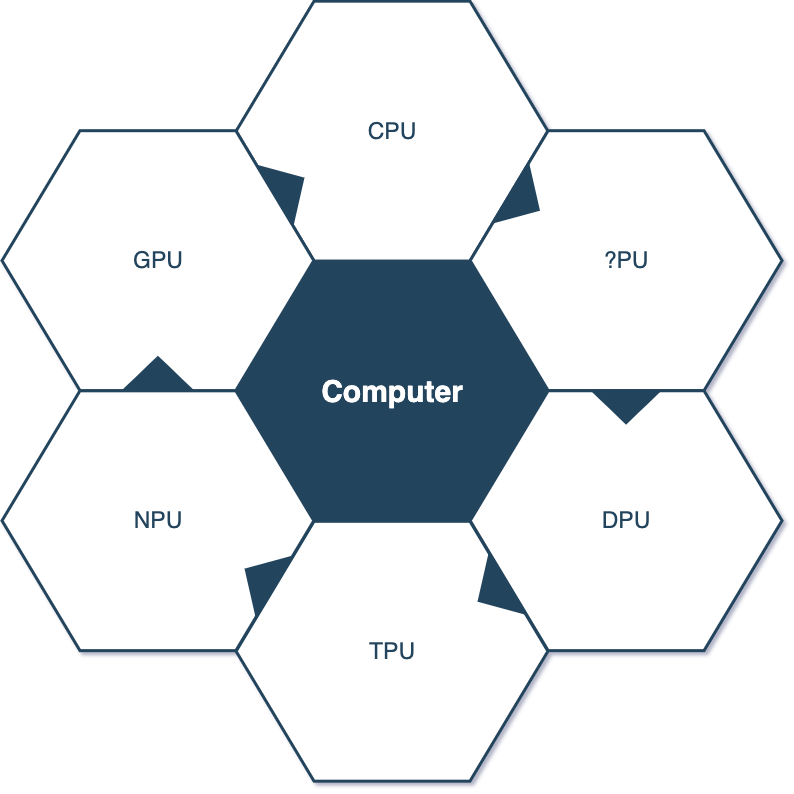
CPU/GPU/NPU/TPU/DPU,把這一堆放到你眼前,讓你猜一猜他們都是幹啥的,誰又能在數據時代笑到最後呢?
現在機器學習CPU也能做,但是數據吞吐量很有限,學生學習還好説,真正搞研究和工程應用,比如把用户數據拿到了怎麼分析,一般還是要上GPU。CPU幹一天的活,GPU幾個小時就搞定了。
而到了人工智能要具體落地的時刻,比如麒麟810要應用神經網絡,華為的策略是開發自己的嵌入式神經網絡處理器,實際上就是NPU,neural-network processing units,專門負責有關圖像視頻等內容的學習。
如果你是華為手機用户,那麼相冊中圖片中分類功能就是由NPU來完成的,一般宣稱不用上傳雲端即可實現,靠的就是NPU本身的強大。
還有iPhone最新的A14芯片,裏面也包含神經運算單元,蘋果稱之為神經引擎(Neural Engine)和機器學習矩陣加速器(machine learning matrix accelerators)。每秒可以執行11萬億次算術任務,最新制程5nm,16個核心,基本上可以説是目前的手機處理器的算力巔峯了。

**☉**像Intel擠的牙膏?
而谷歌還有自己的TPU,中文名為張量運算單元,Tensors Processing Unit,是專門用於機器學習的處理器,配合自家的TensorFlow機器學習框架有奇效。
總算是説清楚這一堆PU是什麼東西了,本質上他們都是數據處理模塊,只不過用的頻繁,各個廠家給獨立出來了。
大數據時代真的要來,但疊牀架屋還適合時代發展的要求嗎?
現在廠家還在思考這個問題,但是Intel、高通等已經聯合起來反對英偉達收購ARM,顧慮的就是萬一英偉達控制手機+電腦端的數據處理芯片,那時候大家都得聽英偉達。
而我們的角色是人肉乾電池。不管怎麼説,數據是人工智能真正的關鍵所在,因為深度學習的數學原理依舊是黑箱狀態,現在可行的路徑就是堆數據,本質上是對概率的預測,而不是邏輯的推演。數據不夠多的話,預測就容易不準確了。
這個孩子要長大,需要餵養更多的奶水,我們多刷手機也算是為人類做貢獻了。
本回完