這個小AI後來學會了一些奇技淫巧,我們看到以後就第二次地崩潰了_風聞
观察者网用户_239515-2020-11-24 10:09
來源:一席
吳翼,清華大學交叉信息研究院助理教授。
AI很聰明,但是它也依然很懶,所以距離AGI還有很長一段路要走。
嘿!AGI
2020.10.24 北京
大家好,我叫吳翼, 我2014年從清華大學交叉信息研究院畢業,2019年在加州大學伯克利分校獲得計算機科學專業人工智能方向博士學位,今年8月份,我又回到了清華,加入了交叉信息研究院 。
我回國前在舊金山一家叫OpenAI的小公司工作了一年半,有人就要問了,硅谷有谷歌、Facebook、微軟,為什麼這些大公司我一個都沒去,就去了這麼一家小公司?
介紹一下我們公司。OpenAI是一個非盈利的研究性創業公司,它的主業就是研究AI算法,一開始是由伊隆·馬斯克出資創立的。當然了我自己並沒有見過伊隆,我入職的時候他就已經離開董事會了。

我們公司的使命是創造通用人工智能,英文叫Artificial General Intelligence,縮寫是AGI。 大家就要問了,通用人工智能是什麼?它的定義有很多,通俗來説, AGI就 是一台具有跟人一樣智能的機器。
好像這個通俗的話還是有點抽象,我來舉一些例子,大家看看這些機器到底算不算有智能。
第一個是Siri,它算有智能嗎?
大家沒有什麼疑問,這肯定是算智能。我們來看第二個,百度地圖,算智能嗎?
好像有人猶豫,這個也是算的。再看下一個,這裏有一個小學奧數題,然後有個小機器人小藍,它告訴你這個算式的答案是79365。這算不算智能?

大家好像都在猶豫啊。 有一些小學數學掌握得比較好的同學會説,你這個題很簡單,就是每個漢字對應0到9的數字,那我們把每個漢字跟每個0到9的數字都去試一試,判斷一下哪個對,然後就是答案了。

沒錯,就是把所有可能性都去試一試, 這個“試一試”的學名,就叫做 搜索算法 , 它也就是人工智能剛開始研究時的主要算法。 搜索算法非常簡單,但是這個簡單的算法也確實給人工智能領域帶來了很大的突破。
比如説1997年,IBM就造了一台專門用來做搜索的機器,叫DeepBlue深藍,去挑戰了當時的國際象棋第一人卡斯帕羅夫,並且擊敗了他,利用搜索算法解決了國際象棋的問題。

當然了,國際象棋有很明確的規則,你知道每一步應該怎麼走。但是很多生活中的問題,並不是可以用這樣抽象的規則來表達的。比如説我給你一個圖片,這個圖片裏到底是小貓還是小狗呢?這是一個很難用很抽象的數學語言描述出來的問題,我們叫做圖像識別問題。

為了解決這樣一類很複雜的問題,人們提出了一個概念,叫 機器學習 。 在機器學習的框架裏面,你不再需要去描述非常抽象的規則,只需要給出足夠多的數據和標註。
比如這裏,你只要給它1萬張小貓的圖片和1萬張小狗的圖片,那這個AI就可以利用機器學習算法,自己分析和學習後,去判斷一個圖片到底是小貓還是小狗。

機器學習算法這些年取得了很多突破,但是它要依賴非常非常多的數據,並且你得告訴這個AI什麼數據是好的,什麼是壞的。但是你知道,現實生活中有很多的問題是沒有絕對的好壞的。
比如説我現在很渴,我希望一個機器人幫我送杯水,這個機器人是從左邊上台還是右邊上台,我不在乎,只要它把水給我,這就是好的。
再比如這個打磚塊的遊戲,我其實不在乎它怎麼玩,它只要能得高分就行了。在這種情況下,它每一步應該怎麼走,哪一步是好的,哪一步是不好的,很難説。我只知道它遊戲打完有個分,分數高就是好的,分數低就是不好的,這個就叫做智能決策問題。

這裏就又有了一個新的概念—— 強化學習, 強化學習是用來解決智能決策問題的算法框架,強化學習算法的核心就是讓這個AI不停地跟環境交互,不停地試錯,不停地改進自己,慢慢得到越來越多的分數。
2014年,英國的創業公司DeepMind,第一次將深度學習技術和強化學習的算法結合,在一系列這樣的80年代小遊戲上都超過了人的表現。

那之後的故事大家都知道了,DeepMind研發了一個圍棋AI——AlphaGO,它把強化學習和自我博弈結合了起來,讓這個AI不斷地自我博弈,不斷變得更強,然後擊敗了圍棋的傳奇選手李世石,後來又擊敗了柯潔,把圍棋項目給解決了。
當然我們知道,圍棋確實已經很難了,但圍棋和現實生活依然還是挺不一樣的。比如説圍棋棋盤對於雙方選手都是完全可見的,它是一個信息完全的博弈。再比如説在圍棋中落子,兩個選手一人落一子,並且只能放在棋盤上已有的位置,但是我們知道現實生活是一個物理的世界,我可以做的動作是非常複雜的。
那麼AI玩完了圍棋,它下一個遊戲應該玩什麼呢?
01 打DO TA
我們的答案叫打Dota——這是OpenAI在2017年的時候給AI設定的挑戰。
Dota是個挺複雜的遊戲,它有五個英雄,每個英雄有不同的技能,玩家還要買物品,和使用各種各樣的道具,需要在10分鐘到20分鐘非常長的一局遊戲裏面,用非常複雜的策略去擊敗對方,這是很困難的。
我們公司從2017年開始做這個項目,經過了大概兩年多艱苦卓絕的努力,在2019年3月份的時候,發佈了最終版OpenAI Five。它和當時的世界冠軍團隊OG,進行了一場三局兩勝的表演賽。
▲ 注意音量,解説比較激動
這是當時跟OG對決的精彩畫面,OpenAI Five 十四分鐘上高地,最後這個情況基本上就是OpenAI Five的英雄壓制在了OG的老家門口,不停的屠殺他們的英雄。

最後這場友誼賽是OpenAI Five以2:0擊敗了OG,都沒有給OG第三局找回顏面的機會。 這是賽後的一個合影,前面的5個選手就是OG的5個成員,後面的是我們公司團隊的成員,挺有意思的。

▲ OG成員和OpenAI Five開發成員合影
更有意思的事情是,3月份OG被OpenAI Five擊敗之後,在當年的TI9總決賽上,OG衞冕成功,而且是以碾壓性的表現衞冕成功,成為了歷史上第一個雙冠王。後來OG的一個成員N0tail在推特上説,他們確實從OpenAI Five的策略上學到了很多新的技術和新的想法。
看起來AI的確很擅長打遊戲,它好像什麼遊戲都能贏人,那麼是不是在所有的遊戲上,AI都能比人強呢?
我的觀點是,基本上是這樣。 在Dota之後也有一些別的,比如説AlphaZero,也就是擊敗柯潔的AlphaGO的後續版本,它基本是以一個算法解決了所有的棋類問題。

然後卡耐基梅隆大學的團隊在德州撲克項目上也擊敗了職業的頂級玩家,後來DeepMind公司另一個打星際爭霸的AI——AlphaStar,也達到了頂尖級職業選手的水平。
所以 結論基本上是這樣的,只要有足夠的計算能力,並且遊戲的規則足夠清晰,AI都能超過人類。
這裏就有個問題,怎麼樣的計算能力算“足夠”呢? 以OpenAI Five為例,團隊每天使用256塊GPU和13萬塊CPU訓練它,AI每一天玩的遊戲量相當於一個人180年不吃不喝不睡天天打遊戲,錢也花了很多。再比如在AlphaGO Zero擊敗柯潔之後,Facebook復現了這個算法,他們也開發了一套自己的圍棋AI,叫OpenGO。他們是使用亞馬遜的雲平台進行計算的,大概訓練了一兩個月,每個禮拜訓練OpenGO的花銷超過100萬美元。
所以AI真的很燒錢,有時候可能也真的只有大公司才有這樣的財力去這麼燒錢。很遺憾,我也只有在OpenAI這一年半的時間裏面,才體會到了有錢人的快樂。但是也正因此,AI也讓一些公司賺得盆滿缽滿,比如説雲服務的公司亞馬遜,或者是造GPU的公司英偉達。
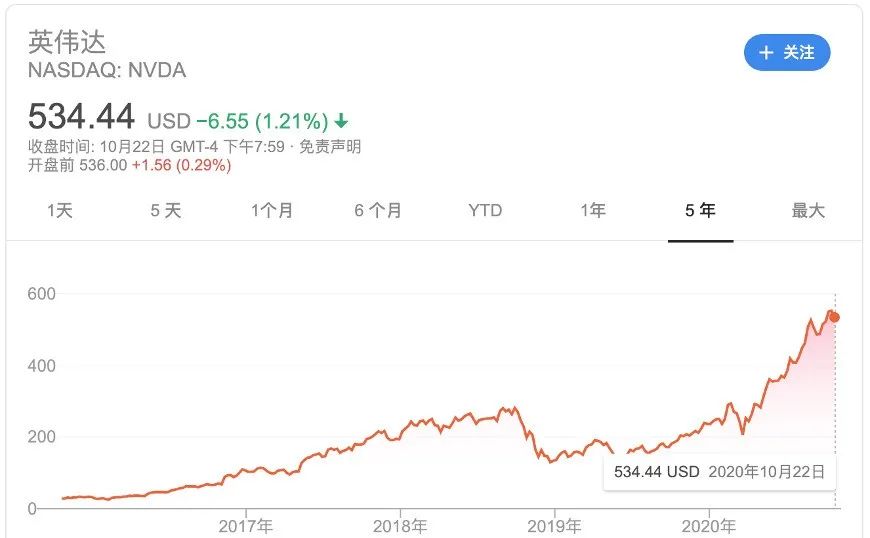
▲ 英偉達公司五年股價走勢圖
這裏有人就要問了,你説的這些東西都是打遊戲,那麼為什麼要花這麼大力氣教AI打遊戲呢?研究打遊戲對現實世界有什麼意義?
接下來我會講兩個具體的例子,來回答這個問題。
02 單手擰魔方
先看第一個例子,這個例子是之前在我隔壁的機器人團隊做的項目。在這個項目裏面,他們搞了一個非常精細的機械手,然後希望僅僅通過在模擬環境裏面訓練,就能讓機械手學會單手擰魔方。
這是一個很難的任務,大家想一想,一隻手擰魔方,這對人來説也是很難完成的,在當時沒有任何一個現有的機器人控制技術可以完成這個任務,而且他們還只是在虛擬世界裏、在遊戲裏面對AI進行訓練,卻能讓這個AI在現實生活中也可以工作。他們是怎麼做到的呢?
我們都知道,每一個遊戲世界和現實生活都是不一樣的,不可能完美的模擬現實生活,所以這個機器人團隊他們就做了這麼一件事情,他們乾脆創造了成千上萬個不同的模擬環境,每個模擬環境都有不一樣的物理參數。

比如説有的環境裏面可能重力稍微重一點,有的環境可能摩擦力小一點,有的環境可能魔方的體積大一些。他們把這個技術叫Domain Randomization,希望訓練AI在所有不同物理參數的環境裏面都能工作。
每一次訓練的時候,我們都隨機選一個環境,讓這個AI去完成魔方的任務,AI它不知道自己在什麼環境裏,但它為了要完成任務,就必須根據這個環境的動態反饋,來猜這個環境到底是什麼物理參數,然後不斷地調整自己的策略去適應這個環境。

所以我們用這樣的技術強迫AI學會了自我調整, 現實世界對AI來説,也不過就是另一個有着不同物理參數的虛擬環境,它也可以通過現實世界的實時反饋來調整它的策略,來不斷地 完成任務。
在訓練完成之後,我們也做了很多不同的測試,給機器人做了很多幹擾。比如説嘗試給它戴了一個橡膠手套,

把它的兩隻手指頭給捆起來,

給它蓋一個黑布,

或者用長頸鹿去戳它,

用馬克筆去戳它,

或者非常喪心病狂地用各種各樣的東西去幹擾它。

但這個AI也非常頑強,不管怎麼樣的艱難險阻,它都能完成任務。

所以有的時候想一想,AI也是蠻可憐的,不管什麼AI都註定要受到人類的不停摧殘,挺不容易的。
在機械手的例子裏面,我們想説明的是,只要你有足夠豐富的虛擬環境,有足夠多的計算,即使只在虛擬環境遊戲裏面訓練AI,那這個AI也是有可能在現實生活中工作的。
03 小藍和小紅
下一個例子我想説明的是,即使你只考慮遊戲的虛擬環境,AI也可以發現一些非常有趣的,跟人類社會活動非常相似的行為。這個工作是我自己參與的,叫捉迷藏。
這個項目裏我們首先創造了兩個非常可愛的小人,一個小藍和一個小紅,


然後我們又搞了一個虛擬的物理世界,讓小藍和小紅在虛擬世界裏面玩捉迷藏的遊戲。小藍人是Hider,它需要躲;小紅人是Seeker,它負責捉。
遊戲開始的時候,我們會讓小紅人先捂上眼睛不許動,讓小藍人先做好準備,然後比賽開始。每一次小紅人只要看到任何一個小藍人,那藍隊就扣一分,紅隊就得一分。如果規定時間內小紅人沒有看到小藍人,那紅隊就扣一分,藍隊就加一分。
我們使用強化學習算法,讓小藍和小紅在虛擬世界裏面不停的打遊戲,為了得高分相互PK。跟之前的項目一樣,我們又創造了成千上萬個這樣的平行宇宙,讓小藍和小紅瘋狂地玩捉迷藏。

下面我們來看一看,這些小AI到底發生了一些什麼樣有趣的行為和故事。遊戲一開始的時候,小紅很快就學會了追着小藍跑,
所以當時的小藍也非常慘,只能不停地躲,非常艱難。 但是小藍日夜玩了上萬輪捉 迷藏的遊戲之後,

它慢慢地 發現了一個 策略,那就是可以用箱子把門堵住,

在小紅捂住臉的時候,它會把門迅速地堵住。然後它們還學會了合作,如果有兩個門,大家就齊心協力把兩個門統統堵住。

當然了,用工具這件事情小紅也很快就學會了,在被小藍堵在門外堵了很久很久之後,小紅髮現了可以用這樣的策略——爬梯子,

很聰明吧?然後又過了一段時間,小藍逐漸地發現,我可以把梯子藏起來。

這裏我要強調一下, 所有這樣的行為,所有這樣的套路和反套路都是AI自己學會的,我們沒有進行任何的人工干預。
然後我們又把這個AI放到了一個更開放的環境裏面,在這樣一個開放的環境裏面,小藍很快學會了合作,它們會用很多這樣的長木板把自己給圍起來,同時把所有的梯子都放在邊緣把它鎖住,不讓小紅去動梯子。

我們一直以為這樣可能就是遊戲的終極策略了,但是很偶然地我們發現,經過很長時間的訓練,小紅髮現了一個非常神奇的策略,

雖然梯子被鎖住了,但是它站到了這個箱子上,然後騎着這個箱子就一路找到了小藍。後面我會解釋這個現象。
這個小藍最後也發現了反制的策略,不管箱子、梯子還是木板,全部都給鎖住,然後這樣就不會被看到了,

這也是我們在這個項目裏面觀察到的最後一個策略。
這所有背後的原理就是強化學習,我們讓小藍和小紅每天玩上百萬次捉迷藏,讓它們在上百萬次捉迷藏中不斷地改進自己,改進策略,變得更強。

雖然我們知道這個環境跟現實生活還是挺不一樣的,但是我們還是希望有一天,我們也有可能在這個虛擬環境裏面創造出AGI。

大家覺得這個事情怎麼樣,還不錯是吧?這個項目的視頻在YouTube上點擊率很高,有興趣的朋友也可以去我們公司的官網看看原版的視頻。
這裏我着重説一下這個Box surfing策略,這是我非常喜歡的一個策略,就是小紅人站到了箱子上,然後去找到小藍人,
這是我非常喜歡的,因為它是在我們這個項目一開始的時候完全沒有想到的。 那我們是怎麼發現這玩意兒的呢?其實這是一個偶然事件,有次這個實驗一直沒有關,結果我的同事有一天早晨去公司就發現,這個小紅人站到箱子上了。

這個行為其實跟我們物理引擎的設定是有關係的。在這個虛擬世界中,物理引擎是簡化的,我們預設了一個特定的動作叫“拿”,只要小人執行這個動作,系統就會默認這個箱子會和小人一起行動,就好像你拿了一個東西一樣。
所以這個小紅人做了件什麼事情呢?它先站到箱子上,再去使用“拿”這個行為,於是系統設定就判斷這個箱子會跟人一起行動,因此就變成了這個箱子馱着小紅人到處走。我們之前從沒有想過它可以這麼使用引擎的設定,所以這個AI真的是非常的聰明。
這是我們團隊的合影,公司給我們每個人都做了一個小紅和小藍的玩偶。

▲ 左二是發現Box surfing的那個同事
既然AI很像人,那麼AI總能跟人表現一樣嗎?我覺得大多數時候是的。捉迷藏這個項目也是想説明,只要你有一個跟現實生活差不多的開放的物理環境,再加上強化學習,那麼小AI就能夠自動地學出一些擬人的複雜策略。
但是也有例外,接下來給大家看一些,我們在這個項目開發過程中發現的一些非常有意思的意想不到的表現。比如這個是我們項目剛開始的時候發現的一個策略,叫Endless Running,超級跑跑。

在小紅捂住眼睛的時候,小藍就拽着兩塊板子當盾牌,瘋狂地向遠處跑走了。這其實是有道理的,因為你跑到很遠的地方後,別人肯定就看不到你。 但你知道,我們作為開發者就感到很崩潰,我們讓你好好玩遊戲,你怎麼就跑了?
那怎麼辦?沒關係,這個遊戲是我們寫的,我們可以定規則,所以我們後來就在這個遊戲的場地周圍搞了一個禁區,任何人進這個禁區就扣分。 所以你想跑是吧,我就不讓你跑,主宰人命運的感覺也是不錯的。
但是我們後來發現,當上帝也不是很容易。這個小人後來學會了一些奇技淫巧,比如它大概是發現了我們這個物理世界裏的一個小bug,然後就做了這樣一件事情,

▲ 看看小藍學會了啥
我們看到了當然就第二次的崩潰了。這可怎麼辦呢?就只能想辦法去修物理世界的參數,我們改了很長時間的參數,來保證這樣反人類的事情不要發生。
但是同樣的事情也發生在了小紅身上,你們看看小紅學到了什麼。

▲ 看看小紅學到了啥
我也解釋一下,這是因為我們的物理環境裏面,那個牆是一個鋼體,它的彈性非常大,所以小紅它就拽着一個梯子,然後使勁往牆上砸,那梯子就飛起來了。然後小紅它很聰明,它在梯子飛起來的前一刻跳了上去,就隨着梯子一起飛起來了。
它們倒是很高興,但是我們看到以後就第三次的崩潰了。我們想了半天,最後把這個環境的重力系數設成了50——一個巨大的重力系數,讓所有東西都飛不起來,終於解決了這樣的問題。
所以AI研究的日常生活其實就是這樣,一羣環境修理工人花着公司幾百萬美金,想辦法把一幫人工智障變成人工智能。
還有一件非常有意思的事情,在我們這個視頻發到網上之後,一個推特的網友問我們説,小藍人能學着用板子把自己圍起來,它為什麼不能把小紅人圍起來呢?小紅人捂着眼睛時候把它圍起來不就完了嗎?這是一個很好的問題,在原版的捉迷藏遊戲裏面,這個行為確實沒有出現,但是我們有個改版。
這是我自己做的實驗,在改版裏面我加了一些金幣,大家可以看到這些亮閃閃的東西就是金幣。

小藍人這次不光要保護自己,還得保護金幣,要是金幣被小紅人拿走了,小藍人也會被扣分。所以在這樣的情況下,它如果還只是把自己圍起來,就不足以保護所有金幣了,於是它就學會了這樣的行為。
其實我覺得最有意思的一件事情是,它們居然學會了用兩塊板子,而不是一塊去圍住。我們的猜測是,它們可能意識到了我們這幫上帝經常給它們寫bug,所以它們就用兩塊板子來保證不要出現意外,保證小紅會被鎖住。
所以AI真的很聰明,它可以經常發現一些人類想不到的行為和策略,甚至發現一些bug,然後利用這些bug做一些天馬行空的行為。但是我也要説,AI也很懶,它總是傾向於找一些最簡單的策略, 比如在之前的例子裏面,小藍把自己圍住就遠比把小紅圍住簡單,所以它只去想怎麼圍住自己。
很多時候AI科學家會絞盡腦汁讓這些小智障們變得聰明一些,所以如果你看到了一個聰明的小AI,那背後都是AI科學家掉的頭髮,和雲計算服務商賺得很鼓的腰包。
04 AI safety
既然AI很聰明,那我們就可以用AI去解決一些非常困難的問題。比如説這是OpenAI今年年初的時候發佈的一個音樂創作AI,它叫MuseNet,可以創造出各種各樣不同風格的音樂,我挑了一段兒肖邦風格的鋼琴曲,大家可以聽聽。
這個音樂是完全由AI自己創造的,沒有任何人工的干預,聽着還不錯是吧。
我有一個伯克利的朋友,他用AI來幫助做天文觀測,這個圖片是一個哈勃望遠鏡拍到的,

▲ 最下面一行是AI處理過的清晰的星系照片
哈勃望遠鏡拍到的圖片經常有一些宇宙的背景噪聲,他就用深度學習技術,把這些宇宙背景噪聲給去掉,就可以生成更加清晰的觀測圖。
再比如説今年年初的時候,麻省理工的團隊用AI技術發現了一種新的抗生素,這也是當時非常大的一個新聞。這些都是很有意思的一些應用。
這裏就有個問題了,就是AI這麼聰明,我們可以信任AI嗎?凡事都有兩面,我們怎麼保證AI永遠把聰明才智用在正道上?也有人説了,AI不就是可以拿高分嗎,都拿高分了還有什麼問題?其中一個很大的問題就是Value Alignment問題。
具體來説,人的價值觀一般是很複雜的,但是我們在訓練AI的時候,一般會給AI一個特別簡單的目標,比如説得高分,但是這個分數很難完美地反映出人的喜好,分數高並不一定代表着人類就滿意。
這裏我就舉一個我的導師Stuart Russell教授經常舉的例子,假設你家裏有一個非常聽話的機器人,有一天你去上班瞭然後跟機器人説:“我上班去了,你幫我照顧孩子,中午給他做飯,不能餓着孩子。”
然後到了中午,小孩跟機器人説我餓了,機器人收到了這個信號,就去做飯了。但機器人打開冰箱一看,不好,週末沒買菜,冰箱裏什麼都沒有,那怎麼辦?
這時候機器人頭一轉發現了你家的貓——一個充滿蛋白質和維生素的可食用物體。

▲ 圖源來自網絡
確實有點殘忍,但是你也不能怪這個AI,因為你跟它説的是不要讓小孩餓着,你也沒説不能打貓的主意。
所以人的價值觀是特別複雜的,你幾乎是不可能把你關心的方方面面都明明白白寫下來,然後全部告訴AI的。我自己都不能很自信地説我完全瞭解我自己,怎麼告訴AI呢?這是很難的。
雖然AI在大部分時候確實很通人性,但是它還是會經常出現一些問題,這個領域叫AI safety,人工智能的安全性,也是一個很新的研究領域。
有人可能在這裏要提出異議了:你不是説了嗎,AI都是人工智障,人工智障距離AGI還遠呢,有什麼好擔心的。
首先,因為AI跟生活已經結合得非常緊密了,我們到處都可以看到AI,所以即使只是用當今的AI技術,也可以找到很多AI犯錯的例子。另外一點也是我的導師經常説的,假如你知道在100年之後,火星會撞地球,地球要完蛋了,你難道會説再過30年再考慮這個問題嗎?你不會這麼想的。因為如果它是個大的問題,那就應該從現在開始就研究它。
這裏我也想介紹一下我的導師,Stuart Russell教授。

▲ 右邊是Stuart Russell教授
Stuart Russell教授他在2016年開始倡導AI safety的研究,當時他也在伯克利成立了一個新的研究院,叫Center for Human-Compatible AI。
Human-Compatible AI的基本論點是 AI算法不應該只是優化分數,它也應該知道自己的分數跟人的價值觀可能不一樣,然後應該以人的反應作為最終的目標。 俗話説就是,AI得知道自己是個人工智障,萬事先看看人,多問問,不要衝動,不要莽撞。
我舉個例子,假設你家裏有一個小機器人,然後你跟機器人説:“去門那兒!” 傳統的AI會説,那我找最短的路徑,它就一溜小跑去門那兒了,但是可能就把你家花瓶給撞了。
那Human-Compatible AI會怎麼做呢?它會先等等,先觀察一下人是怎麼做的。

它就發現人總是繞着花瓶走,這可能説明花瓶有詐,如果沒問題的話,為什麼人要繞着花瓶走呢?於是這個懷着敬畏之心的小智障,就戰戰兢兢地繞着花瓶走到了門那裏,非常完美。
當然我這裏要説的是,這是AI safety一個非常簡單的例子。人工智能的安全性問題是一個非常新的領域,任重而道遠。
從另一個角度來説,AI容易發現bug,其實在某些情況下也不錯。假設你有個系統,如果你派AI去能發現bug,然後人類再把它修好,那這個系統在真正運行的時候,它的bug不就少了嗎?舉個例子,我有幾個朋友這個夏天在用多智能體強化學習來模擬一個城市裏麪人口的流動,然後通過這個來分析新冠病毒的傳播,以及我們防疫系統裏面可能的問題,來幫助我們做防疫。
當然了,未來或許還有更多這樣的社會科學問題可以用強化學習的方法去模擬計算和分析理解。但是我還是要再提一句,AI很聰明,但是它也依然很懶,所以距離AGI還有很長一段路要走。
05 一些願景
最後我想聊一聊我們這些AI的從業者,也是我們交叉信息研究院的一些看法和願景。
我先介紹一下我們院吧。 我們院是唯一的華人圖靈獎得主姚期智先生創辦的一個學院,我們院的使命是培養中國的計算機科學家。
AI的普及和利用是一個歷史的潮流和趨勢,我們不管AI到底是一個新的產業革命,還是隻是人類歷史長河中一個特別小的波濤,不管好還是壞,AI總是和我們的生活越來越緊密,越來越不可分割了。AI會改變越來越多的行業,也會對我們的生活和生產方式產生越來越多的改變。
那明天會怎麼樣呢?有人説AI會讓很多人失業,有人説AI可能會產生新的壟斷階級,會壟斷教育、壟斷資源、壟斷技術,但是與此同時,AI的發展也會產生新的行業,會產生新的工作機會和工作形式。我們作為AI的從業人員也希望用我們的努力去普及AI, 去打破這樣的壁壘,讓更多的人能瞭解AI,瞭解AI背後的原理,瞭解AI到底想幹什麼。
作為教育工作者,我們也希望利用AI帶來的機會和行業的發展, 去讓這個世界更公平,讓社會更進步。 姚期智先生帶領我們院的老師們也朝着這個目標做了一些努力,最近我們一起寫了一本關於人工智能的中學教科書,希望中學生可以完全沒有壁壘的全面的科學的瞭解AI,瞭解AI背後的原理。如果一切順利,在今年年底或者明年年初, 這本書就會跟大家見面。
我還記得當時姚先生跟我聊,為什麼要做這麼一件公益的事情。大致的對話內容是這樣的,教育的普及和推廣,如果我們這些教育工作者不去做的話,那就一定會有壞人去做,如果是這樣,那還不如我們率先去把它做好。

這就是我今天分享的內容了,很感謝大家捧場,也希望有一天AGI能夠真的到來。謝謝大家。