百度CTO王海峯:語言與知識佈局始終要把握兩大趨勢
【環球網科技綜合報道】“在百度語言與知識技術的佈局和發展中,我們始終在注意把握兩個趨勢,即技術發展趨勢和產業發展趨勢,併力爭引領趨勢。”8月25日,在百度大腦語言與知識技術峯會上,百度CTO王海峯解讀百度語言與知識技術的發展歷程與最新成果。

在他看來,語言與知識技術是人工智能認知能力的核心,以語言和知識為研究對象,讓機器像人一樣掌握知識、理解語言的自然語言處理技術,對於人工智能發展至關重要。“歷經近十年發展,百度已經構建了完整的語言與知識技術佈局,包括知識圖譜、語言理解與生成技術,以及上述技術所支持的包含智能搜索、機器翻譯、對話系統、智能寫作、深度問答等在內的的應用系統。”
據介紹,十年來,百度大腦語言與知識技術成果豐碩,獲得包括國家科技進步獎在內的20多個獎項,30多項國際競賽冠軍,發表學術論文超過300篇,申請專利2000多項。技術不斷突破創新的同時,也在產品上創新探索,同時將領先的技術輸出給開發者與合作伙伴,提升各行業智能化水平。
王海峯表示:“知識圖譜是機器認知世界的基礎。機器認知能力的突破,越來越依賴對知識和大規模知識圖譜的運用。百度打造了世界上最大的多源異構知識圖譜,擁有超過50億實體和5500億事實,並在不斷演進和更新,已應用於各行各業,每日調用次數超過400億次。”
值得關注的是,針對不同應用場景和知識形態,百度建立起多樣化的知識圖譜類型,既有基礎的實體知識圖譜,也有行業知識圖譜、事件圖譜、關注點圖譜等,以及融合語音、視頻、圖片的多模態知識圖譜。而這背後是百度創建的包括無標籤大數據開放知識挖掘技術、知識體系自擴展的知識圖譜自學習技術、以及融合多源異構數據的知識補全與整合技術在內一整套知識圖譜構建方法。
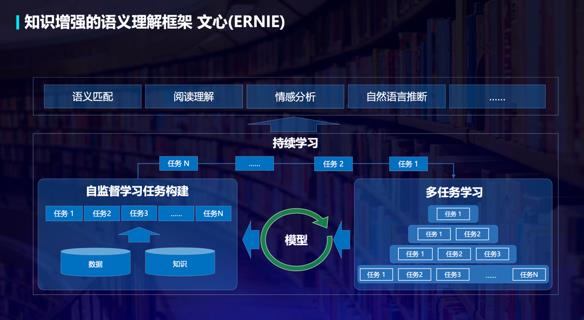
另外,百度研製了知識增強的跨模態深度語義理解方法,通過知識關聯跨模態信息,運用語言描述不同模態信息的語義,進而讓機器實現從“看清”到“看懂”、從“聽清”到“聽懂”,即圖像和語言、語音和語言的一體化理解。而融合場景圖知識的跨模態語義理解預訓練技術,則大幅提升了跨模態推理能力。
王海峯指出,通過知識圖譜、語言理解和跨模態語義理解等技術,智能搜索幫助用户更加高效、精準、便捷地獲取知識和信息。百度提出了知識圖譜驅動的對話控制技術,以及首個基於隱空間的大規模開放域對話模型PLATO等,並推出智能對話定製和服務平台UNIT,可幫助開發者高效構建智能對話系統,實現規模化應用。百度翻譯支持200多種語言,每天響應超過千億字符的翻譯請求,支持超過40多萬家第三方應用,技術上,提出了多智能體聯合學習、基於語義單元的同傳模型、稀缺語種分組混合訓練算法等。
此外,百度語言與知識技術的成果,也在源源不斷通過開源開放平台對外輸出,在互聯網、金融、醫療、教育等諸多領域發揮作用,提升產業智能化水平的同時,也得到了各方認可,這是近十年來百度語言與知識技術不斷進步的最佳證明。
最後,王海峯對語言與知識技術的進一步發展做了展望。“複雜知識表示和快速構建技術,知識與深度學習 進一步融合,深度融合感知和認知的跨模態語義理解技術,模型可解釋性和魯棒性等,仍有很多技術難題需要持續研究和解決。但對於未來,百度充滿信心,願始終堅持探索機器‘掌握知識、理解語言、擁有智能’。”