B站的“生草翻譯”,關AI什麼事?_風聞
果壳硬科技-果壳旗下硬科技内容品牌2021-01-12 18:59
“特朗普(女性)長大了,我在妓院裏看到了她。”
——《長恨歌》
難以置信這是《長恨歌》?
生草翻譯是網友們基於谷歌翻譯、百度翻譯等翻譯器創造的一種惡搞內容的生產模式。開篇的句子即是生草翻譯的名場面之一,它的原句其實是《長恨歌》中的“楊家有女初長成,養在深閨人不知”。
類似的名場面其實還有很多:
奧特曼裏的“怪獸暴君”,被翻譯成“超級愚蠢的克”;李白的“將進酒,杯莫停”,成了“進入酒吧,請不要停下來”;《狂人日記》中的“他們會吃人,就未必不會吃我”變成了“不要吃人,等我,一起吃”等等。
好好的翻譯器,怎麼就被一眾UP主玩成了生草翻譯機,這背後是有神秘的藍光影響了世界,還是説現階段的翻譯AI本就過於智障,所以活該被玩壞?
這一切還要從生草翻譯器説起。
Danny丨作者
一萌、普通醬丨編輯
放大燈團隊丨策劃
當人類“虐待”AI
首先來了解一下:什麼是生草翻譯器?
網友口中的“生草翻譯器”並不是一個專門的軟件,而是一套製作流程。在這套流程操作下,一切翻譯器都可以用來“生草”。
生草,有時也叫“草生”,通常表達超好笑、笑死我了的意思。這個詞源於日語“草生える”,在日本的彈幕文化中,常用日語“笑”的首字母“w”表示好笑,而一排w的樣子像極了草,就有了用“草生える”(長草了)表達好笑的説法。

小聲:其實這個説法跟中文互聯網的“233333”“hhhhhh”差不多。
方法其實很簡單。比如,打開任何一個翻譯工具,將歌詞或文字依照中、英、日、韓、法的順序循環翻譯20次,最後翻回中文即可。
聽起來似乎沒什麼新奇?但生草機這翻譯20次的魔性洗禮,最終讓一篇篇經典的小説、散文乃至古詩詞,變成了B站上語序生硬、措辭荒誕,但是卻又有一種莫名故事感的爆款生草翻譯視頻。
國內“生草翻譯視頻”的頭部製作者,是在B站擁有38.6萬粉絲的“鷹目大人”,代表作為“谷歌翻譯20次魯迅《狂人日記》中的經典‘吃人’片段”。
鷹目大人B站截圖
通過生草翻譯機,鷹目大人將白話小説《狂人日記》硬生生加工成了一篇鬼畜超現實散文,魔幻場面到處可見。該視頻目前在B站上有302萬的播放量和12.1萬的點贊。
但經放大燈團隊測試發現,**同樣是把《狂人日記》丟進谷歌翻譯中,如果僅僅是進行中英文之間的反覆互譯,不論重複多少次,其結果都不會較大的變化。**甚至對於一些中文名篇,谷歌翻譯還能做到中英文的嚴格對譯,每次的結果都一字不差。
那麼,好端端的谷歌翻譯,怎麼就變成了神奇的生草翻譯器?UP主們有什麼特別的技巧嗎?
一個重要訣竅是:要選擇AI翻譯更易出錯的小語種。
“翻譯軟件缺乏中小語種語料庫。”一位不具名的專家告訴放大燈團隊,當前常見的翻譯系統多基於大數據進行訓練,數據量越大、質量越高,訓練的翻譯系統越好。
小語種語料為啥匱乏?還是因為錢。
一個事實是,目前市場主流需求集中於中英互譯。“我們C端用户90%的需求都是中英互譯。”騰訊翻譯君商務總監周丹介紹稱,根據騰訊翻譯君過往的服務情況,英日韓法四種語言和中文之間的互譯,加起來已經佔到了整個機器翻譯C端市場的97%,其他小語種的市場十分有限。
更大的市場才能獲得更高的關注度和人力投入。小語種市場小,研究投入就少。據相關專家介紹,翻譯AI目前接觸到的中英互譯訓練數據通常可以達到數億、甚至數十億規模。而小語種翻譯面臨嚴重的數據匱乏,通常可能僅有數萬條甚至更少的訓練數據。
低資源翻譯是全球全行業長期面臨的難題,也是國際研究的前沿熱點。但是,低資源翻譯並不特指小語種。一篇文言文的英文翻譯,也可以認為是低資源翻譯。面對文言文翻譯,AI交出的答卷也是一塌糊塗。

《蜀道難》變身“串聯並聯電路圖” 圖丨UP主“悠然曉冰”
不過,儘管語料資源多寡有異,但翻譯原理都類似。
當前機器翻譯行業的主流技術,是基於神經網絡的、端到端的翻譯。其典型結構包含一個編碼器和一個解碼器。收到輸入文本後,編碼器首先“通讀”一遍,然後對整個輸入文本進行抽象和向量化表示,使得其成為AI能“理解”的模樣,然後AI翻譯模型再通過解碼器,把要表達的意思和語料庫中的數據對應,在此基礎上,逐個產生目標單詞,最終輸出譯文。
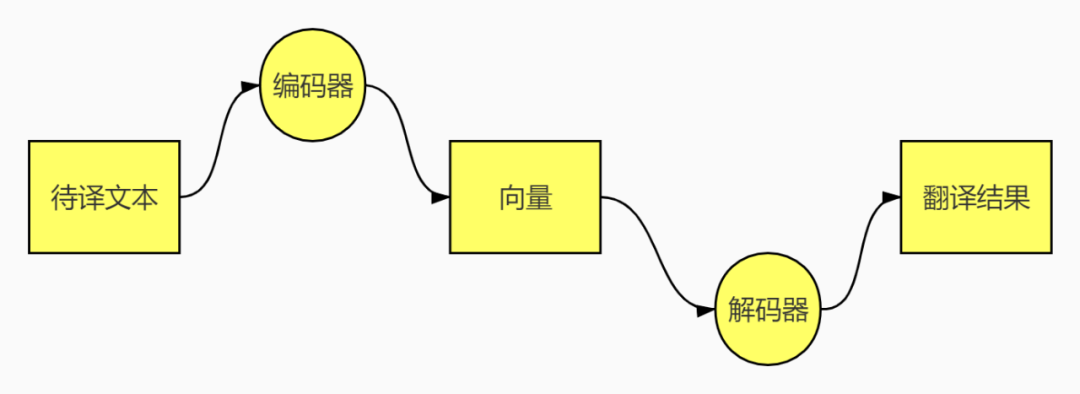
AI翻譯流程示意圖丨放大燈團隊製圖
**在此過程中,一切在互聯網上不能爬取到充足語料的文本,都屬於低資源範疇。**就像《狂人日記》《長恨歌》這種,連英文版都不易得,更別提小語種譯本了。
巧婦難為無米之炊,“沒有樣例語料”就是翻譯AI的死穴。讓AI翻譯連人類翻譯家都怵的內容,UP主們簡直是在玩賽博虐待。
此外,除了在一款軟件中的反覆翻譯外,鷹目大人等UP主還會在谷歌、百度等多款翻譯軟件中輪流翻譯一段文字,然後生草。
B站上的“翻譯20次”
這合理嗎?
人們可能覺得兩個不同的AI翻譯模型對譯,就像兩個人對話一樣稀鬆平常,然而事實並非如此,不同算法模型之間的差異,導致AI之間並不能互相“理解”。
“這種差異遠比人們想象的要大。”騰訊智能平台產品部自然語言研究中心總經理李沐博士告訴放大燈團隊,“兩個AI就像是完全不同的兩個物種。”
AI的悲歡並不相通。
“生草”背後的技術誤解:愛加戲的AI
這些視頻能火爆,不僅僅是因為生草翻譯後文本的失真,更主要的是其結果總能有一種莫名的故事感和流行元素混入,在我們再熟悉不過的文章和翻譯結果之間,製造奇怪的……因果關係,或者説一種陌生感。

令人撓頭的奇怪因果,圖丨UP主“鷹目大人”
這些莫名其妙的邏輯從哪來?
UP主們對文本內容的人為修飾不可忽視。為了增強戲劇性,UP主們會對生草機產出的文本加以修改,像鷹目大人,就在近期作品的簡介中,都特別註明“文本略微修改”。
除此之外,還有很多名場面的誕生,則是AI在翻譯過程中自行加戲的結果。
“AI沒有‘上下文’概念。”一位從事NLP機器翻譯的專家告訴放大燈團隊,**目前的機器翻譯沒辦法像人一樣,去考慮一句話的語境、乃至上下文背後的背景知識。**AI只會根據語料庫和算法模型,去翻譯一段文字。
在此過程中,為了優化表達,AI會抓取近期網絡頻繁出現的對譯內容,並且優先使用。
趕時髦的一面是與時俱進,另一面是製造大量誤譯。比如一句英文中如果有“President”這個詞,會因訓練模型的語料庫中雙語句對中的實際表達,而被AI翻譯成“特朗普”,而不是“總統”。

亂入朱自清《春》生草翻譯視頻的特朗普 UP主“鷹目大人”
一些不相干的人名、物品名就這樣奇蹟般地出現在生草翻譯的結果中。
不過,即便AI沒有上下文概念,也不會像查字典一樣逐詞翻譯湊句子。目前AI翻譯都以句子為基本單位進行翻譯。
“普遍採取逐句翻譯主要是因為算力原因。”李沐博士告訴放大燈團隊,一句話越長,編碼和解碼時所需要的算力就越大,隨着長度的增加,所需算力的增長,也不是“1+1那麼簡單”,而是一種“指數級”增長。
事實上,目前在算法模型上以通篇文章為單位進行翻譯的,即使是在學術領域,也是比較前沿的待探索領域。
那這又和句子中詭異的邏輯感有什麼關係?
很簡單,由於流暢度是評價機器翻譯質量的重要指標之一,這使得AI在以句為單位進行翻譯時,會考慮每句話內部的流暢度。
**當AI發現它面對的句子支離破碎時,便會主動“加戲”,使其符合人類表達習慣的句子。**一些儘管流暢但詭異魔幻表達,也就由此誕生。

AI的賽博朋克,圖丨UP主“鷹目大人”
對於本就不那麼聰明的AI來説,生草翻譯的使用條件實在過於極端。**“****翻譯過程中任何一個環節的微小錯誤,經過多次傳遞,都會被迭加放大。”**相關專家對放大燈團隊表示,多輪翻譯帶來的生草,可以簡單理解為多個系統或者同一個系統的多次串聯。
至於這些句子有多駭人聽聞,並不重要,反正AI也看不懂。同樣的,很多人也不求甚解AI為什麼寫出了這種話——他們只想證明AI大概是個傻子。
但AI並不在乎。它還是在網絡中默默記錄和學習着人類的語言,以完成它被設定的本職工作:翻譯。
你儘管生草,翻譯軟件該用還得用
生草,並不能成為否定機器翻譯水平的理由。
儘管AI不擅長低頻語料翻譯,不懂上下文,還愛加戲,但是它依舊是個好AI。阿里、騰訊、網易等多家深耕翻譯領域的專家告訴放大燈團隊,AI翻譯目前在B端的商業化市場十分可觀。
其主要變現渠道包括:
在一些對外垂直領域市場的應用。比如阿里巴巴國際站為商家提供商品信息的翻譯。
私有云的部署。比如給政府企業部署加密的翻譯網絡。
公有云的API接入。比如手機系統中自帶的翻譯。
打包到一個全能AI中去。比如各類虛擬助手。
在此背景下,B端企業級用户顯然不會因為幾個視頻,就否定機器翻譯的價值。那麼,C端普通用户呢?
普通用户看完生草翻譯視頻後,要説沒一點想法也不太可能,但機器翻譯在語料豐富的領域,如人們經常使用且跟熟悉的時事新聞領域,往往還都有着不錯的表現。無論是人類翻譯還是機器翻譯,主要目的都是交流,而不是對一個句子進行來回翻譯。因此在有更好的、省時省力的低成本替代方案出現前,機器翻譯該用還得用。
畢竟也不花錢。
而以鷹目大人為代表的生草翻譯視頻UP主,為了追求眼球效果,一味選擇低語料素材不説,光是其反覆翻譯的行為,就不具備參考價值,只能在視頻網站博君一哂。
事實上,知乎上已經開始出現了諸如“如何看待b站UP主‘鷹目大人’因製作‘低創視頻’而火?”等,關於生草翻譯視頻小範圍火爆的反思性提問,來反思這種並沒有什麼技術含量的所謂“創作”。

知乎上的相關問題
另外,值得指出的是,類似鷹目大人這樣,通過翻譯軟件進行商業“創作”的行為,目前其實處於版權法律的灰色地帶。
“機器翻譯出來的文本,迄今為止還沒有人去聲稱過版權,但這並不意味着,以後不會有某家公司對其生成的內容聲明版權。”一位不具名的行業人士表示。
就讓娛樂歸娛樂,翻譯歸翻譯吧。