ISSCC 2021:3D NAND閃存的最新進展_風聞
半导体行业观察-半导体行业观察官方账号-专注观察全球半导体最新资讯、技术前沿、发展趋势。2021-02-20 14:46
來源:內容由半導體行業觀察(ID:icbank)編譯自「anandtech」,謝謝。
一年一度的ISSCC涵蓋了廣泛的討論主題。例如每年的會議中,都包含有關非易失性存儲器的會議,大多數NAND閃存製造商都會分享其最新發展的技術細節。在會議上,我們能獲得的信息超出了這些公司通常在新聞發佈會上願意分享的信息,並且演講通常涉及來年即將上市的技術。
在本週的ISSCC 2021上,六家主要的3D NAND閃存製造商中的四家將展示他們最新的3D NAND技術。三星,SK hynix和Kioxia(+ Western Digital)正在共享其最新的3D TLC NAND設計,而英特爾將展示其144層3D QLC NAND。美光公司(去年年底宣佈推出176L 3D NAND)和中國存儲新兵長江存儲今年都不參加。
3D TLC(每個cell有3位)更新
三星,SK hynix和Kioxia / WD介紹了有關其下一代3D TLC的信息。 美光的176L TLC未在此處顯示,因為他們尚未針對最新一代的3D NAND發佈大部分數據。
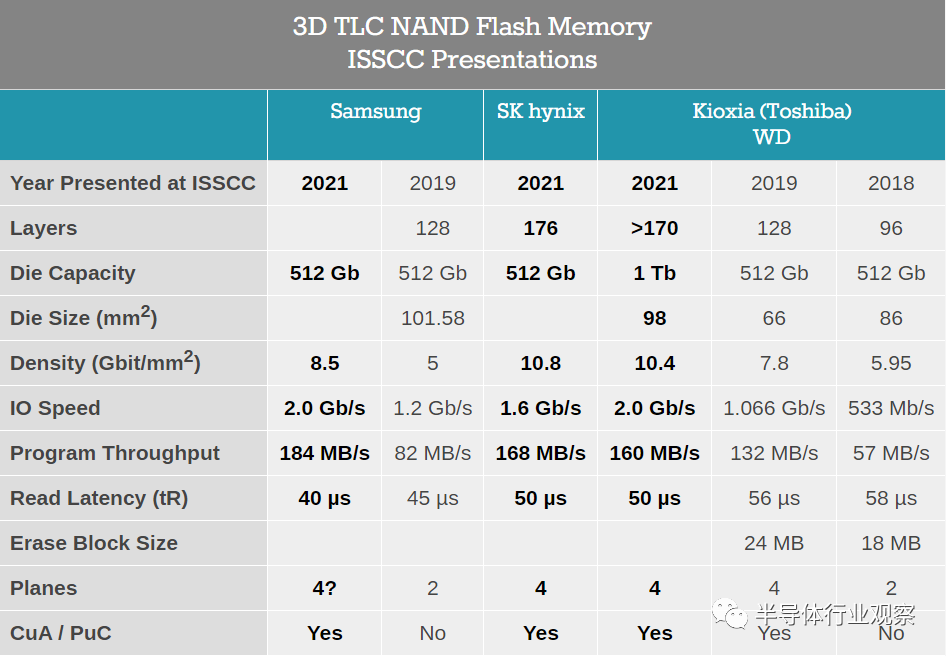
SK hynix和Kioxia / WD所描述的TLC部件看起來相當相似,但區別在於SK hynix談論的是512Gb芯片,而Kioxia談論的是1Tb芯片。儘管Kioxia吹捧更高的NAND接口速度,但兩種設計都具有相似的性能和密度。Kioxia和Western Digital發佈了一個新聞稿,宣佈了162層3D NAND,因此它們的總層數落後於SK hynix和Micron。該新聞稿還提到,其cell陣列的水平密度提高了10%,因此Kioxia和Western Digital可能將垂直通道比任何競爭對手都更緊密地排列在一起。
3D QLC(每個cell有4位)更新
今年唯一在ISSCC上進行QLC更新的公司是英特爾。
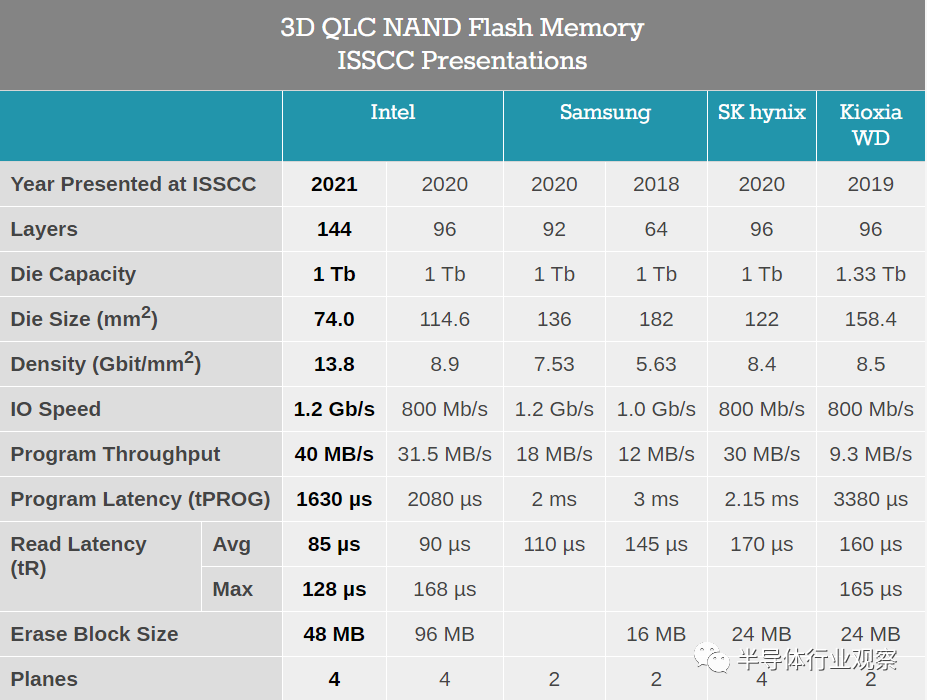
不同廠商的陣列下的CMOS(CMOS Under Array)
英特爾和美光現在已解散的合資企業是僅次於三星的第二家轉向3D NAND的NAND閃存製造商。英特爾/美光3D NAND帶給業界的最重大創新是CMOS Under the Array(CuA)設計。這就將大多數NAND芯片的外圍電路(頁面緩衝器,讀出放大器,電荷泵等)置於存儲單元的垂直堆棧之下,而不是並排放置。
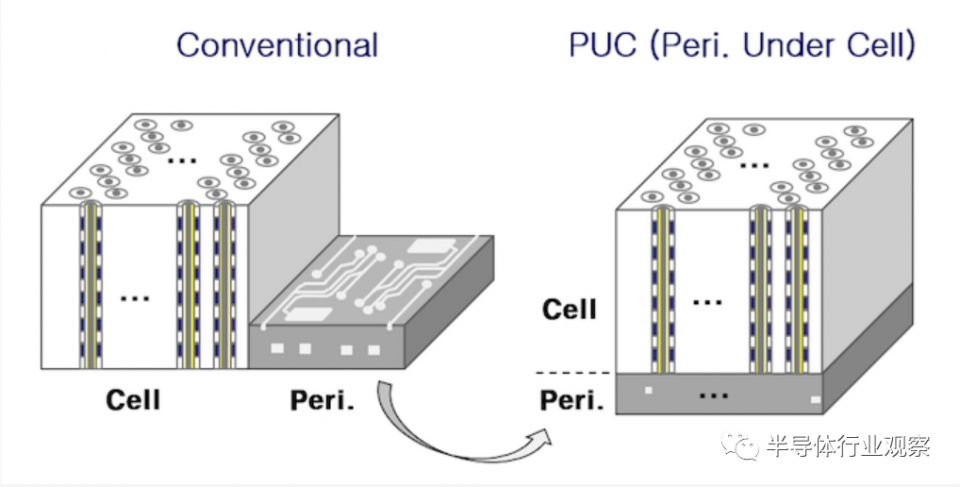
除了節省裸片空間之外,用於3D NAND的CuA / PuC樣式設計還允許裸片包含更多的外圍電路,而其他方面的成本效益比更高。這使得將裸片的存儲器陣列劃分為更多單獨的平面非常實用,每個平面都有自己的大部分外圍電路副本。大多數沒有CuA佈局的3D NAND的每個die僅使用兩個平面(two planes per die
),但是現在每個人都在使用CuA,因此標準是每個die有四個平面(four planes per die)。這提供了額外的並行性,從而提高了每個芯片的性能,並抵消了通常由於使用更少的芯片達到相同總容量而導致的總體SSD性能下降。
CuA結構並非沒有挑戰和缺點。當製造商首次切換到CuA時,它們會大大增加外圍電路的可用裸片空間。但是在那之後,每一代相繼增加的層數意味着管理相同數量存儲單元的die空間就更少了,因此外圍電路仍然必須縮小。將外圍電路置於存儲單元陣列之下還會帶來新的限制。例如,三星在今年的ISSCC演講中提到,當電荷泵不再能夠使用易於包含在3D NAND堆棧中的高金屬結構時,這就為電荷泵構造大型電容器帶來挑戰。
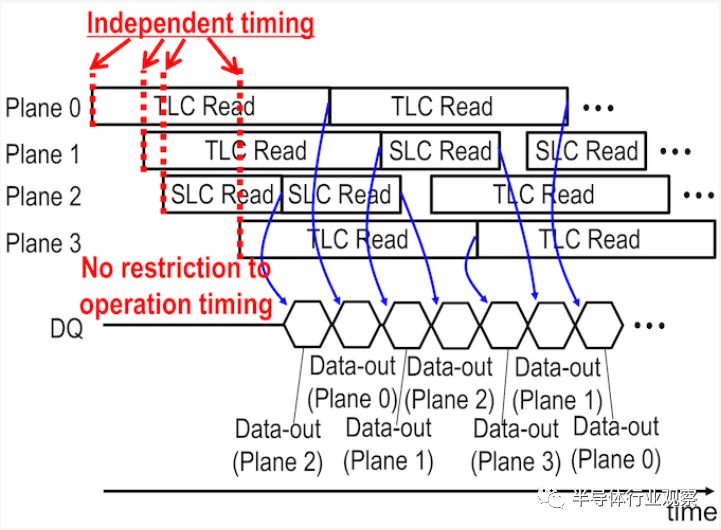
更好的On-Die Parallelism:每個die四個平面
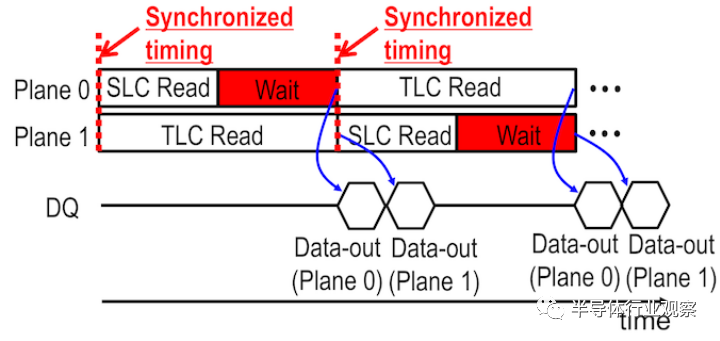
將NAND閃存管die分為四個平面可以使該die並行處理更多的操作,但是並不能使其表現得像四個獨立的die。因為並行執行操作受到限制:例如,同時寫入仍必須在每個平面內的同一字線上進行。但是隨着閃存芯片數量的增加,製造商一直在努力放鬆一些限制。在過去的幾年中,製造商推出了“獨立”的多平面讀取,這意味着在不同平面中的同時讀取對每個平面內的讀取位置沒有任何限制,這是隨機讀取吞吐量的一大勝利。
NAND IO加快了對SSD控制器的支持速度
ISSCC上介紹的新型TLC NAND部件支持NAND閃存die和SSD控制器之間的通信的IO速度範圍為1.6到2.0 Gb / s。目前市場上最快的NAND SSD的運行速度為1.2-1.4Gb / s。NAND製造商可以通過確保將用於其SSD的自己的SSD控制器設計準備好支持這些更高的IO速度而從垂直集成中受益,但是可能會依賴其他第三方控制器的SSD供應商。Phison針對高端PCIe 4.0 SSD的最新E18 8通道控制器僅支持1.2Gb / s IO速度,而即將推出的E21T 4通道NVMe控制器則支持1.6Gb / s。Silicon Motion的8通道SM2264和4通道SM2267分別支持1.6Gb / s和1.2Gb / s IO速度。
由於以1.2Gb / s的速度運行8個通道已經足以使SSD飽和PCIe 4.0 x4連接,因此這些新的更高IO速度在PCIe 5.0到來之前對高端SSD並沒有多大用處。但是,價格更實惠的4通道消費類SSD控制器將能夠使用這些更高的速度更好地進入PCIe 4.0性能領域,達到或超過第一個PCIe 4.0 SSD控制器(Phison E16,8ch @ 800Mb / s)提供的吞吐量。正如諸如SK hynix Gold P31之類的驅動器所展示的那樣,在每個通道上支持高IO速度的高級4通道控制器在性能上極具競爭力,同時以比8通道控制器更高的功率效率運行。
字符串堆疊:第一個三層NAND
字符串堆疊已被視為將3D NAND擴展到更高層數的必要手段。只有三星能夠一次構建超過100層的3D NAND,並且其他所有人早就轉而使用堆疊兩個具有更合理層數的decks了。這意味着例如美光公司的176層3D NAND構建為88層存儲單元,然後在其頂部再構建88層。與一次完成所有層相比,這會增加成本,並且需要在平台之間的接口處仔細對齊。但是另一種選擇是使垂直通道更寬,以使縱橫比(寬度與深度)保持在當前晶圓廠技術可以蝕刻的範圍之內。
英特爾的144L QLC設計最令人驚訝的是它們已經轉向了3層堆棧:48 + 48 + 48層,而不是我們期望的72 + 72。由於他們的前一代產品是48 + 48層(總共96L)設計,因此,除了第三次重複相同的沉積,蝕刻和填充步驟順序外,他們對於存儲器陣列本身的製造方式幾乎沒有什麼改變。英特爾通過這種方法影響了工廠的吞吐量,但它可能有助於他們更好地控制從堆棧頂部到底部的通道和單元尺寸的變化,考慮到他們對QLC及其獨特性的關注,這可能是一個更大的問題。決定仍然使用浮柵存儲單元,而不是像其他所有人一樣切換到電荷陷阱單元。

關於學術會議的一個小建議
我們必須明白到,發表這些更新的ISSCC是一次學術會議,這一點很重要。演示文稿不是產品公告,論文也不是產品規格表。ISSCC上展示的設計並不總是與量產相匹配。例如,Kioxia / WD過去曾提出過128L和“ 170+”層NAND的設計,但實際量產的第五和第六代BiCS NAND是112L和162L設計。他們還儘管在他們的2019年演講中提到了這一點,但將切換到更密集的``陣列下CMOS(CuA)結構的CMOS’‘推遲到後來的產品線。諸如寫入性能之類的規格通常也以最佳情況來表示,而實際產品最終比所提供的要低。
儘管所有這些公司都參加了一次會議,但即使演示文稿與最終產品相匹配,我們從ISSCC上學到的信息通常也不完美,信息也不完整。兩家公司對其報告的指標不一致,而且我們通常每代僅獲得一個芯片設計的信息-即使一家公司計劃製造512Gbit和256Gbit零件,一家公司也可能會展示其512Gbit設計。近年來,幾家公司似乎在談論一年的QLC和第二年的TLC之間交替進行。儘管如此,ISSCC在3D NAND上的演示仍然是衡量最新技術水平以及整個行業的發展方向的好方法。
這些演示內容的大約一半是用於微管理施加到各種導線的電壓以優化讀取,編程和擦除過程的巧妙方案。在速度,精度,磨損和其他因素之間存在複雜的權衡。除了要説將一個單元編程到所需的電壓(並且不打擾其他單元)不是一個簡單的過程,我們甚至不對所有這些細節進行深入研究,甚至從TLC或QLC單元中讀取數據也相當簡單。比從DRAM或SRAM單元讀取要複雜得多。我們對管芯本身的任何重大結構變化以及所有精細電壓的最終結果(即讀取或編程一頁存儲器的速度)更感興趣。