分佈式架構馭數而行,海量數據方能有備無患_風聞
大数据在线-2021-03-28 18:18
“過去會區分核心數據和非核心數據。現在是所有數據都很重要,所有數據都不能丟失。”去年武漢一家大型三甲醫院信息中心主任接受筆者採訪的觀點依然讓人記憶猶新。
無獨有偶,在產業數字化和數字產業化的雙輪驅動下,一個海量數據時代正加速到來。IDC《數據時代2025》白皮書就預測,到2025年全球數據量總和將達到175ZB;其中,來自中國的數據量預計未來五年年平均增長30%,並且到2025年將成為全球數據量最大的區域。
海量數據時代來臨,一方面為企業擁抱數字化、洞悉市場規律、挖掘數據價值提供了充分條件;另一方面,海量數據的存儲、備份、恢復等也給傳統備份方式、產品帶來了前所未有的挑戰。正如愛數公司所認為,數據大爆炸讓數據備不完、存不下、管理難愈發成為各行各業的新常態,而基於分佈式架構的備份系統,正是應對海量數據備份恢復挑戰的那一副良劑。
為何繞不開一個“快”字
海量數據的產生離不開外部政策的強力導向和企業數字化轉型的內部強大驅動力。
以中國市場為例,《中國數字經濟發展白皮書(2020)》透露,數字經濟近年來成為經濟發展的又一引擎,其GDP佔比逐年提升,在數字經濟的推動下,各行各業的數字化轉型明顯提速;而剛剛出爐的《十四五規劃》報告中,更是強調提升數字產業經濟佔比的核心目標,全面推動建設數字中國和發展數字經濟。
同樣,海量數據的產生也離不開企業數字化轉型強大的內部驅動力。尤其是隨着數字化轉型進入到深水區,雲計算、大數據、AI等數字化技術加速在業務場景中落地,極大地產生了豐富的數據。
那麼,與過去相比,如何理解當前海量數據的規模?
用幾個簡單的數據來形象説明。例如,一家中型科技公司的開發測試環境往往達到上萬個虛擬機主機;交通、智慧城市等場景一年往往能產生超過10PB規模的數據量;銀行、保險等金融機構擁有超億個小文件……
 各個行業用户明顯感覺到數據量爆炸性的增長。“面對海量數據,越來越多用户存在備不完、存不下、管理難的情況。”愛數AnyBackup產品副總裁常華如是説。
各個行業用户明顯感覺到數據量爆炸性的增長。“面對海量數據,越來越多用户存在備不完、存不下、管理難的情況。”愛數AnyBackup產品副總裁常華如是説。
具體來看,首先是用户的數據總量呈現出指數級的增長趨勢,完全備份幾乎無法完成,哪怕用户,精打細算、調優海量備份任務的計劃調度,依然有觸碰到紅線的風險;其次,採用傳統備份架構體系,往往存在着N套備份系統對應N*N個備份客户端的情況,使得管理備份任務變得異常複雜;最後,隨着數字化程度越來越高,用户生產數據增速越來越快,但是規定的備份時間窗口沒有變,使得備份窗口壓力極大。
“傳統備份解決方案通常是採用串聯、堆疊的部署方式,現在已經很難適用海量數據的保護了。”常華表示道,“解決之道就是分佈式架構,通過分佈式架構的易擴展、高吞吐和高可用,來實現海量數據備份恢復的以快制勝。”
分佈式架構有何獨特之處
在數據保護領域採用分佈式架構乃是順勢而為,順應了海量數據時代數據保護需求的變化。
分佈式架構本身並不稀奇,之前在IT各個領域都有着廣泛的應用。那麼,分佈式架構應用在數據保護領域有哪些獨特之處,它又是如何實現易擴展、高吞吐和高可用來解決海量數據備份恢復的挑戰?
以愛數AnyBackup Family 7分佈式架構為例,之所以能實現易擴展、高吞吐和高可用,不僅僅是其採用了Scale-Out橫向擴展架構,還在於其完成了從客户端到底層備份介質端到端的優化,針對備份恢復的每一個環節進行有針對性的優化,從局部到整體完成與分佈式架構的適配、調優。
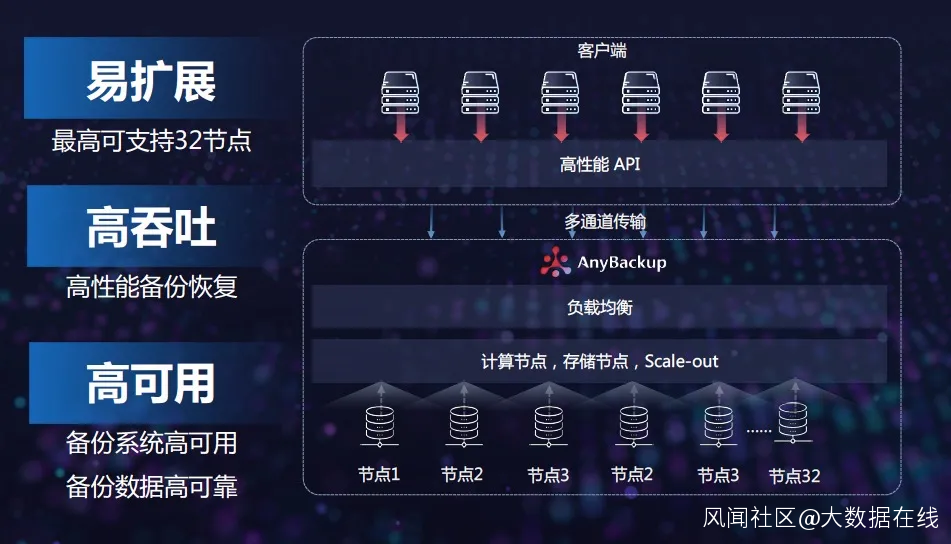 例如,在客户端,針對虛擬化、數據庫、雲平台等工作負載,愛數提供了專有API,結合各種調優算法,來實現海量備份性能的提升;又如,通過負載均衡,對於備份任務和備份容量進行多任務分發和合理分配,以達到一個整體最優的性能。
例如,在客户端,針對虛擬化、數據庫、雲平台等工作負載,愛數提供了專有API,結合各種調優算法,來實現海量備份性能的提升;又如,通過負載均衡,對於備份任務和備份容量進行多任務分發和合理分配,以達到一個整體最優的性能。
“在六節點集羣吞吐量測試報告中,備份吞吐率達到36TB/h,恢復吞吐率達到20TB/h。”常華透露,“愛數AnyBackup Family 7分佈式架構今年將實現單套備份系統最高支持32個節點,存儲池容量超過10PB。”
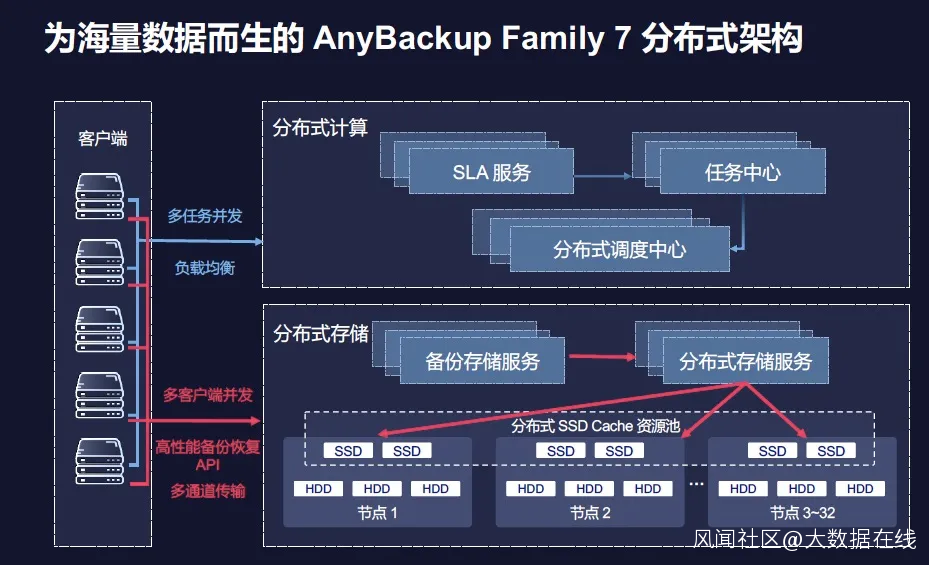 另外,存算分離架構也是愛數AnyBackup Family 7分佈式架構的一大核心特徵。存算分離架構的一大好處就是具有足夠的靈活性,當用户規模越來越大之後,其對於靈活性要求也會提升,往往需要根據業務或者工作負載的需求來靈活擴展計算或者存儲,如果採用計算與存儲緊耦合的方式,計算與存儲擴縮容則極為不方便,無法滿足用户業務對於靈活性的需求。
另外,存算分離架構也是愛數AnyBackup Family 7分佈式架構的一大核心特徵。存算分離架構的一大好處就是具有足夠的靈活性,當用户規模越來越大之後,其對於靈活性要求也會提升,往往需要根據業務或者工作負載的需求來靈活擴展計算或者存儲,如果採用計算與存儲緊耦合的方式,計算與存儲擴縮容則極為不方便,無法滿足用户業務對於靈活性的需求。
以愛數AnyBackup Family 7分佈式架構為例,在其存算分離架構之中,分佈式計算主要負責海量任務併發和負載均衡,完成各種任務的調度、匹配與優化;而分佈式存儲則通過多通道的併發和數據負載均衡,將接受過來的數據寫入到備份節點之中。
“存算分離架構,可以最大限度來提升備份與恢復的每個工作環節。”愛數AnyBackup研發副總裁鄧平介紹道,“例如,分佈式的SLA策略調度,針對保護任務、保護對象,採取不同的備份策略和週期。”
事實上,採用分佈式架構的備份產品在實際業務場景中已經凸顯出其優勢。以某省政務雲平台為例,其雲主機的數據量已經達到1520TB,數據庫的數據量則達到了1641TB,整個平台有數千個任務,並且依然保持着很高的增長速度,其每個備份域只需要部署一套備份系統即可完成日常的備份作業,所有39個節點通過一套運營管理產品就實現了全平台的管理,極大簡化了日常管理工作。
從分佈式架構帶來哪些啓示
哈佛大學管理學教授克里斯坦森在《創新者的窘境》中認為,創新關鍵不僅僅在於技術進步或者科學發現,更加關鍵的是在於對市場需求變遷的主動響應。
毫無疑問,海量數據時代,用户對於備份恢復的需求變化就是“快”,在時間窗口有限的情況下完成對於不斷增長的海量數據的備份、管理與恢復。
這種趨勢直接驅動着以愛數為代表的公司將分佈式架構創新應用在備份產品之上,並且以全局的視角,以及着眼於備份恢復每一個環節的優化,來實現“快”這個目標。
面向未來,“快”始終是數據備份恢復的核心目標,分佈式架構在數據保護領域的創新還會有巨大的空間,以真正實現海量數據的有備無患。