當人工智能變成人工智障_風聞
世界说-世界说官方账号-我们只做大家看得懂的国际深度报道与评论。2021-05-08 18:02

從去年開始,因為疫情的原因,許多美國大學的大課都轉成了網課。Zoom、Canvas 和 Microsoft Team 成為了課程交流的主要平台,同學們開始逐漸熟悉線上交作業、線上討論等等,甚至還組織了線上 social。然而,比起上課時的斷網、無聊和注意力渙散,線上考試成為了許多人的夢魘——特別是少數族裔。
紐約大學法學院的中東裔學生 Alivardi Khan 怎麼都登不上考試界面。考試軟件的面部識別功能,一直提示他“沒有足夠的光”,儘管他在的房間光線十分充足。“這根本就不是光的問題,面部識別算法有種族偏見。”他在推特上抱怨道。
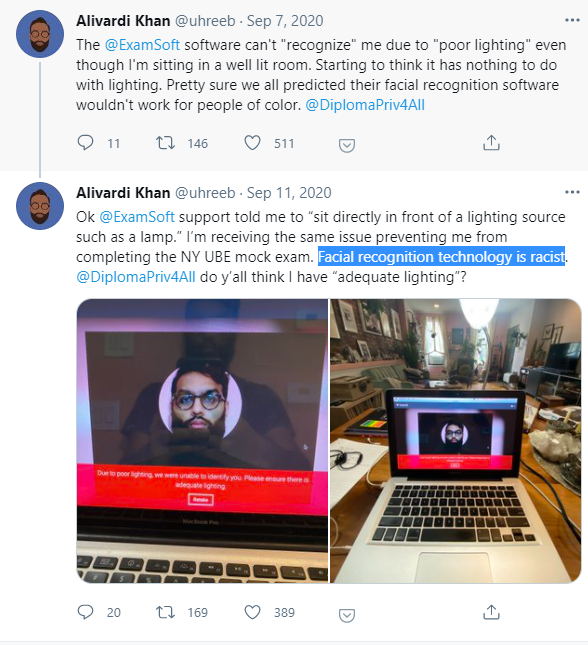
● Alivardi Khan在推特上講述了自己的窘況 / 網頁截圖
而另外有好幾所大學,使用的是一款叫 Proctorio 的在線智能監考工具。通過攝像頭和人工智能(AI),Proctorio 能夠自動識別學生的面部。閉卷考試的時候,學生必須全程盯着屏幕,如果有移動、離場的情況,會自動觸發軟件的“警報”,而監考人員則會收到通知。此外,這個軟件還會實時監控眼睛移動、打字規律,從中找出作弊的蛛絲馬跡。這個軟件遭到了大量學生的抵制,少數族裔尤甚——軟件無法識別面部,無法進入考試界面;好不容易登陸進去,軟件在中途卻頻頻警報、暫停,甚至將人從考試界面踢出去。
一個非裔女生的媽媽 Janice,把女兒掙扎着考試的情況發上了推特。“電腦調亮,不管用;窗子打開,過曝了;枱燈打開,又太黑。她最後必須在頭上打光,才能讓軟件正常工作。”儘管如此,試了9次,只有兩次成功。
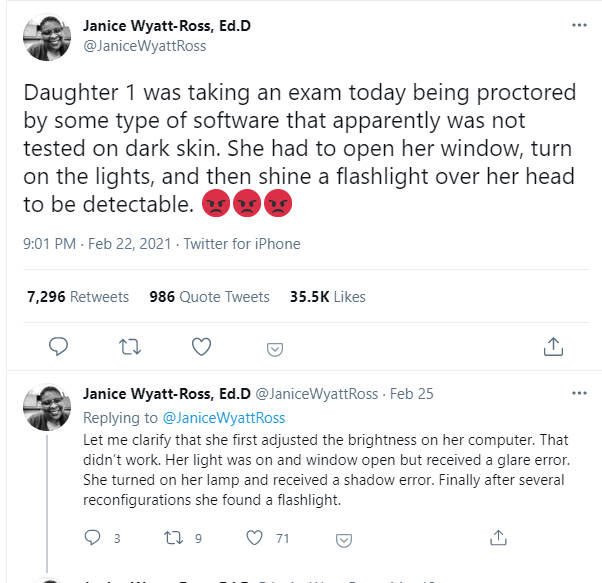
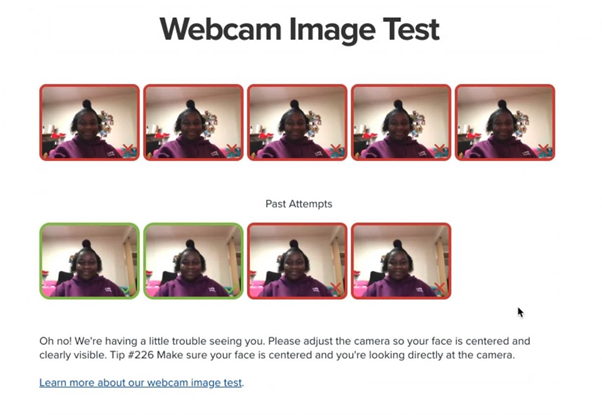
● Janice在推特上公佈的女兒使用在線考試軟件的截圖 / 網頁截圖
許多學生都在抱怨這個軟件極其不人性化、十分難用。有的必須給教授發信求另外的安排,有的被迫在考試時間求助於軟件技術支持,有的在學校論壇或者推特上交流溝通“技巧”,例如什麼樣的角度、什麼樣的光線能夠讓識別更方便。有的同學試圖反映到學校,甚至發起倡議,禁用這些為他們帶來極大不便的監考軟件。在原本就壓力巨大、孤立無援的網課情景下,這些煩心事每每讓人加倍崩潰。
● 有人在Reddit上發出了倡議 / 網頁截圖
開源“血統”的監考軟件,置信度堪憂
邁阿密大學計算機系新生 Akash Satheesan 是印度裔,過去一年他也深受在線監考軟件困擾。他決定“反向工程”這些監考軟件,找出其代碼和算法的問題。他把 Proctorio 的 Chrome 擴展應用的代碼抽出來仔細查看之後發現,一些面部識別的功能代碼指向的文件,與另一個開源的圖像軟件庫 OpenCV 的文件名高度相似。
Akash 把 Proctorio 擴展應用中的算法複製出來,用 FairFace 數據庫中的1萬1千個面部數據對其進行了一系列測試。接着,他再用來自 OpenCV 的面部識別模型測試了同樣的圖像,兩者的結果幾乎相同。這印證了他的猜想——監考軟件 Proctorio 的確是直接挪用了 OpenCV 的產品。儘管 Proctorio 聲稱自己的技術是獨立開發的,但在其軟件的授權頁面,的確找到了 OpenCV 的相關證書。
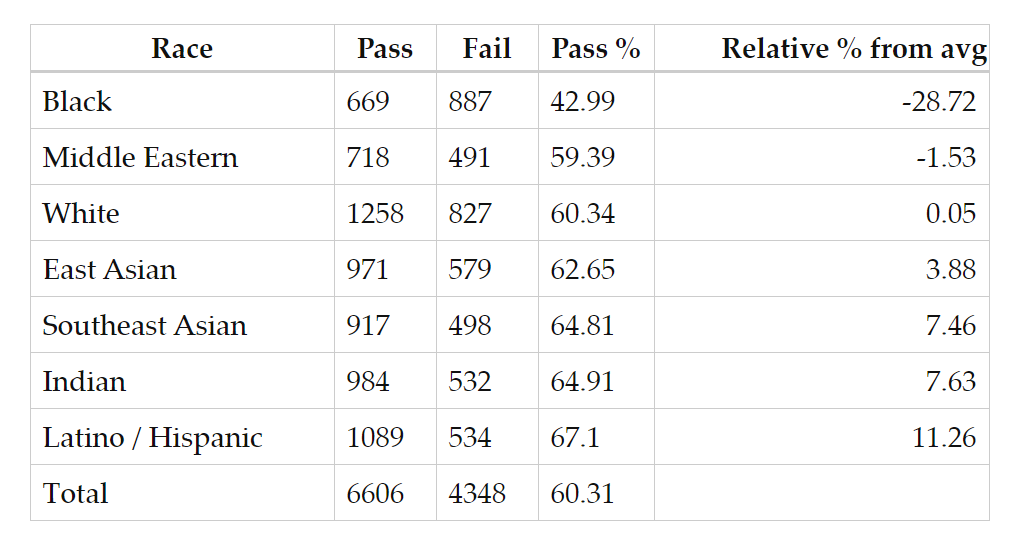
● Akash Satheesan在自己博客上公佈的Proctorio對不同族裔面孔的識別率 / 網頁截圖
測試的結果也讓人汗顏。在 Akash 進行的測試中,算法在57%的情況下,無法準確識別非裔面孔,41%的情況下無法識別中東裔面孔。對其它面孔的識別率也並不高——失敗率在30%-40%不等。的確,在抱怨軟件難用的同學中,亦不僅僅是少數族裔。而此前就有 CS 領域的研究人員指出,OpenCV 的訓練算法,對不同種族面孔識別的成功率有較大的偏差,特別是對少數族裔的識別和匹配,置信度十分一般。
是什麼導致了識別的偏見?
不管如何,有一個問題始終有如房間大象:軟件對有色人種的面部識別存在偏見,這是“種族歧視”嗎?推特上,兩派為此爭執不休。一方表示,“軟件本身無錯,只是設計得不好”,而另一方則認為“偏見=種族歧視”。但實際上,軟件和算法的設計、應用是一整個鏈條,從原理到實踐,每一環都有出問題的可能。
從原理上看,圖像的面部識別的核心在於用大量已有的數據,在進行一系列標準化處理之後(例如調整角度、去除背景等等),投入神經網絡,提取出面部特徵,然後再將面部特徵與已有的數據庫做比對。以非常有名的開源面部識別工具 OpenFace 為例,它也用了之前提到的 OpenCV 的軟件庫裏的工具對圖片進行預處理。簡單來講,它是用50多萬張人臉數據訓練出來的一個模型,可以從圖片中提取出來面部的128個特徵點,再把這些特徵點進行比對。
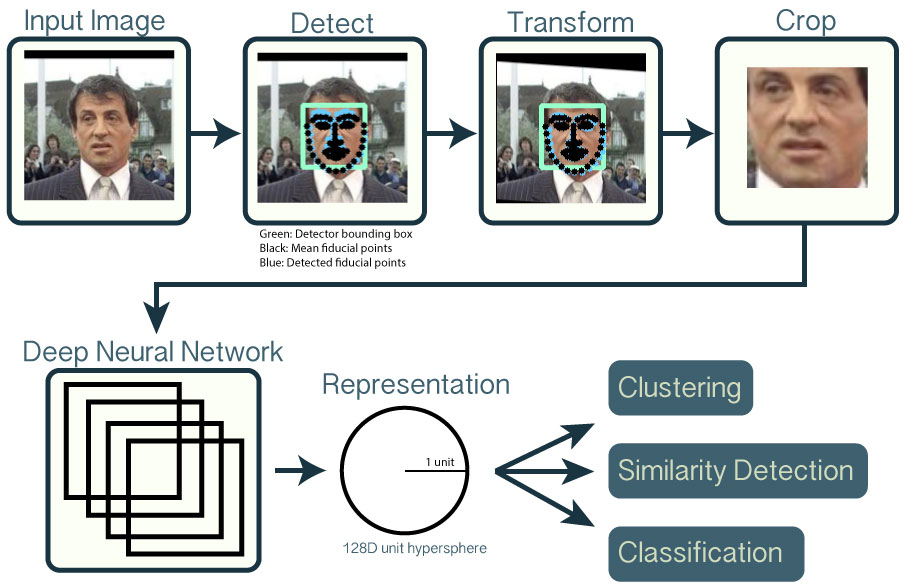
● OpenFace工作原理 / Github
比起大公司的商用模型(例如 Google 的 FaceNet 或者 Facebook 的 Deepface等等),OpenCV 和 OpenFace 不僅開源,還可以在 Torch、Python 環境中運行,只需要普通電腦的 GPU 即可。使用的神經網絡模塊也通過訓練調校過,更是有一系列的機制對數據進行壓縮、低維化處理,實現實時的處理,尤其可以在手機等便攜設備上使用。
但這種“方便”的工具,在數據訓練和模型準確度上,都有不小的問題。而圖像識別的偏見,很大程度上是訓練不足帶來的——也就是説,原有的50萬原始訓練數據中,除了白人之外少數族裔的面孔嚴重缺乏。即使它對圖片進行了亮度調節和灰度處理,不同族裔之間的面部特徵也有相當大的區別,這讓算法對於非白人的面部特徵提取能力不足,從而在識別上出現偏差。已經有研究表明,用亞洲人圖像佔比更大的數據庫訓練出來的模型,在識別亞洲臉上,比一般模型更好。
這其實跟人對“異族”的識別有異曲同工之處。有不少神經科學研究都指出,人們對於“不常見”的陌生族裔的面部,識別能力不足。有一個段子就是“歐美人看亞洲人長得都一樣”,拿着朋友的證件矇混過關。這對人工智能、機器學習而言也是一樣的道理——它們“不認識”其它族裔的人。
在訓練數據有限的情況下,若想要追求準確度,反而有可能會將數據中的偏差放大,對“少數”更加不利。比如,一個數據庫裏有98%的男人,只有2%的女人。經過訓練的AI即使可以識別所有男人、完全不管那2%的女人,那也能有98%的準確度。但是那2%的女人,對機器就等同於不存在了。一些研究者認為,現在的圖像識別開發者,往往會陷入盲目追求“準確度”的陷阱裏去;訓練出來的模型,在某一個數據庫上的精確度可以達到非常高,這在技術領域被稱為“過擬合”,但搬到現實中,就難免會出現嚴重偏差。
偏見發展到哪一步,會積累成歧視?
軟件開發者們知道這個問題嗎?可能知道,但面部識別技術可能存在的偏見,並不是許多做監考軟件的小公司優先考慮的事情。OpenCV是一款訓練成熟的開源軟件,有廣泛應用的基礎,但卻並沒有人在各種應用環境下為其重訓、糾偏。在當下,人工智能逐漸變成一個拼硬件和數據庫實力的戰場,然而大部分小公司實力有限。現有的數據庫、模型和算法,恐怕無法支撐從實驗室到多元、複雜的真實世界的過渡,這一過程中必然會出現大量問題。
糾偏也是一個非常困難的事情,即使對於大公司來講也不容易。谷歌曾經出現過用黑人圖片反搜、結果出現“猩猩”這種情況。他們的做法,是直接把猩猩這個標籤給隱藏了,並沒有從根本上解決圖片識別裏潛藏的錯誤偏見。
在機器學習研究的領域裏,數據庫還是相對比較“乾淨”,標籤、分類等等都相對規範。然而在商業領域採集到的數據,很多都非常潦草,訓練出來的算法也有很大問題。“垃圾進,垃圾出”(Garbage in,Garbage out),是業界對於糟爛數據庫訓練出糟爛智能的吐槽——很多時候,甚至是自嘲。
● 機器學習中的“垃圾進,垃圾出”(GIGO)法則 / 網絡
英國巴斯大學計算機系教授 Joanna Bryson 説,“偏見,只是機器從數據中拾取的規律(regularity)而已。”在人工智能和機器學習的範疇裏,“偏見”並不是一個帶有價值判斷的詞彙。然而,在涉及到現實應用的領域,情況就不一樣了。現在的機器,當然不具備體會情感或者故意施加偏見的能力,只是誠實地反映了數據庫、乃至社會中真實存在的偏見,而這些反映有時候並不是我們想要的。
更大的問題,是把技術語言不加審視地“翻譯”成為客觀現實,甚至替代人類的判斷。這種技術層面的偏差(bias)便會在社會上迅速地積累成實際的歧視(discrimination)。
在實驗室的環境中,一般來講,一個模型對於數據匹配的判定,是以“置信度”為標準的。從原理上講,它們並不是“不認得”非裔面孔,只是“置信度”不夠高——也就是原始數據訓練不足的情況下,在判定上沒有那麼大的把握。然而,Proctorio 等監考軟件的問題就在於,一旦低於某個置信度的閾值,它的結果就直接是“不認得”(或者判定失敗),這直接給大量少數族裔的使用者帶來了嚴重的不便。考試是一個講求公平公正的場合,這種使用上的不便、特別是對特定人羣的不便,嚴重影響了考試的公平。從這個角度上講,不加考慮地使用帶有偏見的工具,的確是種族歧視。
另外一個嚴重的問題,是特定人羣和某些特徵的數據上的“關聯”,直接被運用在對風險的“判定”上。哈佛大學計算機系教授 Latanya Sweeney 發現,在搜索引擎上搜典型的黑人名字,搜索引擎會有超過80%的概率在搜索建議裏提供“逮捕”“犯罪”等詞彙,而沒有種族特徵的卻只有不到30%。2019年美國國家標準和技術研究所的一份研究報告,分析了市面上200多個面部識別算法,發現大部分對少數族裔的識別都存在或多或少的偏見,而在所謂的“一對多”的算法裏(例如警方採集一個人的面部特徵並比對犯罪數據庫進行比對),非裔女性的假陽性概率最高。也就是説,非裔女性最容易被系統誤判成有前科的犯罪分子。
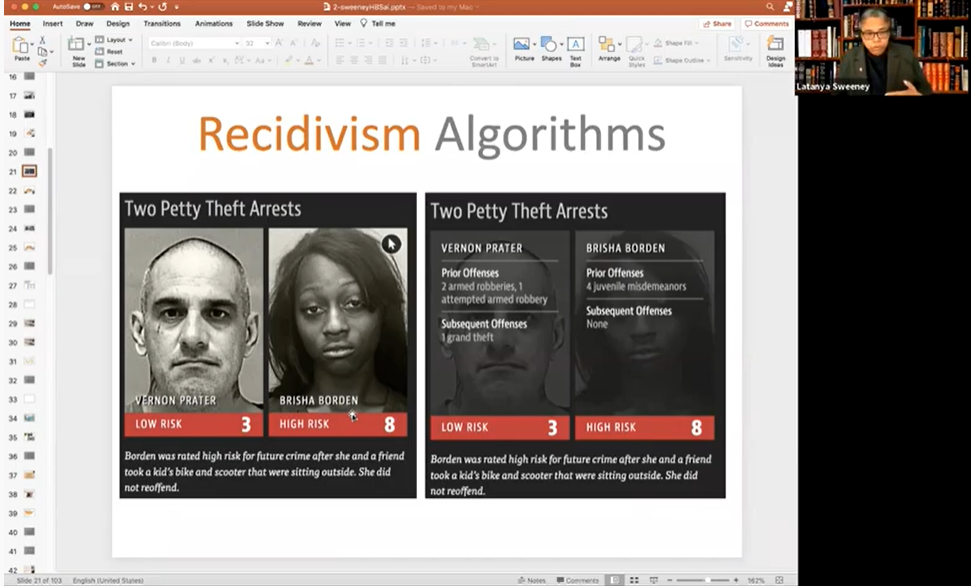
● Latanya Sweeney在課堂上講述了自己的發現:帶有種族偏見的算法 / 視頻截圖
説到底,在這個階段,將人工智能作為一切的“守門人”和“判定人”,時機還相當不成熟。機器學習將複雜的現實壓縮成信號,再用一層層的神經網絡去把這些信號“模擬”成現實的樣子,形成一套標準化的認知(比如一個人的臉“該長什麼樣”)。然而我們所處的世界,還有無數多特殊的、多維度的、多角度的“現實”。面部識別工具給我們提供的方便、快速、“智能”的場景,是不可能概括這種複雜現實的。
在強大的面部識別技術下,我們怎麼辦?
在當下,人工智能提供了一個非常方便而強大的“解法”。特別是面部識別技術,能夠在暗處、無阻礙地對人進行監視以及數據的收集,這無疑給安全和監控系統提供了大量方便,甚至某種“路徑依賴”。畢竟,買一套成熟的解決方案,比自己研究開發容易多了。
但是,對這些“解決方案”不加審視地廣泛應用,對於少數族裔、少數族羣、特殊情況的無視,對“標準化”“理想化”以外情景的缺乏考慮,無疑會極大地影響軟件應用上的公平公正,乃至方便普適。
所以,人工智能的“歧視”,説到底還是人類現有偏見的積累。我們還在不斷地完善我們自己的認識,在不斷的發展和學習中糾正我們自己的偏見,去消除歧視和不公。因此,我們也需要給機器以機會完善自身,成為我們的認識夥伴,而不是用智能、“客觀”的“模型”,來武斷地代替我們去認識世界。
對於我們每個人來説,需要警惕身邊的數據“採集”,多注意一下這些技術的用途,拒絕沒有同意(consent)的技術應用。只有這樣,才能促使技術開發和運用向更人性、更保障隱私、更公平的方向發展。(責編 / 張希蓓)
(感謝艾藹計劃支持)
(本文作者為佐治亞理工大學科學技術與社會研究博士候選人)