從火星的古海洋,讀懂藍星的數據湖之變_風聞
脑极体-脑极体官方账号-从技术协同到产业革命,从智能密钥到已知尽头2021-05-18 20:03
大家想必都聽説了天問一號探測器“祝融號”成功在火星着陸的消息。在它傳回的家書中,提到科學家們為自己選擇的着陸地,火星的烏托邦平原,可能是一個古海洋所在地,地形平緩,確保了安全性。
當我們將目光投回到身處的這顆“藍星”,也時時面臨着需要為產業要素選擇着陸地——比如説大數據。
相比傳統的數據倉庫架構,數據湖(Data Lake)已經成為數字化進程中,對現代企業和組織極具吸引力的大數據“着陸地”。
簡單來説,數據湖指的是如同湖泊一樣,將各種業務及軟硬件中源源不斷產生的各類數據,全部容納其中。
在AI+雲的大趨勢下,數據湖還可以與機器學習等相結合,指導企業進行效率優化及智能決策;與雲計算結合,利用雲服務彈性擴展、靈活部署、高可用高可靠、按使用量付費等特點,打造出投資回報更高的大數據解決方案。

目前來看,數據湖有巨大的想象空間,也吸引着各大雲廠商下足功夫,AWS、微軟、谷歌等都推出了各自的數據湖產品。
5月13日,騰訊雲也首次對外展示完整雲端數據湖產品圖譜,並推出兩款“開箱即用”數據湖產品,數據湖計算服務DLC和數據湖構建DLF。
相比單一產品或服務,在騰訊雲的數據湖版圖中,可以看到概念的“拓維”:雲原生智能數據湖,對產業來説意味着什麼?圖譜式的產品矩陣,能給企業帶來哪些價值?“開箱即用”會給數據湖及數字化進程帶來什麼影響?
我們以數據湖的需求與挑戰為開端,來探秘騰訊雲帶來的“致用紀元”。
數字山河,需要怎樣的大數據之湖?
先回答一個疑問,什麼樣的企業需要數據湖。答案是,所有。
IDC報告顯示,到2025年全球數據總量將超過160ZB。數字化進程中,對大數據的管理與應用已經成為企業的競爭要素之一。飛速增長的數據規模自然也需要新的數據存儲策略,數據湖的特殊之處在於:
所有數據可以一直保存,不管是實時使用的,還是可能永遠不會被使用的,不僅讓單位存儲成本更低,也讓任意時間點的數據回溯與分析成為可能;
所有類型可以全部容納。無論是定量指標的結構化數據,還是傳感器、社交網絡、圖像視頻等等多樣化數據源的非結構化數據;
所有用户可以得到支持。在數據湖中,所有數據都以原始形式存儲,需要使用數據的人可以快速找到數據源的單一位置,避免了數據孤島、數據重複、協作困難等問題。
此外,數據湖也易於適應變化。數據倉庫的開發和更改都需要花費大量的時間,消耗開發人員資源。而在雲端部署的數據湖,可以根據企業業務需求靈活擴展,比傳統方案具有更大的靈活性,最大限度地減少僱傭專業數據運維團隊的支出。

看到這裏,是不是已經心動想要拿起電話訂購了?別急!並不是將所有數據一股腦丟進湖中就大功告成了。
正如Gartner分析師尼克·休德克所説,將數據湖看做是大數據項目的靈丹妙藥,是一個謬論,數據湖是一個概念,而不是一種技術。
也就是説,企業在引入數據湖時,要注重從搭建、效益到應用的整體平衡。
比如,如果沒有適當的工具,數據湖可能會遭遇數據可靠性的問題,出現數據損壞、髒數據等等,讓數據科學家、AI工程師難以利用數據進行推理,或是訓練出不準確的業務模型;
再比如,一直往數據湖裏面存儲數據,而缺乏數據治理及應用輸出,就會形成“數據沼澤”,隨着時間的推移變得混亂、低質量;
最關鍵的是,目前市場上大多數數據湖產品都在強調對數據的存儲及計算,在具體業務場景之中究竟該怎樣去應用數據湖,並沒有清晰一致的答案。不解決技術的致用問題,就會讓很多企業望而卻步。
這種局面該怎麼辦?中國人的智慧早有提示,流水不腐户樞不蠹,比起挖坑引水的“單向湖”,從山川河流的源頭、湖泊的常規治理,再到流向產業田野的應用,這樣的一整套數據湖解決方案,顯然更符合產業用户的期待。
開啓紀元,騰訊雲的多米諾骨牌
技術產業週期的開啓,從來不是一蹴而就的。雲原生的數據湖,需要在存儲、計算、應用等層面解決諸多挑戰才能完成。
而騰訊雲首次披露的雲端數據湖產品矩陣,就是這樣一套組合式的產品,包括了數據湖存儲、數據湖算力調度、數據湖大數據分析、數據湖AI能力、數據湖應用、雲上基礎服務等六個層面,如同一副多米諾骨牌,將企業應用數據湖過程中可能遇到的階段性問題一一推倒。
我們可以從三個層面來看騰訊雲數據湖的新紀元打開:
1.數據底座。
數據湖的本質是為企業乃至全社會的數字化轉型提供堅實可靠的數據基礎設施架構,對高性能、高安全、高可靠、低成本等綜合實力提出了高要求。
對此,騰訊雲數據湖在整個數據生命週期都進行了周全的設計。在存儲層,以對象存儲COS服務為核心,理論上可以存儲任意規模的異構數據,也支持將其他雲端數據設施,為企業打消後顧之憂;
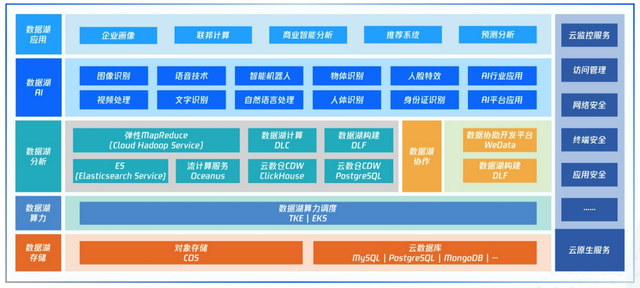
在數據分析層,既提供半托管的泛Hadoop服務,滿足用户自定義需求,也提供全託管的數據服務,便於用户獲取海量數據的洞察力。
此外,用户還可利用騰訊雲提供的數據協作工具對計算服務進行編排和調用,提升企業數據的便捷性和敏捷度。
2.智能源頭。
今天,企業選擇數據湖的考量與上雲有着異曲同工之處,那就是為業務增長引入AI能力,達到提質增效的目的。騰訊雲也沒有令人失望,給出了一系列助力數據智能的解決方案。
比如在算力調度上,基於騰訊雲彈性容器服務EKS,開放的容器化的分析架構讓數據分析功能可組合性更強,擴展性更強,降低企業訓練AI、應用AI的綜合成本;
此外,騰訊雲數據湖也提供豐富的AI服務,為圖像處理、音頻處理、自然語言處理、視頻處理等提供有力的數據支撐,當企業想要引入這些音視頻能力時,更加簡單快捷。
3.致用工具。
和所有新技術一樣,數據湖的最終評價標準是要落進現實。這就需要降低企業應用門檻,讓技術價值能夠從真實業務場景中生長出來。
為此,騰訊雲在數據湖產品圖譜中,推出了企業畫像、聯邦計算、商業智能分析等數據應用服務,企業直接選擇自身所需要的能力,就可以把數據湖應用構建起來。

這樣一步步推導,也就連成了“從入湖到出湖”端到端的完整鏈路,也清晰地指出了騰訊雲數據湖所帶來的差異化價值:希望借數據湖產品圖譜,引領數據湖進入“致用紀元”,與數字山河相映照。
向文明進發:數據能源的里程碑
1964年,蘇聯天文學家尼古拉·卡爾達肖夫提出理論,根據一個文明所能夠利用的能源量級,來量度文明層次及技術先進程度。
按照等級劃分,地球目前正處於0.73級左右,還沒有達到利用行星本身所擁有的能量規模。
換個角度思考,大數據,何嘗不也是這顆藍色星球上的新興能源,讓智能更快、產業更優、經濟動力更強,對數據的利用與開發也將助推一國數字文明的加速發展。
正如同“祝融號”標誌着中國人開始走出地球“搖籃”,騰訊雲數據湖產品圖譜也為智能時代的大數據管存用提供了一個全新的選擇:在業內首先提出了“圖譜式數據湖產品”,從數據入湖時怎樣存、算,到在湖中如何分析與應用,滿足用户的所有需求。這不正是產業一直在期待的數據“能源開採裝置”嗎?

首先,騰訊自身龐大且多元的業務體系,無時無刻不在產生着大量的非結構化信息,這時就需要數據湖技術去解決數據分散、重複數據等問題,正是在騰訊新聞等諸多內部場景中孵化,打磨到一定程度之後,將相應能力開放給產業客户,可謂是恰逢其時。
第二,來自騰訊雲的基礎服務與技術積累,比如前文提到的能幫助用户快速構建企業數據湖技術架構的數據湖構建(DLF)產品,所提供的統一元數據管理與湖構建能力,就需要在數據規模很大的時候也能實現高性能的訪問,來讓數據存儲、計算等速度更快,這就依賴於騰訊雲在雲服務領域的技術壁壘,為數據湖體系提供了保障。
最後,正如騰訊雲大數據專家所説,要深入業務場景才會發現鮮活的痛點,方案要落在各行各業、不同企業客户的實際場景中去。
事實上,成功的數據湖採用者大都是使用“業務回頭”的方法,即先確定業務可以從數據湖中獲得的最大價值情境,然後將這些場景納入到解決方案中,再逐步填充數據。這就需要做大量定製開發工作,考驗着雲廠商的企業服務能力與意識,也是今天數字化轉型中最難的一道關卡。
在這方面,我們看到騰訊雲直指現實需求和應用場景,將採用決定權交給業務,與客户的技術人員一起梳理核心需求,最終選擇更適合自己的方案。騰訊雲數據湖產品之所以率先選擇向“技術致用”延伸,或許正來自於這一份對業務的尊重。

對於數據湖這類新技術的出現,也容易出現了兩種截然相反的情緒:過度質疑,會令企業躊躇不前,錯過超越競爭者的機遇;過於樂觀,又會導致對困難缺乏充足的估計。
或許更理性的態度應該是,和科技企業攜手,一起去探索並撬動未知,駛向氣象萬千的數字文明。