既然這些古籍不能運回中國,能不能用數字化手段讓內容回到中國?_風聞
啊哦哦哦-2021-05-20 08:03
【文/“達摩院DAMO”微信公眾號】
加州大學伯克利分校的東亞圖書館很有縱深,這是全美三大東亞圖書館之一,九十萬冊藏書裏四成都是中文書,還有不少甲骨文和拓片。中國以外,沒幾個圖書館有這水準。
第一次到這的李貝因此總感覺在穿越歷史的“蟲洞”,他小心翼翼地從泛黃的《易經》、《耕織圖記》、《扶桑遊記》和《四庫全書》旁走過,甚至沒敢發出震撼的驚歎。
馬上走到會議桌時,他被人拍了一下,同行的陳力指着一個不起眼的書籤説:“看,王國維先生的借書籤。”陳力見多識廣,比李貝淡定很多。但之前幾分鐘,陳力的情緒也有一次波動,只是沒被發現。當時,他看到了金石大家翁方綱的手稿,“確實珍貴”。
這是2019年6月,賓主四人分別是東亞圖書館館長周欣平、曾任國家圖書館副館長的四川大學教授陳力、四川大學歷史文化學院副院長王果和在達摩院負責學術合作的李貝。
這次會議上,他們要共同探討並敲定一個項目,既然這些古籍不能運回中國,那能不能用數字化手段讓古籍的內容回到中國。
這個項目,隨後被命名為“漢典重光”。
來自伯克利的硬盤
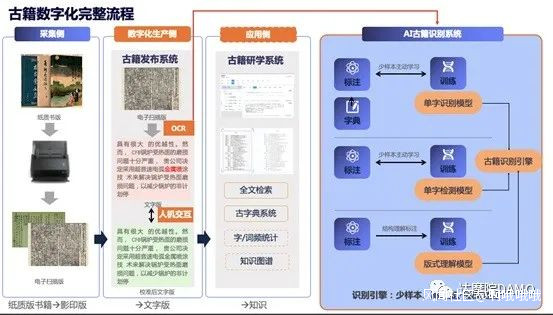
漢典重光項目的分工非常明確——採集側把紙質書變為影印版,數字化生產側把影印版變為文字版,應用側為文字版增加檢索、字典和知識圖譜等研學系統。東亞圖書館完成第一個環節後,四川大學將和達摩院共同完成另外兩個步驟。其中,四川大學的老師將提供一切非計算層面的專業支持,達摩院的機器視覺實驗室將負責全部技術層面的工作。
在達摩院,機器視覺實驗室負責人仁基以使用技術術語而著稱。談起漢典重光這個項目,他會説項目的起點是“把古文字向量化”,難點和關鍵是算法必須要有“強表徵能力”,“表徵的魯棒性不夠是不行的”,他還會用“映射、糾錯、可遷移性、收斂”等詞彙構建語言體系,似乎完全不擔心這種表達“映射”不到聽眾的腦海裏。
所幸,他的核心聽眾之一——陳力對這塊並不陌生。陳力研究過古籍數字化,對很多技術細節都有自己的見解。他也一直在推動古籍的數字化迴歸,漢典重光的公益屬性和達摩院的技術能力打消了他的顧慮。“學術本就是天下之公器。”他説:“大家都沒有功利考慮,合作起來就比較順暢。”
項目啓動後不久,仁基的兩位手下——產品經理弈洵就和算法專家何木一起拜訪了陳力。第一次見面,陳力就興奮地描述了“漢典重光”的樣子——左側的影印版要對應右側的文字版,要有個搜索引擎讓研究者只依靠關鍵詞找到資料,要有知識工具幫助讀者瞭解必備常識,這都是以前的古籍數字化項目沒有的功能,只有這樣才能讓漢典重光變成讓每個人學習古籍和分享古籍的公益平台。
兩個年輕人明顯受到了感染,也覺得雖然數字化的高難度導致項目快不起來,但大家得弄出個樣子來。不過,下調的預期還是沒趕上現實——等到東亞圖書館把掃描版古籍寄過來,他們傻眼了,等待他們分析的不是幾個閃存盤,而是裝滿整整幾箱子的固態硬盤。
“茴字為什麼要有四種寫法”
對這個項目,何木最初是很有信心的。達摩院在這個領域起步很早,在文書等標準化的現代文字領域的識別正確率已經有99.9%。而且,伯克利寄來的數據很多,這也是利好。但看到照片的瞬間,何木就意識到自己太樂觀了。
他知道古籍的載體很多,但也沒想到會多到這個程度,紙、布、竹子、木頭、甲骨、石碑,所有能用的載體都被古人留了字,不同載體上面的字識別起來差別非常大。
就算寫在紙上,問題也沒少多少。那些年代久遠的紙張大多殘缺不全,上面還佈滿斑點,而且排列非常複雜,“古人喜歡從上到下,從右到左,還非常喜歡在上面做批註”。
字跡的精美也成了負擔。“隸書、楷書、草書、行書都漂亮,但也真難認。大部分字還是手寫的,不但兩個人寫的同一個字不一樣,同一個人寫的同一個字也差別很大。”很多字還有不同寫法,何木竟然想起了《孔乙己》:“茴香的茴字為什麼要有四種寫法?”
這馬虎不得。陳力和王果都希望把這個項目做成標杆,首批20萬頁古籍成功分析後,他們才能分析東亞圖書館全部的150萬頁館藏古籍,然後才能向着更多頁的目標前進。
在新的古文字識別領域,團隊原有的OCR(圖像文字識別)的識別準確率只有40%,這顯然是不夠的。幾個人想過尋求技術支持,結果發現較早涉足古籍識別的Google books針對的都是英文古籍,對中文也不適用。
沒有前車可鑑,只能自己來了。好在何木沒丟掉樂觀精神:“這就像教小朋友識字,確實難,但也有簡單的部分,我們就由易到難慢慢做。”

原藏於伯克利大學東亞圖書館的蘇軾著《蘇文忠公文集》
“Wow!Magic!”
大多數時間裏,張楚珏的工作都在屏幕前完成。看到上面出現30個單字圖片後,她要告訴機器哪些是一類字,哪些是挑錯了。幾分鐘後,“機器消化好了”,再開始下一組。
他們正在嘗試的辦法叫做聚類——把同一個字的不同寫法聚到一起,這還是這個理念首次用在古籍領域。
很多輔助性工具被創新出來支持這個理念。奕洵想到了字典,“把標註的字收集起來,相同的字就不用重複標記,同學們就能感受到算法的優化”;對傳統輸入法敲不出的生僻字和異體字,工程師玉虛建議直接保存圖片,然後用固定符號標記,問題就解決了,圖搜也就這樣誕生了。
四川大學專門組織了20多個歷史系學生來做標註,大三學生張楚珏就是其中之一。但這很耗人,大家慢慢就沒了耐心,開始向何木抱怨算法“不靈光”。但何木知道這個過程沒法省略,就像學生要學習,算法也要迭代,“只有數據夠多夠好,機器才能搞定”。
這是兩個圈子的磨合,他們此前距離太遠了。
達摩院的科學家顯然不瞭解歷史學家,只是覺得這些人説話風趣且學識淵博,何木説:“聽陳老師和王老師説話,我們都會感嘆人類怎麼能把意思表達得這麼清晰。”仁基則説:“和他們聊古籍,我們謙虛點説也是處於半文盲狀態。”
歷史學家也不瞭解人工智能。例如,大家都認為“國”和“國”是同一個字,對應的都是“國”。但研究算法的人強調,機器對圖像的識別分兩步:第一步是“所見即所得”,“國”和“國”在這裏是兩個字,必須被標記成兩個字類;把它們和“國”聯繫起來是第二步,“一步到位對人類來説是理所當然,對算法而言簡直就是不可理喻”。
但他們都有科學的態度。
仁基本就謹慎,他一直認為漢典重光不可能一蹴而就:“我們希望更多圖書館加入漢典重光這個古籍數字化平台,完成對古籍的數字化重建。但挑戰還在後面,我們要往更深層次的語義理解和結構化知識構建方向發展。和字形相比,那個領域的數據更匱乏。”
陳力也是如此。他提倡古籍保護長達幾十年,但一直非常謹慎地評估工作量。他認為,儘管現存古籍有20多萬種,但去掉不同版本後嚴格意義上的古籍大約只有5萬種,需要列入整理計劃的大約只有一兩萬種,就這些,他還建議應該用二三十年的時間去完成。
技術進步有時需要這種煎熬。張楚珏只能繼續枯燥的標記工作,並不時期待事情能走上正軌。直到有一天,她突然發現機器好像聰明瞭很多,統計表明算法識別率到這時已經到了96%。“我們只是在教電腦,但何木好像突然調高了機器智商。”她不禁脱口而出:
“Wow!Magic!”

何木、奕洵、王果、陳力討論古文字識別中的技術問題
技術的意義
進入2021年,張楚珏已經能持續感受到進步。聚類被用起來後,算法和數據的互動進入了正循環。字類到3萬再加上自適應算法的幾輪迭代,算法識別正確率已經到了97.5%。
何木還是不滿意。機器識別正確的97.5%中,只有1個百分點的工作還需要專家複核;另外的2.5%就算全部交給專家,人工的工作量也只有3.5%。和機器介入前相比,效率已經提升了30倍。但何木知道“專家還是決定性的”,他希望能把算法識別率的準確率提到99%,做到“機器為主,人為輔”。
但繼續前進將涉及一系列技術難題。他們要確定十幾萬字類的分類,要確定哪些字的識別確實錯誤,“必須交給專家”,“單純的統計結果在這裏沒多大意義。”
技術挑戰不斷,但大家從項目啓動時就知道,這是一件非常難但是非常有意義的事情。古籍識別的技術挑戰雖大,但由此積累的能力卻未必有市場,大家是想通過技術讓古籍活起來,用技術守護文明,用科技創造新的價值。就像陳力説的,這些古籍都有生命,“即使作者去世多年,看他的手稿還是像和他對話。”
國家圖書館曾經帶給陳力很多滿足,他在那裏看過司馬光的《資治通鑑》手稿,也看過魯迅的《從百草園到三味書屋》手稿。“手稿上的修改能讓人看到,魯迅先生寫作時的心境變化。”陳力説,古籍的數字迴歸將滿足更多需要:“那些承載了特殊記憶的東西總會讓人感到親切,它的任何損壞都會讓人傷心,古籍給每個中國人的就是這種感受。”
時間回到兩年前,那場奠定漢典重光項目基礎的東亞圖書館會面持續了幾小時。結束時已是正午,陳力和王果卻執意再去舊書市場逛逛。過去幾十年,古籍獲取難度太大:國內還好,閲讀國外古籍往往需要列出詳細計劃才能申請到機會,並且一去就是半年,還要天天泡在圖書館。結果,只要有機會,他們就四處蒐集舊書,這簡直成了“職業病”。
在四川大學歷史文化學院,王果辦公室旁邊有間存放各種舊材料的屋子,裏面甚至有很多他們在多個渠道蒐集來的六十年代的收據,這對研究那個時代的經濟有不可替代的作用。從這個意義上講,漢典重光也許確實能帶來部分改變——至少以後,當我們的學者探尋這個民族最深層次的問題時,潛意識將把他們帶到一個相同的目的地。
對技術而言,這就夠了。