開源系列:AI對抗攻防算法開源平台,哪家強?_風聞
谭婧在充电-谭婧在充电官方账号-偏爱人工智能(数据、算法、算力、场景)。-2021-06-10 10:38
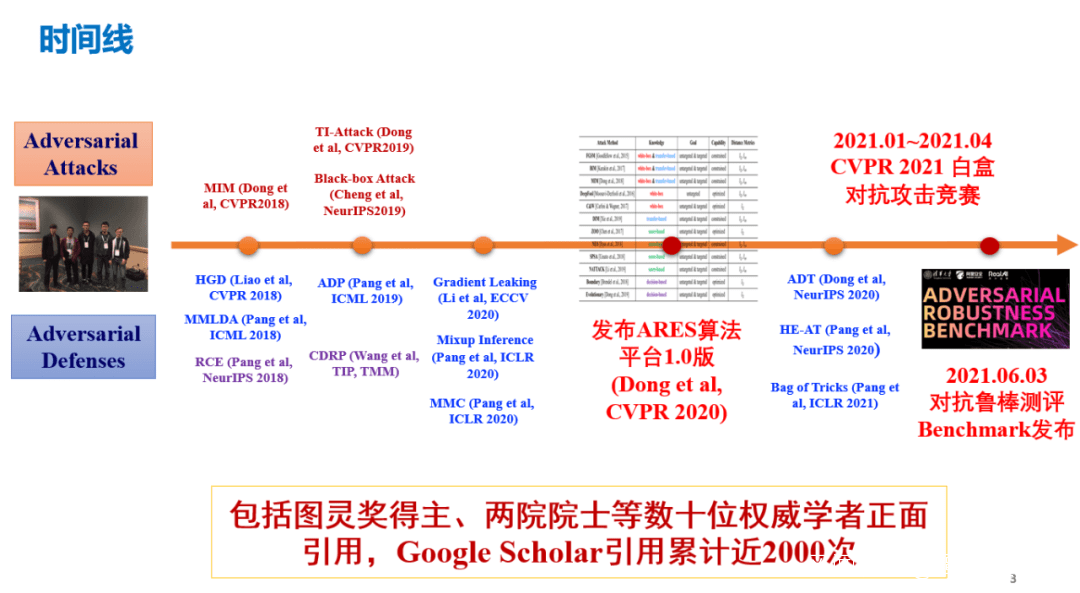
 原創:譚婧 人工智能算法攻與防,始於一個有趣的“搗亂”,在谷歌實驗室裏。 “搗亂”,純粹是人為的,自己給自己添亂。 得到的實驗室結論是:對輸入樣本(一張圖片)故意添加一些人無法肉眼察覺的細微干擾,可以導致圖像分類模型,會以較高的概率(高置信度)給出一個錯誤的輸出。 在現實世界裏,“搗亂”就讓計算機出錯。 2014年的這一結果寫在了,谷歌研究員Christian Szegedy博士和其團隊的論文《神經網絡的有趣特性》(Intriguingproperties of neural networks)中。 論文作者,也覺“有趣”,不信你看論文的題目叫啥。 這可以算,全球最早對人工智能算法攻與防的研究。 或者説,人工智能算法攻與防的研究,肇始於谷歌公司。 2017年,Ian Goodfellow博士牽頭組織了 NIPS 2017 對抗樣本攻防競賽,這是國際上第一次專門舉辦對抗攻防專競賽。這位三十多歲的AI新生代領袖,還有一個江湖稱謂,“生成對抗網絡之父。”
原創:譚婧 人工智能算法攻與防,始於一個有趣的“搗亂”,在谷歌實驗室裏。 “搗亂”,純粹是人為的,自己給自己添亂。 得到的實驗室結論是:對輸入樣本(一張圖片)故意添加一些人無法肉眼察覺的細微干擾,可以導致圖像分類模型,會以較高的概率(高置信度)給出一個錯誤的輸出。 在現實世界裏,“搗亂”就讓計算機出錯。 2014年的這一結果寫在了,谷歌研究員Christian Szegedy博士和其團隊的論文《神經網絡的有趣特性》(Intriguingproperties of neural networks)中。 論文作者,也覺“有趣”,不信你看論文的題目叫啥。 這可以算,全球最早對人工智能算法攻與防的研究。 或者説,人工智能算法攻與防的研究,肇始於谷歌公司。 2017年,Ian Goodfellow博士牽頭組織了 NIPS 2017 對抗樣本攻防競賽,這是國際上第一次專門舉辦對抗攻防專競賽。這位三十多歲的AI新生代領袖,還有一個江湖稱謂,“生成對抗網絡之父。”  此網絡,彼網絡,都是深度學習之網絡。 值得一提的是,清華大學朱軍教授團隊包攬了這次比賽三個賽道的冠軍。 也在2017年,AI對抗攻防迎來首個算法開源平台CleverHans,聽上去,中文名像“聰明的漢斯”。由Ian Goodfellow和其團隊開發並開源,歡迎來自全球各地的對抗算法開發人員貢獻代碼。 Cleverhans平台的攻防框架,將攻防算法模塊化,全球研究者能在這一平台上,快速研發不同的對抗樣本生成算法和防禦算法。 次年,來自圖賓根大學團隊推出的Foolbox(直譯,傻盒子)圖像分類領域的攻防算法庫,開源。 2019年,谷歌Ian Goodfellow博士團隊就曾在2019年的論文“針對自動語音識別的不可察覺的、魯棒的和有目標的對抗樣本”,英文名為,Imperceptible, Robust, and Targeted Adversarial Examples forAutomatic Speech Recognition。 這一研究成果,告訴我們“有趣的搗亂”也適用在語音,將AI對抗樣本攻防算法從圖像領域擴展到語音領域。 這個谷歌團隊的研究(語音對抗攻擊算法),通過添加不可察覺的噪聲達到100%的攻擊成功率。 2019年,博士Ian Goodfellow從谷歌跳槽去了蘋果公司。谷歌AI痛失一員大將。
此網絡,彼網絡,都是深度學習之網絡。 值得一提的是,清華大學朱軍教授團隊包攬了這次比賽三個賽道的冠軍。 也在2017年,AI對抗攻防迎來首個算法開源平台CleverHans,聽上去,中文名像“聰明的漢斯”。由Ian Goodfellow和其團隊開發並開源,歡迎來自全球各地的對抗算法開發人員貢獻代碼。 Cleverhans平台的攻防框架,將攻防算法模塊化,全球研究者能在這一平台上,快速研發不同的對抗樣本生成算法和防禦算法。 次年,來自圖賓根大學團隊推出的Foolbox(直譯,傻盒子)圖像分類領域的攻防算法庫,開源。 2019年,谷歌Ian Goodfellow博士團隊就曾在2019年的論文“針對自動語音識別的不可察覺的、魯棒的和有目標的對抗樣本”,英文名為,Imperceptible, Robust, and Targeted Adversarial Examples forAutomatic Speech Recognition。 這一研究成果,告訴我們“有趣的搗亂”也適用在語音,將AI對抗樣本攻防算法從圖像領域擴展到語音領域。 這個谷歌團隊的研究(語音對抗攻擊算法),通過添加不可察覺的噪聲達到100%的攻擊成功率。 2019年,博士Ian Goodfellow從谷歌跳槽去了蘋果公司。谷歌AI痛失一員大將。  既然是攻防,始終要決出高下。 2020年底,來自圖賓根大學的團隊發佈圖像分類領域評估攻防算法魯棒性的基準平台RobustBench。 這一基準平台,坐擁30多篇論文中零散的防禦模型,利用單一的攻擊算法測量防禦模型的魯棒性,可惜的是,用於評測的數據集不多。 IBM公司的團隊也做了類似的事情,開源了Adversarial Robustness Toolbox(ART,直譯對抗魯棒性工具箱)。短期內,兩個針對圖像分類領域的攻防算法開源庫,相繼面世。
既然是攻防,始終要決出高下。 2020年底,來自圖賓根大學的團隊發佈圖像分類領域評估攻防算法魯棒性的基準平台RobustBench。 這一基準平台,坐擁30多篇論文中零散的防禦模型,利用單一的攻擊算法測量防禦模型的魯棒性,可惜的是,用於評測的數據集不多。 IBM公司的團隊也做了類似的事情,開源了Adversarial Robustness Toolbox(ART,直譯對抗魯棒性工具箱)。短期內,兩個針對圖像分類領域的攻防算法開源庫,相繼面世。  在清華大學,朱軍教授團隊低調開源了 AI 對抗安全算法平台ARES,簡稱Adversarial Robustness Evaluation for Safety。ARES的中文名是阿瑞斯,古希臘神話中的戰爭之神,奧林匹斯十二主神之一。古希臘神話中的戰神,雙手持矛和盾是攻防合一的化身,AI安全算法攻與防博弈。 開源時間追溯到2019年11月24日。
在清華大學,朱軍教授團隊低調開源了 AI 對抗安全算法平台ARES,簡稱Adversarial Robustness Evaluation for Safety。ARES的中文名是阿瑞斯,古希臘神話中的戰爭之神,奧林匹斯十二主神之一。古希臘神話中的戰神,雙手持矛和盾是攻防合一的化身,AI安全算法攻與防博弈。 開源時間追溯到2019年11月24日。 ARES平台,有朱軍教授團隊自行研發的相關攻防算法,有40多個不同類型的防禦模型,支持上層API直接調用。 除了算法庫,還有魯棒性測評工具,支持對圖像分類任務上不同模型的對抗魯棒性進行準確和全面的基準測試。 眾所周知,數據集分為訓練集和測試集,訓練集,訓練模型;測試集,測試模型的性能。因為測試魯棒性所用的測試集很重要,所以,ARES平台採用了公開的CIFAR10和ImageNet數據集。這一成果也被收錄為CVPR2020的Oral論文《基於圖像分類的對抗魯棒性基準》,Benchmarking Adversarial Robustness on Image Classification。
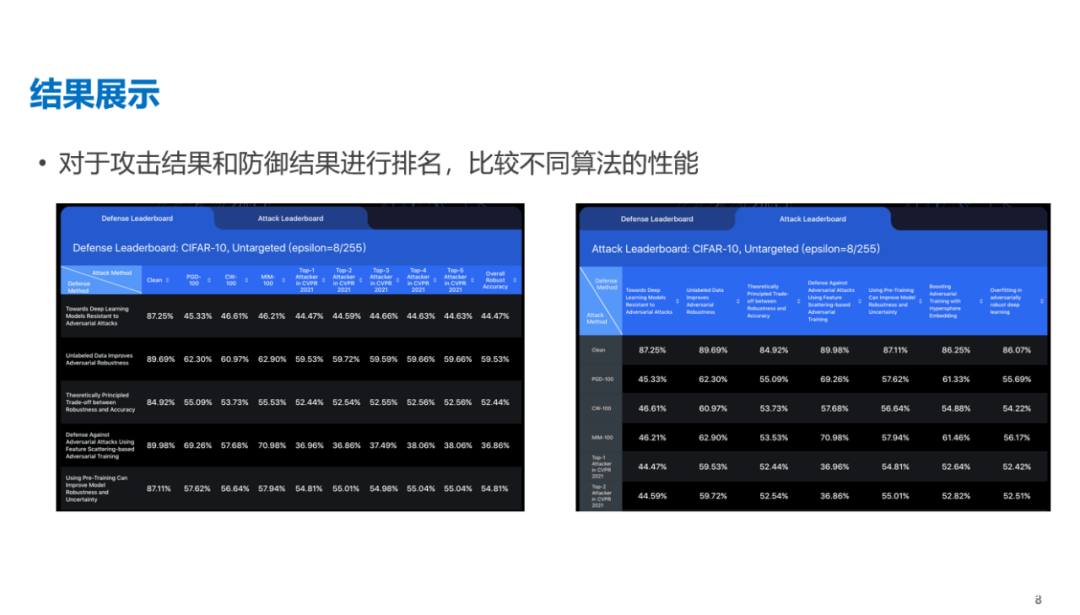
ARES平台,有朱軍教授團隊自行研發的相關攻防算法,有40多個不同類型的防禦模型,支持上層API直接調用。 除了算法庫,還有魯棒性測評工具,支持對圖像分類任務上不同模型的對抗魯棒性進行準確和全面的基準測試。 眾所周知,數據集分為訓練集和測試集,訓練集,訓練模型;測試集,測試模型的性能。因為測試魯棒性所用的測試集很重要,所以,ARES平台採用了公開的CIFAR10和ImageNet數據集。這一成果也被收錄為CVPR2020的Oral論文《基於圖像分類的對抗魯棒性基準》,Benchmarking Adversarial Robustness on Image Classification。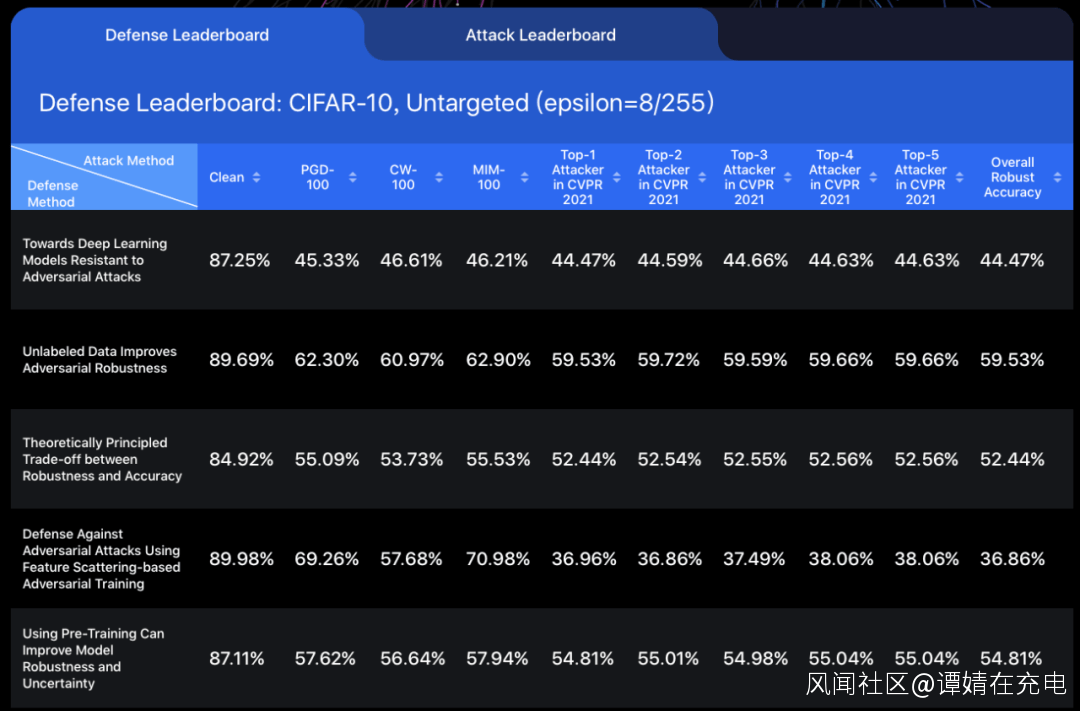 圖示:評測的設定值(setting),CIFAR-10是數據集,Untargeted是攻擊的目標,epsilon是添加擾動大小。
圖示:評測的設定值(setting),CIFAR-10是數據集,Untargeted是攻擊的目標,epsilon是添加擾動大小。 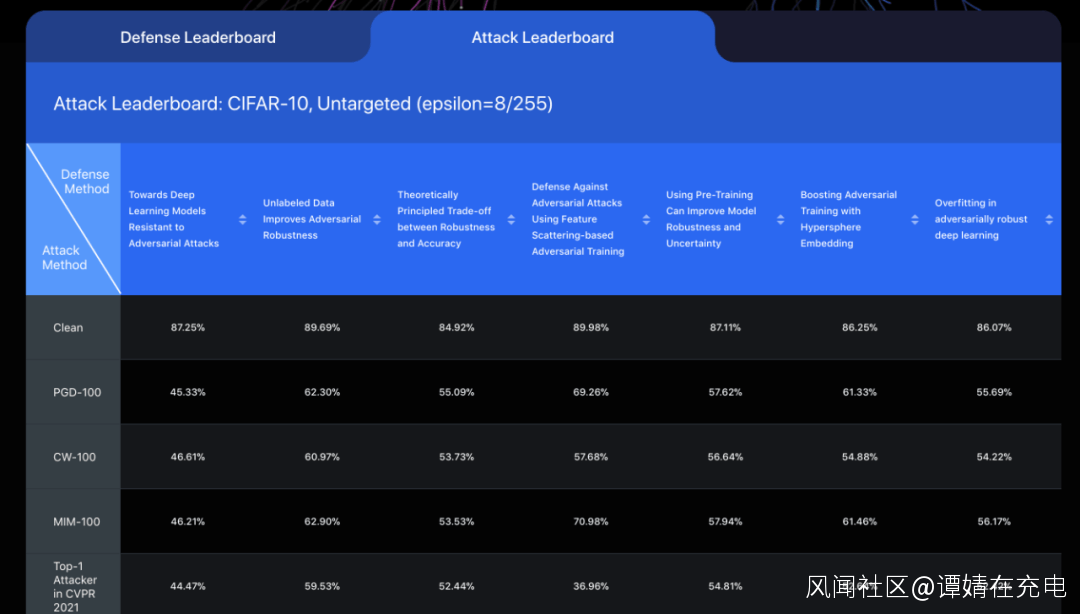 CVPR2021期間,ARES平台也支持了白盒的對抗攻擊競賽(在線運行環境),全球1600多支代表隊的選手在平台提交攻擊算法,在提交的約2000個攻擊算法中,高質量算法大概有100個。 在ARES平台上,為了做得更好,CVPR2021人工智能攻防競賽中排名前五的攻擊算法被收錄,清華大學此前的研究成果也被收錄。 ARES也是目前為止圖像分類領域較為全面的算法魯棒性基準平台。 現有的四大AI 對抗安全算法平台,CleverHans、Foolbox、ART、ARES,均有統一的底層框架和圖像分類領域典型攻防算法,大型交友社區Github上都能測評。但是,只有RobustBench和ARES後續出了網頁版。 AI對抗算法魯棒性基準平台的英文名是AdversarialRobustness Benchmark,也是網頁的名字,Benchmark直譯為“基準”。 平台的發佈時間是在2021年6月,可以理解為一種對攻防算法進行魯棒性排名,可作為參考,也可以視為榜單。 這是國內首個,由清華大學朱軍教授帶頭,瑞萊智慧RealAI和阿里安全團隊均有參與。 時光匆匆,人工智能算法攻與防,也走過了七個年頭的歲月。 是時駐足思考,這一時期推出基準平台有什麼意義? 朱軍教授的理解是: 第一,努力提供一個公開、公平、公正、全面的衡量。第二,一個方便使用的,魯棒性測試工具,人人提交模型,均可以獲取綜合魯棒的分數。第三,不斷引入新的攻擊防禦算法,作為標準測試平台。 新的算法提交到這個網站上,可以看到算法的大概表現。更綜合的測評指標,評估策略更為科學,能給攻防領域的研究提供更多的指導和測評支撐,能全面、客觀地展示最新的攻防方法。 最後,朱軍教授希望和學術界、產業界一起去共建、維護這個公開榜單,讓其成為攻防算法領域的一個標準。 專家觀點:
CVPR2021期間,ARES平台也支持了白盒的對抗攻擊競賽(在線運行環境),全球1600多支代表隊的選手在平台提交攻擊算法,在提交的約2000個攻擊算法中,高質量算法大概有100個。 在ARES平台上,為了做得更好,CVPR2021人工智能攻防競賽中排名前五的攻擊算法被收錄,清華大學此前的研究成果也被收錄。 ARES也是目前為止圖像分類領域較為全面的算法魯棒性基準平台。 現有的四大AI 對抗安全算法平台,CleverHans、Foolbox、ART、ARES,均有統一的底層框架和圖像分類領域典型攻防算法,大型交友社區Github上都能測評。但是,只有RobustBench和ARES後續出了網頁版。 AI對抗算法魯棒性基準平台的英文名是AdversarialRobustness Benchmark,也是網頁的名字,Benchmark直譯為“基準”。 平台的發佈時間是在2021年6月,可以理解為一種對攻防算法進行魯棒性排名,可作為參考,也可以視為榜單。 這是國內首個,由清華大學朱軍教授帶頭,瑞萊智慧RealAI和阿里安全團隊均有參與。 時光匆匆,人工智能算法攻與防,也走過了七個年頭的歲月。 是時駐足思考,這一時期推出基準平台有什麼意義? 朱軍教授的理解是: 第一,努力提供一個公開、公平、公正、全面的衡量。第二,一個方便使用的,魯棒性測試工具,人人提交模型,均可以獲取綜合魯棒的分數。第三,不斷引入新的攻擊防禦算法,作為標準測試平台。 新的算法提交到這個網站上,可以看到算法的大概表現。更綜合的測評指標,評估策略更為科學,能給攻防領域的研究提供更多的指導和測評支撐,能全面、客觀地展示最新的攻防方法。 最後,朱軍教授希望和學術界、產業界一起去共建、維護這個公開榜單,讓其成為攻防算法領域的一個標準。 專家觀點:  阿里安全高級算法專家,越豐:像打仗一樣,攻擊者可能用水攻,也可能火攻,還可能偷偷挖條地道來攻打一座城,守城的人不能只考慮一種可能性,必須佈防應對許多的攻擊可能性,尤其要關注惡意攻擊者對數據或樣本進行“投毒”,故意影響AI模型的攻擊行為。
阿里安全高級算法專家,越豐:像打仗一樣,攻擊者可能用水攻,也可能火攻,還可能偷偷挖條地道來攻打一座城,守城的人不能只考慮一種可能性,必須佈防應對許多的攻擊可能性,尤其要關注惡意攻擊者對數據或樣本進行“投毒”,故意影響AI模型的攻擊行為。 瑞萊智慧 RealAI CEO,田天博士:算法安全,比較典型的就是對抗樣本,它是深度學習範式下人工智能存在的一種缺陷,通過算法修改為樣本攻擊提供深層次的攻擊,而且已經成為了主流的技術趨勢。
瑞萊智慧 RealAI CEO,田天博士:算法安全,比較典型的就是對抗樣本,它是深度學習範式下人工智能存在的一種缺陷,通過算法修改為樣本攻擊提供深層次的攻擊,而且已經成為了主流的技術趨勢。  伊利諾伊大學(UIUC)計算機科學系助理教授,李博:機器學習在推理和決策的快速發展,已使其廣泛部署於自動駕駛、智慧城市、智能醫療等應用中。但是,傳統的機器學習系統通常假定訓練和測試數據遵循相同或相似的分佈,並未考慮到潛在攻擊者惡意會修改訓練和測試數據這兩種數據的分佈。 這相當於在一個人成長的過程中,故意進行錯誤的行為引導。惡意攻擊者可以在測試時設計小幅度擾動,誤導機器學習模型的預測,或將精心設計的惡意實例注入訓練數據中,通過攻擊訓練引發AI系統產生錯誤判斷。 好比是從AI“基因”上就做了改變,讓AI在訓練過程中按錯誤的樣本進行訓練,最終變成被操控的“傀儡”,只是使用的人全然不知。深入研究潛在針對機器學習模型的攻擊算法,對提高機器學習安全性與可信賴性有重要意義。 本文致謝,董胤蓬博士,沒有他的講解,很難完成梳理。
伊利諾伊大學(UIUC)計算機科學系助理教授,李博:機器學習在推理和決策的快速發展,已使其廣泛部署於自動駕駛、智慧城市、智能醫療等應用中。但是,傳統的機器學習系統通常假定訓練和測試數據遵循相同或相似的分佈,並未考慮到潛在攻擊者惡意會修改訓練和測試數據這兩種數據的分佈。 這相當於在一個人成長的過程中,故意進行錯誤的行為引導。惡意攻擊者可以在測試時設計小幅度擾動,誤導機器學習模型的預測,或將精心設計的惡意實例注入訓練數據中,通過攻擊訓練引發AI系統產生錯誤判斷。 好比是從AI“基因”上就做了改變,讓AI在訓練過程中按錯誤的樣本進行訓練,最終變成被操控的“傀儡”,只是使用的人全然不知。深入研究潛在針對機器學習模型的攻擊算法,對提高機器學習安全性與可信賴性有重要意義。 本文致謝,董胤蓬博士,沒有他的講解,很難完成梳理。  他是清華大學計算機系四年級博士生,導師為朱軍教授,負責AI攻防算法的研究與落地。主要研究方向為機器學習與計算機視覺,聚焦深度學習魯棒性的研究,先後發表CVPR、NeurIPS、IJCV等頂級國際會議及期刊論文二十餘篇。曾是ICML、NeurIPS、ICLR、CVPR、ICCV、TPAMI等會議和期刊的審稿人。曾獲得國家獎學金,清華大學未來學者獎學金、CCF-CV學術新鋭獎、微軟獎學金、百度獎學金等。在NeurIPS 2017人工智能對抗性攻防大賽中獲得全部三個比賽項目的冠軍。這次分離 不説再見 以下是朱軍教授的PPT,自取,不謝。
他是清華大學計算機系四年級博士生,導師為朱軍教授,負責AI攻防算法的研究與落地。主要研究方向為機器學習與計算機視覺,聚焦深度學習魯棒性的研究,先後發表CVPR、NeurIPS、IJCV等頂級國際會議及期刊論文二十餘篇。曾是ICML、NeurIPS、ICLR、CVPR、ICCV、TPAMI等會議和期刊的審稿人。曾獲得國家獎學金,清華大學未來學者獎學金、CCF-CV學術新鋭獎、微軟獎學金、百度獎學金等。在NeurIPS 2017人工智能對抗性攻防大賽中獲得全部三個比賽項目的冠軍。這次分離 不説再見 以下是朱軍教授的PPT,自取,不謝。





 可獲得朱軍教授PPT。更多閲讀:搞深度學習框架的那幫人,不是瘋子,就是騙子七分之一在線評論都有假,人工智能救一把?難倒劉強東的奧數題,京東智能供應鏈解開了超級計算機與人工智能:大國超算,無人領航消失的人工智能 “法外之地”孩子心臟發育不好,我要存孩子的心電數據電子地圖“頑疾”難治,會“傳染”自動駕駛專用高精地圖嗎?
可獲得朱軍教授PPT。更多閲讀:搞深度學習框架的那幫人,不是瘋子,就是騙子七分之一在線評論都有假,人工智能救一把?難倒劉強東的奧數題,京東智能供應鏈解開了超級計算機與人工智能:大國超算,無人領航消失的人工智能 “法外之地”孩子心臟發育不好,我要存孩子的心電數據電子地圖“頑疾”難治,會“傳染”自動駕駛專用高精地圖嗎? 最後,再介紹一下主編自己吧。我是譚婧,科技和科普題材作者。圍追科技大神,堵截科技公司。生命短暫,不走捷徑。還想看我的文章,就關注“親愛的數據”。
最後,再介紹一下主編自己吧。我是譚婧,科技和科普題材作者。圍追科技大神,堵截科技公司。生命短暫,不走捷徑。還想看我的文章,就關注“親愛的數據”。 親愛的數據順着數據寫人工智能, 順着技術寫產業落地。
親愛的數據順着數據寫人工智能, 順着技術寫產業落地。