程序員至死是少年!在公司竟公然變身聖鬥士_風聞
量子位-量子位官方账号-2021-07-20 13:55
楊淨 蕭簫 發自 凹非寺
量子位 報道 | 公眾號 QbitAI
最近,我身邊的朋友,突然一個個都變成了聖鬥士!
像這種比較炫酷的“飛天”黃金聖鬥士,連影子都惟妙惟肖的:

還有這種在辦公室偷偷變身雙子座聖鬥士,想要拯救世界的:

又或者是在自家小花園裏變成處女座聖鬥士,打破次元壁的:

還有白羊座、天秤座、射手座聖鬥士……怎麼回事?
原來,這是一羣程序員做出的移動端3D聖衣特效,現在只用一部手機,就能隨時隨地“變身”聖鬥士。

又一童年夢想被實現了有木有!
如果不想打開攝像頭,也可以只用一張照片,就能成功“變裝”:

不過,要實現這樣貼合的效果並不容易,單從技術本身來看,就充滿了挑戰性。
在他們之前,甚至根本就沒有人將這類技術應用到手機上。
而整個項目也是聯合渲染、設計兩個團隊,一鼓作氣耗時10個月才完成。
畢竟要守護心中的雅典娜,多少付出都是值得。
電影遊戲界的“重金特效師”
這項耗時10個月打造的技術,就是好萊塢大片和3A(高開發成本)遊戲大作中才會用到的動作捕捉。
説到這項技術,或許有的人還會感到陌生,但像《阿凡達》《指環王》這樣的好萊塢電影、或是《刺客信條》《生化危機》這樣的3A遊戲,你一定聽説過。
沒錯,這其中的許多經典特效、角色動作設計,都採用了動作捕捉技術。

由於能直接記錄動作,這項技術能大幅縮短製作特效的時間,同時能讓角色表情、動作看起來更真實。
對手K動畫設計師來説,能降低設計工作量;對虛擬直播(Vtuber)、體育和醫療等領域來説,動作捕捉不僅能實現逼真的動作還原,還能實現實時動作記錄。
聽起來非常誘人,但這其實是一項高門檻技術。
首先,要想實現逼真的動作還原效果,就必須對硬件提出高要求,主流的慣性和光學動作捕捉技術,基本都需要傳感器,便宜的效果還不好。
以(慣性動捕)遊戲《舞力全開》為例,雖然硬件成本低廉(甚至能用手機當傳感器),但由於只有手部傳感器,無法檢測腿部活動,體驗並不好,還誕生出了像“輪椅舞王”這樣的梗。

其次,為了將干擾、延遲降至最低,需要預留空間。以專業的Vtuber(虛擬主播)為例,他們直播所採用的動作捕捉技術,基本都需要****10×10米的大房間來降低干擾。

最後,數據計算量大。動作捕捉系統獲得的只是一大堆座標數據,後期不僅要進行專業數據處理,同時還需要高性能計算機顯卡來實現。
集硬件成本、環境、計算量等限制為一身的動作捕捉,要是之前説要把它用到手機上,可能立刻會有人説這是痴人説夢。
然而科技的發展總能給我們帶來意想不到的效果。
微視團隊中一羣做計算機視覺的程序員,就只用一部手機將黃金聖鬥士的鎧甲貼合在人物身上,而且確實成功了,實現了實時的處理效果。
但手機端動作捕捉技術,並不好做。
自研移動端算法,篩選7k+頂點
只用一部普通的手機,意味着兩個難點:計算量受限、座標深度只能靠預測。
相機生成的照片,通常只有2D信息。要想從2D中還原出3D信息,需要找到一個能夠預測座標深度的函數,使之預測的3D信息儘可能逼近真實值。
對於真實度要求很高的動作捕捉技術而言,這意味着精度和實時性都要受到挑戰。
目前已有的移動端AI技術,只能實現實時動作捕捉的一部分功能,包括人體/人臉檢測、和基於2D/3D骨骼關鍵點的姿態估計技術,也就是我們常見的“火柴人”算法。

但“火柴人”算法顯然沒有3D Mesh貼合度高,因此團隊決定,將3D Mesh搬到移動端上,自研一套基於3D Mesh的移動端姿態估計算法。
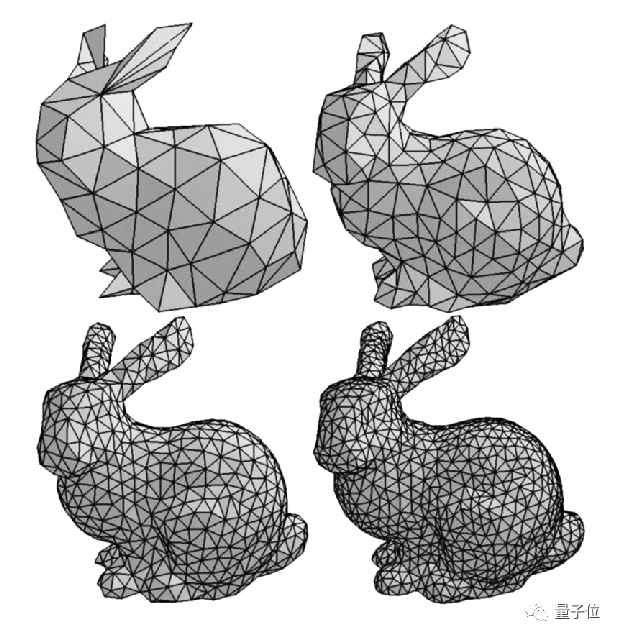
這套算法相當於重建人體表面的7000多個特徵點,以及15000多個三角面片,不僅能夠還原人體的基本動作,還能預測出人體的高矮胖瘦。

除此之外,團隊還從3個方面,對模型進行了整體優化。
其一,從動作捕捉精度和模型大小兩方面,對自研模型進行調試。
據微視團隊表示,移動端已有的基於3D骨骼關鍵點的驅動閥,雖然可以驅動虛擬人體,在同一場景下做各種動作,但這套算法存在一些不足,需要自行調整。
例如,算法偶爾會出現不正常的抖動,包括虛擬人物突然“形變”的情況,如下圖腳掌翻轉。為此,團隊還給算法加上了平滑濾波,使得人物動作看起來更真實,進一步提升模型精度,避免像下面這種抖動。

****△腳掌不正常的翻轉抖動
同時,在精度以外,團隊還要保證在移動端實現3D Mesh。為了做到這一點,除了在其他模型方面儘可能整合壓縮以外,團隊也對模型本身進行了一個簡化。
其二,從數據採集來看,團隊也下了不少功夫。
由於移動端3D Mesh數據需針對性採集,微視團隊搭建了自動化的數據採集系統,幫助快速採集到高質量動捕數據。

雖然Kinect的實時動作捕捉效果一般,但用於數據採集還是非常不錯的,三台結合起來就能獲得完整的深度信息。

為了確保模型的泛化性,除了儘可能多找18~60歲的不同人物數據進行採集以外,程序員們還採用了數據增強和半監督學習來增強模型的泛化能力。
在數據增強這塊,為了加強模型辨認人體與周圍環境的能力,程序員們將獲取到人體的mask信息進行提取,隨機貼到其他背景的圖片上,創造出更多不同背景信息的圖片;同時,團隊也採用了神經渲染、GAN等技術,來生成更多的訓練數據。
在半監督學習上,程序員們結合輔助任務,對2D關鍵點模型進行訓練、提升模型的泛化能力。
其三,就是團隊對實時性和特效渲染做的兼顧。
模型結構的整體設計和優化都只是“基本操作”,例如將串聯運行的模型改成並聯運行等;在推理上,團隊還基於優圖的TNN移動端深度推理框架,實現了模型的高效推理,最終將模型的推理時間從15ms降低到了11ms。
這裏面的一個難點,就是要確保渲染效果和移動端性能(實時性)的兼顧,既要讓畫面看起來比較精緻,又不能讓軟件運行速度太慢。
因此,團隊先採用了自研3D渲染引擎增強光影效果,並利用SSAO、IBL等技術增強陰暗角落處的陰影質量,使得整體渲染效果與目前主流手遊非常接近;

同時又進一步適配不同機型,採取分級策略,確保在各種手機上都能取得不錯的運行性能。

顯然,要想實現上面這些技術,呈現出最終的聖鬥士特效,微視的設計師們同樣功不可沒。
甚至可以説,微視團隊中,就連設計師也都是“技術硬核”的存在。
設計師也學代碼?
從最初產生想法、打磨研發,一直到最終呈現,10個月的時間,對於一個研發團隊來説並不短。
當中,除了技術本身的實現難度之外,還牽涉到整個系統的協同配合。
從最開始的CV技術研發、到移動端的部署,以及渲染,最後製作成一個特效工具……整個技術生產鏈條的打通需要各個團隊充分合作。
就比如,像把盔甲穿在人身上,這樣一個看似簡單的動作,就需要開發、算法、設計三個組的同學協同調整。

一位設計組的旁友直呼:這部分的鑽研和調整超過了製作模型的時間。
但即便如此,他們也有自己的制勝法寶。
首先,目標一致。
大概也是因為圍繞聖鬥士這一主題,團隊內部也有很多的年輕人,所以整個技術磨合階段並沒有出現過什麼Battle。
嗯,為了同一個夢想,各自都在燃燒自己的小宇宙!
另外小小劇透一下,由於整個鏈條已經打通,接下來團隊會用技術做一些發散,嘗試其他IP角色。
(瘋狂暗示)

其次,就是技術思維。
即便是與核心技術沒有那麼強關係的設計組,也坦言前沿技術的更迭很快。
可能去年學的新技術,可能到今年就已經過時了,要多花時間一些時間鑽研前沿技術。
尤其是在被問到給當前要畢業的設計同學建議時,更是言簡意賅:
學點代碼,很有幫助。
確實很技術,很硬核。
一邊不斷接觸各種前沿技術,享受着從研發到落地整個鏈條,另一邊還能完成“拯救世界”和“守護女神”的夢想,這是團隊內部提及最多的成就感。
也唯因如此,才能將硬核技術攻克下來,成為每個人都能觸達的好玩特效。
最後還想再替相信「光」的年輕人問一句:
奧特曼,真的不打算安排上麼?