AI程序員GitHub Copilot,生成代碼有侵權風險_風聞
壹零社-最新鲜的互联网产业资讯2021-07-20 11:08
AI 編程是人們對人工智能的一大期望,現在的 AI 編程技術雖然已經惠及了許多不會編程的普通用户,但還遠沒有達到滿足人們預期的程度,一大痛點在於:AI如何靈活處理程序員的需求,而非進行機械地記憶與複製粘貼代碼。這不,微軟、GitHub、OpenAI 三方聯手發佈了人工智能代碼建議方案——GitHub Copilot,可以在程序員編碼的時候自動推薦或生成代碼供其使用,程序員再也不用因為敲代碼而加班了!
1.GitHub Copilot究竟是什麼?
簡單來説,GitHub Copilot 可以視為一位與開發者協作編寫代碼的虛擬程序員。它可以根據當前代碼中已有的字符串、註釋、函數名亦或是代碼上下文語義,自動生產一行或多行代碼或建議,供程序員選擇。隨着程序員接受或拒絕建議,該模型會隨着時間的推移,不斷地學習且變得更加智能與複雜。在它的幫助下開發者用能更少的時間更快地編寫代碼。
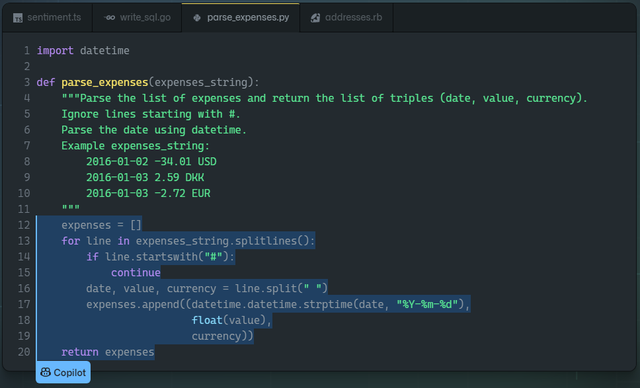
GitHub是微軟2018年以75億美元收購的全球知名代碼託管平台,因此Copilot擁有了可供訓練的TB級的公共代碼。微軟在2019年向非營利人工智能研究機構OpenAI投資10億美元,用於開發 AGI(通用人工智能)平台。此次 GitHub Copilot V0.1版發佈,就是三方合力研發的重大成果之一。
Copilot建立在OpenAI全新的Codex算法之上,Codex是先進AI語言模型GPT-3的一種延伸版本,該模型接受了從GitHub中提取的TB級公開源代碼和英語自然語言的訓練,因此它能同時理解編程語言和人類語言。在Azure雲計算能力和內部多重安全機制的輔助下,Copilot可以做到分析文檔中的字符串、註釋、函數名稱以及代碼本身,從而生成新的安全、高質量的代碼。目前Copilot支持幾種熱門編程語言:Python、JavaScript、TypeScript、Ruby和Go。目前已有少量GitHub用户收到試用邀請,在Visual Studio Code中可以啓用Copilot擴展。
至於Copilot的編程水平如何,有人把它拉去做LeetCode的題庫,它每次都能實時的生成可以通過LeetCode測試的代碼,這種好的過分的成績讓人懷疑Copilot已經在LeetCode數據庫上進行過訓練。而微軟公佈的一項基準測試結果表明,以一組在開源存儲庫中具有良好覆蓋率的Python函數為測試對象,在清除函數體之後,使用GitHub Copilot來填充代碼。該模型在第一次嘗試時正確率達43%,經過10次的嘗試之後,正確率提升到了57%。而GitHub的員工在內部試用後多數人給出了將保留開啓GitHub Copilot提示的正面評價。
GitHub則表示GitHub Copilot建議的代碼並不完美,有時候它提供的代碼甚至毫無意義。在開發過程中,開發者仍然是主導,對它建議的代碼要像任何其他代碼一樣經過仔細測試和審查。
2.抄襲代碼
對於GitHub Copilot是否會直接複製代碼的問題,GitHub表示“只有0.1%的情況下,GitHub Copilot 提供的代碼建議中可能包含一些來自訓練集的字符或片段。”
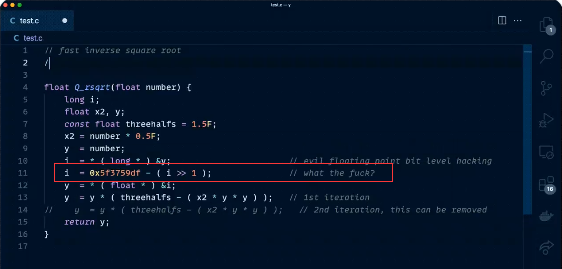
但是,有網友公佈了他的發現:讓 GitHub Copilot 生成快速平方根倒數算法(Fast Inverse Square Root),結果代碼竟與《雷神之錘 3》中那段傳奇代碼一模一樣,連那句著名的“What the fuck?”註釋也抄了下來!
快速平方根倒數算法也稱為平方根倒數速算法,這個算法可以高效的輸出浮點數的對應近似值,極大得減輕了3D圖像演算的壓力。此算法因在《雷神之錘3》源代碼中被引用時連開發者也看不懂其中一個神奇的常數“0x5f3759df”的取值原理,留下了那句著名的吐槽而被人們所熟知。如此一來,GitHub Copilot抄襲代碼成了“真·雷神之錘”。
因此人們對於使用GitHub Copilot開發是否更容易導致侵權,並因此引起的版權糾紛的責任劃分有了更多的疑慮。
3.有侵權風險
在討論GitHub Copilot侵權問題前,我們需要先了解一個概念:GPL(GNU通用公共許可證),它是自由軟件和開源軟件中使用最廣泛的許可協議。最初由理查德·斯托曼為GNU計劃而撰寫,目前最新版本為第3版。GPL定義了自由軟件:以任何目的運行此程序的自由;再發行復製件的自由;改進此程序,並公開發布改進的自由。它通過斯托曼發明的Copyleft的法律機制實現,要求任何包含該開源許可證的衍生作品,即使僅有幾行代碼,也必須免費提供全部源代碼以及修改和分發它們的權利。
在此基礎上,就產生了一個巨大爭議:GitHub Copilot使用了大量遵循GPL協議的代碼用於訓練,那麼機器學習系統產生的作品,甚至機器學習系統本身,都算是GPL協議中規定的衍生作品嗎?
長期關注版權保護問題以及開源和自由軟件的Julia Reda堅定的認為GitHub Copilot 並未侵犯開發者的版權。她指出,簡單地閲讀和處理信息並不需要版權許可。舉個例子,如果你去書店,從書架上拿一本書開始閲讀,在這個過程中你是沒有侵犯任何版權的,而人工智能這類數字技術的訓練過程就是如此。她表示:“版權和數字技術之間的確因此會有許多衝突,所幸政策制定者和法院早就意識到:如果每個技術副本都需要許可,那麼數字技術將完全無法發展使用。”
甚至,Julia Reda 還認為機器自動生成的代碼也不能視為衍生作品。首先,認為即使複製受版權保護作品的最小摘錄也構成侵犯版權,這很不合理。如果兩個或多個開發人員在各自的程序中使用相同的基本代碼,豈不是會產生無窮無盡的爭議?其次,版權法只適用於智力創作——沒有創作者,就沒有作品。也就是説像 GitHub Copilot 這樣的機器生成代碼根本不符合版權保護的條件,因此也並不是衍生作品。
但是如果GitHub Copilot自動生成的代碼不被視為衍生作品,那麼對於開發者利用GitHub Copilot將本來是遵循開源協議的代碼“清洗”成不用遵守任何協議的代碼,由此產生的版權糾紛,責任人究竟是付費使用GitHub Copilot軟件開發者呢,還是GitHub Copilot的開發商GitHub和微軟呢?
由於GitHub Copilot要在未來擴展為付費服務。支持開源的人們紛紛譴責GitHub,他們認為利用了大量開源資源開發的GitHub Copilot本身就應該是一個開源項目。現在本應開源的GitHub Copilot反而可能成為將開源代碼協議“清洗”掉的幫兇。支持開源的開發者們的勞動成果在AI程序員的搬運之下反而變成了大企業的賺錢工具。
對於這些質疑,GitHub的CEO回應:我們正在構建一個源跟蹤器,避免在輸出中直接引用訓練數據,也幫助用户對它提出的建議做出良好的實時決策。
4.前途遠大
讓AI學會寫程序——直接用自然語言描述想幹什麼,AI就能自動生成相應的程序。現有的 技術顯然還遠達不到這種預期。評判一個AI系統是否具有“組合泛化”(Compositional Generalization)的能力就是評價AI能力高低的關鍵。
通俗地説,就是AI程序員是否具備“舉一反三”的能力:能夠將已知的複雜對象(程序)解構為多個已知簡單對象的組合,並據此理解和生成這些已知簡單對象的未知複雜組合。以往的深度學習模型的特長更多在於直接記憶與模仿而缺乏組合泛化能力,一旦新問題超出訓練集準確率就會降到個位數。
從GitHub Copilot的表現來看,這種新的人工智能是具有一定的組合泛化能力的,當前的GitHub Copilot僅是V0.1版,尚處於技術預覽版階段,應用起來雖然還不是太過完美,但功能的確強大。這仍然是人工智能領域的一項重大的突破。你可以在https://copilot.github.com 申請體驗。