大數據算法:知心朋友還是認知牢籠?_風聞
文化产业评论-文化产业评论官方账号-2021-08-13 07:42
如今,推薦算法在網絡生活中的重要作用無需贅言,而自算法時代以來,倫理一直是懸在算法頭頂上的達摩克里斯之劍。8月2日,中央宣傳部等五部門聯合印發了《關於加強新時代文藝評論工作的指導意見》,提出健全完善基於大數據的評價方式,加強網絡算法研究和引導,開展網絡算法推薦綜合治理,不給錯誤內容提供傳播渠道。對推薦算法的規制再次被提上日程。就影視平台而言,推薦算法在一味地迎合用户的口味的過程中,不可避免地造成了趣味圈層化、品味低俗化和選擇被動化的弊病。然而不論如何,算法時代已經到來,既然日常生活已然離不開它,如何與算法文化相處是現在所要面臨的唯一問題。
作者 | 王藝璇(文化產業評論作者團)
編輯 | 斯琴
來源 | 文化產業評論
正文共計5376字 | 預計閲讀時間14分鐘
在互聯網時代,每時每刻都有大量的內容被生產出來,不論是短視頻還是傳統影視作品,都是人窮盡一生也無法看完的。將內容與其目標受眾連接起來,是影視平台的主要任務。除了用户主動的檢索行為之外,通過推薦算法所得出的主頁展示是另外一條途徑。

在眾多影視平台之中,Netflix算是影像內容個性化推薦的先行者。它從2006年懸賞百萬美元進行推薦算法大賽開始,就一直致力於不斷優化面向用户消費需求的影像內容推薦系統。如今,Netflix用户平均每3個小時的視頻播放時長中就有2個小時是來自於首頁的推薦內容。
Netflix的現行的推薦算法綜合考慮到短期熱點,用户的興趣點以及用户的觀看場景。除了用於推薦內容本身之外,推薦算法還用於平台選擇推薦方式。**Netflix針對每一部電影都製作了30-40份海報,每份海報的側重點不同。**由於每一部電影對於不同人的吸引點也各不相同,有的因為類型對胃口,有的因為某位明星加盟,所以Netflix通過將側重點各異的海報分發到不同的受眾羣體,以提升播放的轉化率。
相較而言,國內的視頻平台的推薦算法起步較晚,但是發展迅猛。愛奇藝於2013年推出了業界第一個智能推薦的客户端,僅兩年之後,用户瀏覽的推薦內容就佔到了總流量的30%。
優酷的個性化推薦則從2017年下半年開始部分推行,2018年才全面推廣。不過憑藉阿里的龐大用户數據,優酷在用户肖像上有着天然的優勢。2018年優酷認知實驗室成立,在視頻結構分析和內容智能生成上進行了提升改進。視頻的結構分析也就是直接從聲畫中提取信息,進一步精細化視頻元素;而內容智能生成主要應用於海報,以達到前述Netflix推薦方式個性化的效果。
可以説,推薦算法是各大影視平台博弈中的重要戰場。
人工智能還是人工智障
説起來,推薦算法自誕生伊始就跟影視有着深厚的淵源。
推薦算法的研究起源於20世紀90年代,由美國明尼蘇達大學 GroupLens研究小組最先開始研究,他們想要製作一個名為 Movielens的電影推薦系統,從而實現對用户進行電影的個性化推薦。首先研究小組讓用户對自己看過的電影進行評分,然後小組對用户評價的結果進行分析,並預測出用户對並未看過的電影的興趣度,從而向他們推薦從未看過並可能感興趣的電影。
也就是説,早在彼時算法的邏輯就已經初具雛形了,互聯網時代的到來為算法提供了大量的可供處理的信息,此後,推薦算法才成為視頻平台的制勝法寶。
總結起來,現在各影視平台所用的紛繁複雜的推薦算法不外乎兩條根本邏輯:一個是協同過濾算法,一個是基於內容的推薦算法。
協同過濾算法(Collaborative Filtering,簡稱CF),也就是根據所有用户的歷史數據,來推測每個用户當下所可能感興趣的內容。這種方法將用户-內容的評級矩陣作為輸入數據,輸出的則是用户對每一個尚未接觸過的內容的預估興趣值,並依次將內容排序推薦給用户。
協同過濾算法的優勢是不需要關於內容本身的任何參數,也就是説,內容是什麼不重要,誰喜歡它才重要。因此,許多平台的相似推薦會採用“喜歡這部電影的人也喜歡”這種表述。同樣,當韓國導演洪尚秀的電影《引見》的相似推薦中,同時出現蔡明亮、濱口龍介和赫爾佐格的作品時,我們也就不必驚訝,因為在協同過濾的邏輯下,正是影迷的選擇造就了不同時期、不同國別、不同風格的導演之間強有力的連結。
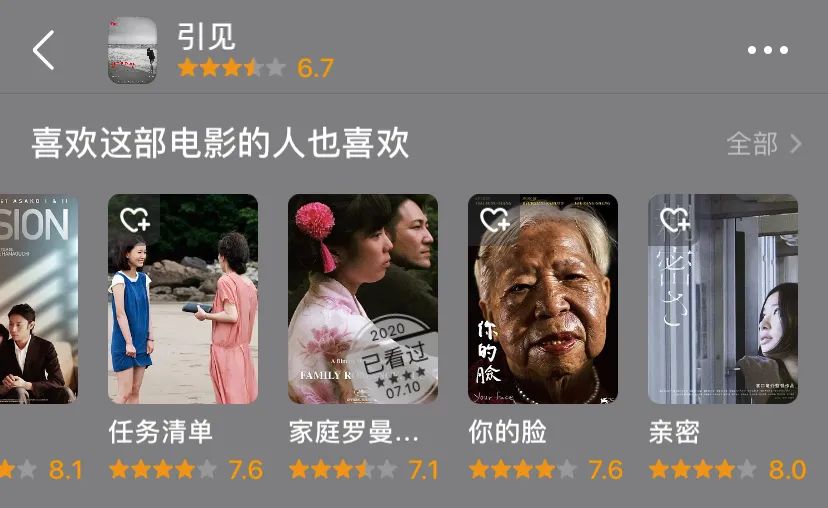
**由於不需要關於內容的任何信息,協同過濾算法被廣泛應用於電影和音樂這種難以量化的內容的推薦上。**它最大的問題就是需要豐富的歷史數據和龐大的用户羣體,因此難以應用於平台誕生之初。
第二種是基於內容的推薦算法(Content-Based Filtering簡稱CBF),也就是根據內容的分類信息為用户推薦相似的內容。此時的輸入數據是用户的偏好,以及內容的屬性,輸出的是最符合用户偏好的內容。
不難想象,對於影視而言,基於內容的推薦算法最大的挑戰來源於影視內容的難以量化,往往要使用高昂的人工成本。在這方法做到極致的仍是Netflix。
早在2006年,Netflix產品副總裁託德·耶林便帶領團隊為影視內容貼上“微標籤”。這一方法也被其設計者賦予一個極具數理色彩的名稱——“Netflix量子理論”。在具體操作中,Netflix僱傭獨立評論者來看片,並從1000多個標籤中進行選擇以描述他們所看到的內容,如血腥程度,浪漫程度,情節結論性等,由此生成了豐富的“微類型”。微類型的總量竟達76897種之多,比如“情感充沛的反體制紀錄片”“基於真實生活的皇室掠影”,都是所謂的“微類型” ,其描述方式幾乎要突破語言的極限。
基於內容的推薦算法需要耗費大量人力,協同過濾算法則難以應對缺乏數據的“冷啓動”過程。此外,兩種算法所共同面臨的另一個難題是用户興趣漂移,即用户的興趣點隨着時間變化,長期推送相似的內容會讓用户感到乏味。為此,許多模型通過加入艾賓浩斯遺忘曲線,滑動窗口,長短期興趣模型等方法進行改進。
不過,有時算法所設定的過快的更換速度也容易讓用户措手不及。假如用户本着好奇心進入了自己本不熟悉的內容,又一不小心看完了,結果第二天首頁可能被相似內容全部佔領。説到底每個人的遺忘速度也是不一樣的。人心難測,和所有現在的弱人工智能一樣,推薦算法距離測量人心還有相當的距離。

推薦算法的“三宗罪”
自推薦算法成為影視平台競相比拼的競爭力後,對推薦算法的詬病就從沒有停止過。在算法邏輯之下,內容的價值單純地被點擊率、播放完成率等指標所取代,在此之下,趣味圈層化、內容低俗化和選擇被動化可以説是推薦算法的三宗原罪。
趣味圈層化
推薦算法的問題之一就是趣味圈層化,用術語可以表示為“信息繭房”或是“過濾泡泡”。
“過濾泡泡”這個概念由Eli Pariser在2010年提出,指的是在算法推薦機制下,高度同質化的信息流會阻礙人們認識真實的世界。“信息繭房”由美國學者桑斯坦提出,是指算法使每個人都沉浸在自己想要看到的內容中,進一步壓抑羣體共識。雖然側重點不同,但是這兩個概念共同指向了算法對個體認知客觀世界造成的挑戰。

反映在影視推薦平台上,“信息繭房”或“過濾泡泡”首先造成了“聚類”與“區隔”。
在推薦算法投其所好的投餵下,令觀者感興趣的內容佔滿整塊屏幕,雖然算法幫助小眾愛好者在茫茫人海中找到彼此,但是在加速“聚類”的同時,也加深了不同羣體之間的認知的溝壑,其結果是人們只跟與自己相似的用户分享趣味和觀點。
內容低俗化
如果説趣味圈層化的問題還是存有爭議的話,那麼內容低俗化的罪名可以説是鐵板釘釘的。在低俗的內容面前,任何其他的風格特徵都顯得缺少競爭力。如果單純以點擊量為目標的話而不設置其他限制的話,那麼內容走向低俗幾乎是個必然。
內容低俗化的問題在短視頻平台較為嚴重,因為獵奇是絕大多數人的心理弱點,一條接一條的獵奇內容就像一口接一口的垃圾食品一樣停不下來。相信不少人都有這樣的經歷,就是儘管嚴格控制自己手機上的觀看內容,但是在擁擠的公交地鐵上不經意地瞥見旁邊人正在觀看的獵奇內容,仍會被牢牢地鎖住目光。
低俗和獵奇的內容充斥着屏幕,不僅會造成時間的浪費,虛假的內容也會對用户造成誤導。被網友親切地稱為藏狐的科普up主張辰亮,就專門製作網絡生物鑑定的短視頻,來闢謠高熱度的獵奇視頻中的虛假信息。其中很多的網絡視頻偽造了民間傳説中的“水猴子”,儘管小亮反覆闢謠“水猴子”,但是還是有更多的“水猴子”被偽造出來。

“水猴子”是二十世紀最大的謠言之一,傳説中的“水猴子”刀槍不入,趁人不備拖人下水。對“水猴子”的恐懼曾對建國之初的生產和建設造成了不小的危害。在今天,“流量即正義”的算法邏輯仍難以避免這些虛假內容的傳播,也正因為推薦算法的這一缺陷,和“水猴子”的鬥爭仍有賴小亮們的堅持。

選擇被動化
相較於前兩樁指控,選擇被動化的指控更接近於算法的根源性問題。
如果把影視的內容比作精神口糧,那麼每天打開平台就可以受到主頁精準投餵的用户,正在逐漸失去主動覓食的能力。儘管投餵的內容可能是更加可口美味的,但是就用户與平台之間的權利關係而言,推薦算法奠定了平台主動權。
個體意義上的被動是顯而易見的,在推薦算法面前,甚至很多“主動覓食”的嘗試都顯得徒勞。試想,有多少人本想檢索一下自己感興趣的內容,卻在打開主頁的一瞬間淪陷於精心排布的主頁內容之中。在慣性的觀看行為之下,推薦算法成了時間的黑洞。

而從更宏觀的層面來看,用户與其説是被算法操縱,毋寧説是被算法背後的資本所裹挾。用户一旦習慣於被動接受,算法就擁有了掌控用户趣味甚至認知的能力。這個能力被怎樣使用,只是資本與技術以怎樣的方式合謀的問題。
對抗與共存
儘管對於推薦算法的諸多弊病已經被討論多年,但是在海量的內容之中,想要脱離算法的掌控,已經是不可能的事。除了社會層面上更嚴格的規制之外,在個體層面上,一些年輕人執着於抹去自己在平台上留下的一切痕跡,以略顯徒勞的方式與推薦算法對抗。
**他們本着“不點贊、不評論、不關注、不登錄”的四不原則,****只要讓算法猜不透我,也就對我無可奈何。**然而,這種絕交式的對抗策略,在抵制算法的誘惑的同時,也放棄了算法帶來的便利,而算法的初衷是幫助用户找到與其需求相匹配的內容。
此外,從技術源頭上深度考慮用户的行為與需求矛盾的實驗也在進行。

IBM的研究員和麻省理工媒介實驗室(MIT Media Lab)發展出了一種AI推薦技術,能夠兼顧用户的喜好與道德準則。不同於此前靜態的規則設置,這種技術可以在實例中學習道德準則,正如其可以學習用户偏好那樣,並最終在道德準則和用户偏好中做一權衡。該方法首先被用於青少年電影推薦,因為在電影推薦中,青少年的偏好和成年人對他們的限制衝突最為明顯。
在實驗中,父母為孩子設定色情與暴力的尺度,算法在父母的要求和孩子的偏好之間做出權衡。該方法還被用於計算藥物的劑量,在醫生追求的穩妥和患者追求的生活質量之間進行平衡給出推薦方案。
儘管該方法在親子電影推薦和醫患用藥建議情況下表現良好,但在只涉及一個用户的環境中會遇到限制。在這種情況下,用户將負責定義他們自己的道德準則和約束,而他們也可以輕而易舉地違背自己設置道德準則的初心。不論如何,這一嘗試代表了算法社會解決自身“囚徒“風險的另一種可能。
結語
在日益原子化的當代社會中,推薦算法可能是最懂你的人;然而過於親密的關係之下,推薦算法可能又會成為人加之於自己頭腦上的牢籠。不管是冷啓動、細化分類、興趣漂移等方面的諸多不便,還是趣味圈層化、內容低俗化以及選擇被動化的“原罪”,對推薦算法的警惕會伴着它愈加廣泛應用持續下去。如何擺脱算法的牢籠?社會層面的規制和技術層面的嘗試都在進行。個體層面上,消除歷史數據或許顯得無力,但是意識到推薦算法的囚徒風險,已經是邁出算法牢籠的第一步。
參考資料:
[1]雷鋒網.AI算法與道德規則如何平衡?IBM推出AI推薦技術
[2]深燃.年輕人開始“反推薦算法”:算法不講武德!
[3]雷鋒網.揭秘優酷認知實驗室
[4]王曉通.大數據背景下電影智能推送的“算法”實現及其潛在問題