每當我解僱一個語言學家,語音識別的性能就會上升 | 科技袁人_風聞
风云之声-风云之声官方账号-2021-09-20 07:29
導讀
2010年之前,華人出現在AI頂級會議優秀論文中的還寥寥可數。近年來,華人開始在AI國際機構擔任要職,優秀論文也開始湧現。例如在過去三年的ACL會議中,華人科學家拿到了兩年的最佳論文。
視頻鏈接:
西瓜視頻:
https://www.ixigua.com/7006207373845103111
本視頻發佈於2021年9月10****日,觀看量已達6萬
精彩再現:
我經常閲讀各個領域的外文信息,所以經常用到機器翻譯。可以説就在這幾年之內,我親眼目睹了機器翻譯的飛速進步,從一塌糊塗到像模像樣,現在已經相當不錯了。當然還是不時地有錯誤,但準確率之高、進步之快是更令人矚目的。
最近剛好有一個消息,字節跳動的人工智能實驗室在計算語言學會議(ACL) 2021上獲得了最佳論文獎。ACL是國際頂級的學術會議,而且最佳論文只有一篇,不是並列的,所以這個獎的分量是相當可觀的。這是一篇什麼樣的工作呢?借這個機會,我們就來講一下機器翻譯的原理。
其實我對人工智能是外行,但我的朋友、風雲學會會員陳經就是搞人工智能研發的。他講了很多深入的原理和有趣的故事。
“每當我解僱一個語言學家,語音識別的性能就會上升。”這句名言出自捷克和美國人工智能專家弗雷德裏克·傑利內克(Frederick Jelinek),是他在1988年説的。這其實反映了一場自動翻譯的革命。

弗雷德裏克·傑利內克
早期開發自動翻譯程序,非常依賴語言學家。就像最初開發圍棋程序的人,都是有一定水平的業餘棋手,例如我的前輩同行、理論與計算化學專業的陳志行(1931 - 2008)教授,他是電腦圍棋世界冠軍“手談”的作者。

陳志行
中國圍棋隊總教練俞斌九段説過,圍棋算法想要突破,一定需要棋力與算法水平都很高的團隊。現在大家知道,這種觀點是錯的。AlphaGo的團隊中並沒有圍棋高手,他們只請了一位樊麾二段來溝通圍棋知識。AlphaGo的成功來自算法的進步,機器翻譯也走過了類似的歷程。

俞斌
早期的自動翻譯程序,是把單詞與語法問題都用規則來概括,寫程序來實現。這是個自然的想法,因為我們學外語也要學單詞表和語法,也需要老師教。這些單詞表和規則,程序員搞不清楚,就需要語言學家來總結。
例如中文的“看”翻譯成英文,是look?還是watch?還是see?還是read?這需要看上下文。例如“看”後面跟的是“書”或者“文章”,就要用read。這類規律需要語言學家來歸納成有限的、可操作的規則,和程序員商量怎麼寫成計算機代碼。
還有更復雜的語序問題。中文和英文都是“主謂賓”結構,日語卻是“主賓謂”結構,動詞放在最後。電影中的日本鬼子經常説“什麼的幹活”、“花姑娘大大地有”,其實就是這麼來的!
由於人類語言太靈活,這種基於人工規則的翻譯經常得到可笑的結果。這到底是誰的鍋呢?語言學家説怪程序員沒有好好實現自己總結的語法規則,程序員卻説怪語言學家的規則體系自相矛盾,充滿例外,到處要打補丁。
到八十年代,搞算法的人想出了新辦法,於是他們終於可以愉快地“解僱語言學家”了。這個辦法就是統計學。更具體地説,是貝葉斯統計(Bayesian statistics)。不久前我剛好介紹過這個主題(貝葉斯統計:概率思維的魔法 | 袁嵐峯)。基本思想就是:不要規則了!換成統計概率!
比如説,我們要把“看”翻譯成英文,look / watch / see / read,語法規則會很繁瑣,要分析很多上下文,用規則“逼”出一個正確的答案。但現在,我們讓計算機把多種選擇都嘗試一下。比如I read a book / I watch a book / I watch a movie / I read a movie,這些都是候選的翻譯。然後根據句子在真實世界出現的概率,給這些翻譯打分,就會發現read book和watch movie分數很高,而read movie和watch book分數很低。不需要人為地加上read與book、watch與movie的關聯規則,都在統計裏了。
其實我們學母語就是這麼學的,並不是學規則,而是覺得大概率應該這麼説,不這麼説就怪了。我們學外語時經常説要培養“語感”,也是這個意思。
貝葉斯統計的核心,是計算條件概率,所以概率會隨着上下文條件發生變化。如果沒有任何信息,只有一個字“看”,翻譯成look的正確機會比read高。但是如果加上條件,“看這本書”,翻譯成read的正確概率就高了。
這套思想的精華,就是把規則變成概率。為了計算概率,需要海量的真實世界文本,數量越多,概率越準確。語言學家只需要貢獻翻譯樣本就行了,不需要折騰模糊的規則。
其實有大量“開源”的平行文本,如各國政府的條文多語言版本以及各種譯著與原文。羅塞塔石碑就是一個著名的平行文本,托馬斯·楊(Thomas Young,1773 - 1829)和商博良(Jean-François Champollion,1790 - 1832)根據希臘文與古埃及文字的對應破譯了古埃及文字。

羅塞塔石碑
(http://www.mingriqingbao.com/web/detail/forword/P/37382)
機器翻譯從基於專家規則的小眾系統,到能夠開放地放到網上公開測試使用,關鍵就是這個統計思想。在二十一世紀初,谷歌翻譯就有了基本的形式,讓人們知道了有“機翻”這回事。
然而,早期的機器翻譯還是毛病百出,像段譽的六脈神劍一樣時靈時不靈。這是為什麼呢?因為計算代碼是程序員人工寫的,經常碰到各種問題需要修改,改來改去顧此失彼。在這樣的框架下,無論代碼怎麼改進,樣本怎麼堆積,總是沒有本質性進步。

段譽的六脈神劍(動圖)
對技術感興趣的人知道,這一輪人工智能爆發的核心技術是“深度學習”(deep learning),它是從2013年開始獲得業界普遍承認的。深度學習的三位創始人傑弗裏·辛頓(Geoffrey Hinton)、楊立昆(Yann Le Cun)和約書亞·本吉奧(Yoshua Bengio),獲得了2018年的圖靈獎。
AlphaGo短短兩三年就遠遠超越了人類棋手,這就是深度學習的威力。同樣的,機器翻譯也發生了深度學習的革命,進入了新的境界。
巨大的突破來自對問題的重新定義,我們現在將翻譯問題抽象理解成一個序列到序列(sequence to sequence)的轉換問題。對一個序列,可以進行編碼(encode)。在通信傳輸、圖像壓縮等領域,編碼是很常見的思想。
你也許會問,文字已經用字母或者漢字這些符號來編碼了,還要怎麼編碼?這就是革命性的思想:人就別管了,管也管不好,這事交給神經網絡來幹!
就當有個黑盒子叫做“編碼器”,輸入是一串串的字符,輸出是一堆數字的編碼。然後再把那一堆數字編碼,輸入另一個叫“解碼器”的黑盒子,解碼器輸出的是有意義的文字序列。這頭編碼器把中文“編碼”成一堆數字,那頭解碼器把這堆數字“解碼”成有意義的英文,一次翻譯就完成了。
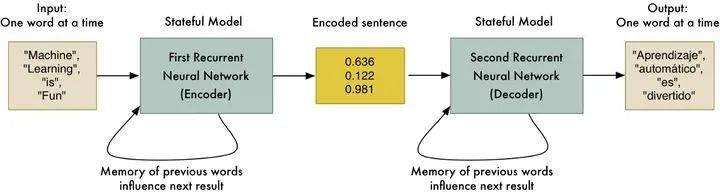
編碼器和解碼器
這個結構的好處在於,兩個黑盒子裏面具體怎麼編碼、解碼不用管,給足樣本,讓機器自己去深度學習。裏面乾的其實還是概率統計、減少誤差這些事,但邏輯不是程序員寫出來的,而是通過數據訓練出來的,它們是神經網絡的上千萬個係數。從語言學家定規則到深度學習自我訓練,基本的脈絡是逐漸排除人為影響,這就是電腦圍棋和機器翻譯飛躍進步的根本原因。
現在,我們終於可以來解釋字節跳動獲得最佳論文獎的工作了。它研究的是這樣一個問題:如何把句子劃分成一個個單元?也就是説,如何選擇最好的“詞表”(vocabulary)?
舉個例子,一個句子是:The most eager is Oregon which is enlisting 5000 drivers in the country(最積極的是俄勒岡,它在國內招募5000名司機)。我們需要首先把這句話劃分成若干個單元,每個單元對應一個編碼,然後把這串編碼輸入神經網絡。
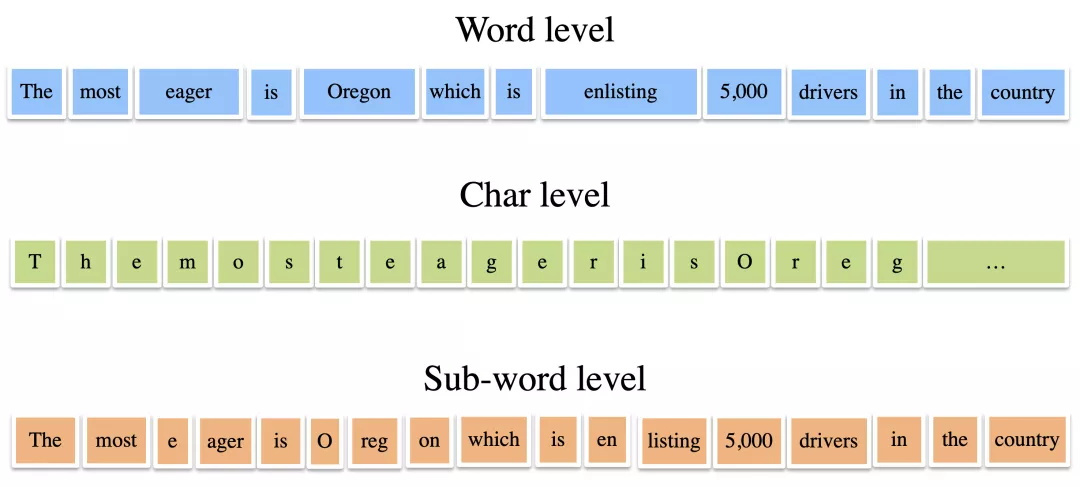
詞級別、字符級別、子詞級別的句子拆分
最容易想到的劃分,就是一個單詞一個單元,或者一個字母一個單元。但英文中一個詞往往是由若干個詞根組合成的,例如enlist = en + list。我們背單詞的時候不是死記硬背,而是通過這些詞根去理解。例如一看到enlist就能猜出它是“使列入名單”,所以是“招募”;一看到enlighten就能猜出它是“使發光”,所以是“啓發”。
因此真正高效的劃分方法,是用詞根來劃分,這些詞根的集合就是“詞表”。就像在生物學裏為了理解蛋白質結構,我們用氨基酸而不是原子作為基本單元。
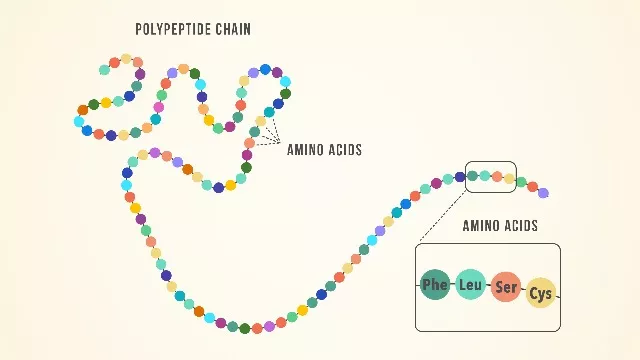
用氨基酸作為蛋白質結構的基本單元
這就帶來一個科學問題:詞表該取多大好呢?
很容易產生的想法,是詞表越大越好。但其實並不是這樣,因為每一種語言中常用的單詞都只佔少數。換句話説,每一種語言的單詞使用頻率都是長尾分佈。

長尾分佈
如果我們引入大量的低頻詞彙,收益就會越來越小,成本卻會越來越高,最終得不償失。因此,我們可以定義一個最優的詞表規模,即邊際收益剛好等於邊際成本時的詞表規模,這時總的收益是最大的。
這樣,字節跳動團隊把詞表問題轉化成了一個優化問題,然後用“最優運輸”(optimal transport)的思想提出了一種解決方案,用深度學習實現了這種方案。
最優運輸問題
這些方法的細節,大家可以去看他們的論文《神經機器翻譯中通過最優運輸的詞表學習》(Vocabulary Learning via Optimal Transport for Neural Machine Translation)(https://arxiv.org/abs/2012.15671)。下面我們來講三個宏觀的要點。

《神經機器翻譯中通過最優運輸的詞表學習》
第一個要點是,這種方法大大縮小了詞表,同時翻譯效果也不錯。
來看下面這個圖。字節跳動的軟件叫做VOLT,跟它對比的BPE-30K是目前業界最常用的設置,這個圖就是VOLT和BPE-30K對於英語和其他若干種語言互相翻譯的對比,黑體是表示哪一方勝出。最上面兩行是英語到其他語言的翻譯,中間兩行是其他語言到英語的翻譯,可以看到大部分是VOLT表現更佳,不過相差不大。最下面兩行是詞表的大小,這個差別就大了。例如對於英德翻譯,BPE-30K的詞表有33.6 K,而VOLT的詞表是11.6 K,只有前者的1/3。
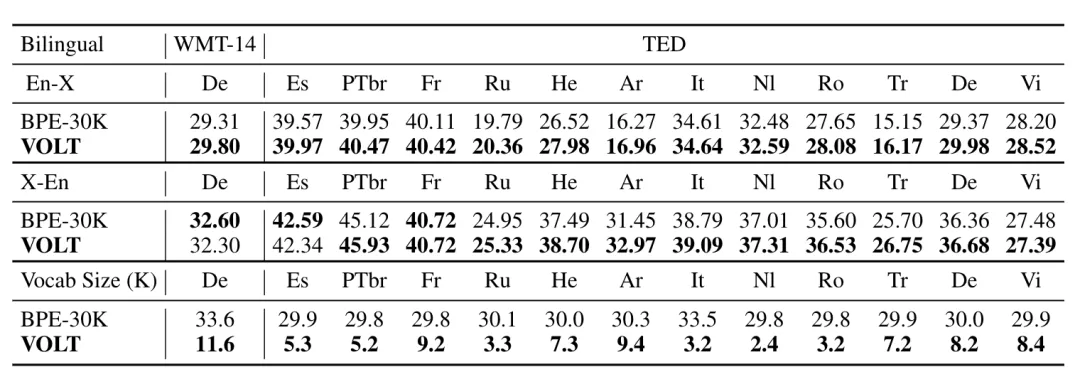
VOLT與BPE-30K的比較
詞表的節約,帶來能量的節約。同樣的搜索和評估工作,BPE需要運行384小時的GPU,而VOLT只需要半個小時的CPU加30小時的GPU,相當於少砍很多樹。在這個意義上,這是一個綠色環保的成果。
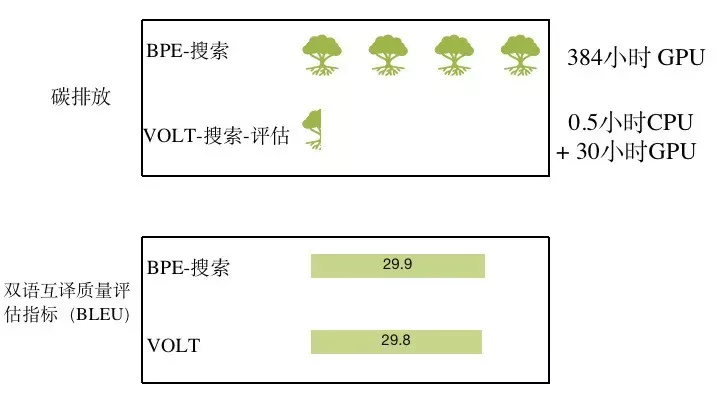
VOLT:綠色環保的詞表學習方案
第二個要點是,這是一個基礎原理層面的進步,而不是技術應用層面的進步。後者大家已經習以為常了。許多人甚至有這樣的印象:中國人只擅長改進技術,做不了基礎原理。我們可以明確地説,這種印象是錯的!
第三個要點是,人工智能發展的七十年,也是中國人工智能研究從空白走向繁榮的七十年。
2010年之前,華人出現在AI頂級會議優秀論文中的還寥寥可數。近年來,華人開始在AI國際機構擔任要職,優秀論文也開始湧現。例如在過去三年的ACL會議中,華人科學家拿到了兩年的最佳論文。
機器翻譯以及整個人工智能已經創造了很多奇蹟,但還有很長的路要走。我們相信,未來中國會做出更多基礎性、革命性的貢獻。