AI產業新階段:高效的數據管理,正在實現AI數據價值最大化_風聞
智能相对论-智能和车,边评边测;未来和家,且品且鉴2021-09-28 19:27

文|智能相對論
作者|葉遠風
AI算法工程師像普通用户在搜索引擎上搜索信息一樣,將數據標註結果的標籤(例如,車輛、樹木)輸入到互動窗口,所有與之有關的AI數據“元信息”就被篩選出來,隨後,工程師用新的方式將這些數據重新“打包”構建起一個新的場景庫,導入到AI模型的訓練過程當中,一次針對特定場景的迭代訓練就這樣開始了。
如果工程師需要,還可以根據最初採集數據的傳感器,或諸多其他區分數據的屬性來精確定位數據。
這是某自動駕駛AI開發企業裏的一次專注於特定場景AI模型訓練的工作日常,看起來再正常不過,而在這之前,這家企業長期面臨在龐大冗雜的訓練數據庫裏難以篩選有價值數據進行特定場景模型訓練的尷尬問題,“守着金山挖不動”。
問題的解決,是從採用了專門針對“AI數據集”的管理系統開始的——這個AI企業工作切面的背後,反映的是AI“產業鏈條”上值得關注的變化。
AI場景化落地正隨着數字經濟的全面滲透而進入提速階段,算法、算力和數據共同構成技術發展的三大核心要素,打通這三大環節才能讓一個個AI應用真正落地到具體場景裏產生價值。由此,在走向最終的產業應用之前,“生產”AI應用的“產業鏈條”上也藴含了無數的商業機會。
但是,在數據層面,過去多數人最關心的只有餵養AI模型的“量”夠不夠用、數據的“質”夠不夠精準,而現在,數據這個AI“產業鏈條”的重要環節還在進一步細化,專業的AI數據集管理——Al數據集的上傳、管理、存儲、分享,正展示出推動高質量AI應用落地的價值,例如不久前的2021服貿會上,原本以高質量AI訓練數據服務見長於業內的雲測數據,就在其雲測數據標註平台基礎上發佈了AI數據集管理系統,要為企業提供專業的AI數據集管理服務。
而這個賽道上不只有云測數據,多種主體參與的產業現象正在這裏形成,也帶來當下人工智能領域重要的創新機遇。
按下葫蘆浮起瓢,AI數據集管理挑戰顯現
誠然,隨着算法模型、技術理論和應用場景的不斷突破,加之“新基建”浪潮下算力基礎設施的快速建設,AI產業對數據“量”的需求在不斷增長,數據量“短缺”一度成為AI產業鏈條上的瓶頸問題。
但是,這可能並不會持續很長時間,嗅到機會的科技巨頭、創新企業前些年在數據採集與標註上廣泛佈局,推動合格數據的“量”快速增長,這也使得數據標註行業作為AI上游基礎產業在短短數年間實現了爆發式發展。
有數據顯示,2019年、2020年,數據標註行業市場規模為30.9億元、36億元左右,年均複合增長率20%左右,預計到2025年,國內數據標註市場規模將突破100億元大關。
這背後,根據AI數據標註猿統計數據,2020年4月,國內數據標註業務相關公司數量為565家,2020年12月,數量增長至705家,2020年4月份到12月份的相關數據標註需求公司增量為24.78%,約20萬全職從業者與約100萬兼職從業者,正在讓AI產業走出數據荒。
當然,AI數據也不僅僅來源於數據標註,互聯網科技的快速發展也在助推中國數據“供給量”的總體提升,在IDC的報告中,中國的數據量增速比全球快3%,預計到2025年將增至48.6ZB,佔全球總量的27.8%,年複合增長率達30.35%。
但是,量的問題一定程度上解決後,新的問題又冒了出來——如何更高效地利用數據,發揮數據的價值。其重要背景,是AI應用的開發方式發生了從項目制到敏捷開發的重要轉變:
過去AI模型訓練以一個個項目為主,做完項目、得出一個預期質量的AI模型後,使用過的數據便被“丟棄”;而現在,企業傾向於持續把過去已有的數據利用起來,逐步形成屬於企業的數據池子,將數據在多個相關模型開發中進行重複利用。
這就導致單個企業所積累的數據量越來越多,而眾所周知數據量的增長又以非結構化數據為主,企業所面臨的AI數據集管理的挑戰越來越明顯,例如,數據量太大,針對特殊的場景缺乏精準的方式去找到有價值的數據;原本數據管理凌亂,本地服務器存一點、雲端有一點,版本更新不同步,甚至出現一個Excel表格管理數據的現象;數據隨意拷貝、傳輸,存在重大的資產損失風險等等。
顯而易見,這時候,能夠幫助企業管理好AI數據,就成了重要的創新機遇。
到目前為止,有三類不同背景的玩家在加入賽道:
一是原本就向企業提供數據採集與標註服務的廠商,例如開篇提到的雲測數據,這類企業入局,是AI“產業鏈條”自然延伸的結果。
從行業地位看,在《互聯網週刊》&eNet研究院、德本諮詢聯合發佈的《2021數據標註公司排行》中,雲測數據憑藉最高99.99%精準度數據標註能力和場景化訓練數據方案等,再次排在“數據標註公司排行”榜首位置,其雲測數據標註平台4.0能夠實現AI數據訓練綜合效率提升200%。
但是,越是如此,雲測數據這樣的平台就越繞不過企業AI數據管理的問題——如果只是提供數據、幫助訓練效率提升,而不推動企業“搞定”數據管理,隨着企業面臨數據管理的挑戰,其商業模式越往下走就越會越到障礙,這時候,就只能在已有的技術和服務經驗積累的基礎之上拓展AI產業鏈條細化環節,推出專門的針對AI數據集管理的技術系統——也順勢成為國內首個該領域的系統。
可以説,雲測數據推出AI數據集管理系統,既是基於人工智能行業前瞻性發展的具象化技術產品體現,為企業尋找新的發展空間,也是AI產業鏈條閉環的一種倒逼。
其優勢在於,作為原來的AI訓練數據服務商,藉助AI數據集管理系統,可以以“全生命週期關注”的姿態走進需求企業,推動企業從最開始的數據獲取到最終的產業落地全週期效率提升,幫助客户企業整體化思考,也契合AI發展告別項目制走向敏捷開發的趨勢。而作為原本AI訓練數據服務領域的領導者,雲測數據的智能駕駛、智慧城市、智能家居、智慧金融、新零售等眾多垂直領域的數據服務技術與經驗可以很好地橫移到AI數據集管理當中,在數據檢索、數據呈現、數據安全保障等方面有垂直化的經驗壁壘。
二是互聯網、科技領域的大廠,它們都具備雲計算方面的數據管理基礎稟賦,其入局,是從數據管理大賽道延展到AI數據集管理小賽道的客觀結果。
較為典型的是IBM,面向中國市場提供混合數據管理系統,“利用數據管理驅動AI”是官方宣稱的重要價值之一,例如其IBM Cloud Pak for Data,產品功能是幫助企業收集、組織和分析數據,“以實現有影響力的AI”,而其實現主要包括在容器化的環境中運行IBM Db2 Warehouse等——不需要知道這是什麼,只要知道這些原本就用於雲計算數據管理即可。
其他如從事數據標註的百度、阿里等,其雲計算中都或多或少包含AI數據集管理的能力,只不過並非專門的系統,這類企業的優勢在於,原本的數據管理往往會積累一定的基礎客户量,在品牌上也有大廠背書。
三是“白手起家”,直接切入賽道的創新企業,這類企業以尋找商業機會為直接目標。
例如來自上海的格物鈦,主要提供面向機器學習的數據管理SaaS產品,支持企業進行海量數據託管,宣稱要提供“人工智能基礎設施”,該企業目前得到了紅杉、雲啓、真格以及風和資本的千萬美金Pre-A輪融資,這從側面反映了AI數據集管理的價值潛力。
這類企業的優勢在於輕裝上陣,在資本的青睞和支撐下似乎可以把產品做得更精細化,當然,它們的出現,也意味着後續將有更多過去與AI數據集沒有“淵源”的創新企業加入,這個賽道會越來越熱鬧。
標準化的四個維度,AI數據集管理挖掘AI產業鏈細化環節的創新價值
從具體做法來看,不管什麼來路,做AI數據集管理,無非都包括標準化的四個維度,只不過實現方式各不相同。
首先,是便捷的數據檢索和利用。
量大且非標準化,池子還在不斷擴大,於是方便的檢索和利用就成為AI數據集管理的核心任務。
這方面,IBM使用了開放式平台上的自動容器化功能,通過架構優勢來讓數據收集和管理變得更加簡單智能,易於訪問;而云測數據等企業都採用的是清晰化的標籤與屬性體系讓工程師可以快速找到想要的數據。
值得一提的是,雲測數據的AI數據集管理系統還適配了多數的公開、開源數據集格式,這使得企業無論是從外部獲得數據(這種情況十分普遍)還是自己花錢採集與標註得到的數據,都能得到統一的管理。
此外,數據的“可讀性”也是衡量AI數據集管理系統能力的關鍵指標,在數據篩選出來後還能將數據還原,能有效幫助AI開發過程實現精細化(圖:雲測數據-AI數據集管理系統數據可視化界面):
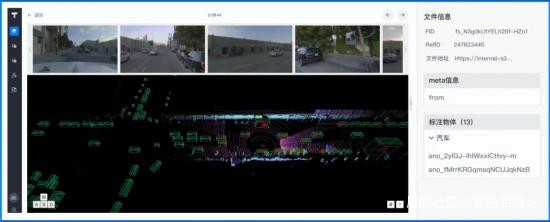
一方面,這類可視化功能可以幫助AI開發工程師直接查看數據最開始的狀況,更容易理解數據;另一方面,如果工程師有新的數據需求,也可以通過可視化的方式進行精確化的數據調校。
然後,是日常管理和使用的便捷性、安全性。
本質上,AI數據集管理是企業AI開發工作流程在信息化方面的一種體現,作為重要的工作對象和企業資產,企業層面的流程規範必須在AI數據集管理系統中得到遵守。
所以,可以看到,格物鈦在系統中做到了數據的查看、編輯、使用和管理權限分離,來保障數據的訪問安全;而云測數據則強調多團隊協作與數據資產化管理同步進行,提供多團隊數據使用權限分配、存儲空間限定、使用日誌記錄等功能,企業可以根據實際需要靈活配置權限,這種做法能保證數據版本、工作協同的效率,且“數據失竊”、“刪庫跑路”等資產損失事件將最大程度規避。
再有,是對企業自主擴展的支持。
一般而言,AI數據集管理都是與企業AI開發全流程緊密融合的,企業往往要將這套系統進行擴展以更好地滿足上下游業務需求,而由於不同行業、企業的情況各不相同,服務廠商不太可能提供一個能夠支持所有企業都將AI數據集管理系統與企業上下游業務實際相融合的標品方案。
這時候,將系統做得很有擴展性,儘可能基礎化、通用化,並支持企業自主開發擴展就變得很重要,可以看到,雲測數據提供了有Python SDK、CLI和API等開發工具,讓企業可以根據業務需要,持續集成數據輸入、輸出訓練、數據迭代等業務場景。
最後,是部署成本的節約。
這是很多企業選擇AI數據集管理系統的重要決策依據。
由於公有云、私有云的發展,這方面的邏輯已經變得比較簡單,越是彈性化、包容性強的方案,越可能實現恰當的成本支出,典型如雲測數據就十分強調其“靈活易擴展的混合存儲支持”的特性,支持根據數據安全級別、使用頻率、使用方式等對數據集分級管理,讓企業可以“在安全和經濟上靈活選擇”。
總體而言,AI數據集管理系統需要照顧的企業需求已經固定,剩下的是入局的玩家如何根據自身優勢各顯神通、挖掘更深度的商業價值了。
結語
服貿會上,雲測數據在推出其AI數據集管理系統時,特地強調了“採、標、管、存一站式服務”,回過頭來看,這固然是個體廠商在強調自身的獨特優勢,但從行業角度而言,也某種程度上説明了AI數據集管理的最根本意義是讓AI在最終落地前形成標準化的產業鏈條,所謂AI應用的“工業化大生產”能夠從最初的“原料”到最後的“成品”實現全鏈條打通,而這,通常是一個行業走向成熟的重要標誌。
一旦“產業鏈條”走向完善,AI訓練數據將不只有在採集標註時精確度提升,其價值也將得到充分挖掘。總體來看,AI應用開發的質量、效率都將得到提升,而最終成本將會下降,所謂的“提質、增效、降本”三位一體的企業理想或也將最終得以實現。
*本文圖片均來源於網絡
深挖智能這口井,同好添加vx:zenghy2017
此內容為【智能相對論】原創,
僅代表個人觀點,未經授權,任何人不得以任何方式使用,包括轉載、摘編、複製或建立鏡像。
部分圖片來自網絡,且未核實版權歸屬,不作為商業用途,如有侵犯,請作者與我們聯繫。
智能相對論(微信ID:aixdlun):
•AI產業新媒體;
•今日頭條青雲計劃獲獎者TOP10;
•澎湃新聞科技榜單月度top5;
•文章長期“霸佔”鈦媒體熱門文章排行榜TOP10;
•著有《人工智能 十萬個為什麼》
•【重點關注領域】智能家電(含白電、黑電、智能手機、無人機等AIoT設備)、智能駕駛、AI+醫療、機器人、物聯網、AI+金融、AI+教育、AR/VR、雲計算、開發者以及背後的芯片、算法等。