2457億參數!全球最大AI巨量模型「源1.0」發佈,中國做出了自己的GPT-3_風聞
西方朔-2021-09-29 18:45
原創 新智元 新智元 今天
新智元報道
編輯:好睏 yaxin
**【新智元導讀】**古代文人,或一觴一詠,暢敍幽情,或風乎舞雩,詠而歸。「吟詩作對」成為他們的標配。剛剛,全球最大人工智能巨量模型「源1.0」發佈,能賦詩作詞,比人類還像人類。
理科生文藝起來,可能真沒文科生什麼事兒了。

不信?你看看這首七言詩:
雖非蟾宮謫降仙,何懼冰殿冷徹骨。
窺簾斜視金屋小,多少俊才在此關。
讀完之後,不得不説真牛啤!意境內涵都很贊。
不僅能寫詩,還能做詞,比如下面這首:
疑是九天有淚,
為我偷灑。
滴進西湖水裏,
沾濕一千里外的月光,
化為我夢裏的雲彩。
你能想象,這是完全不懂寫詩的理工生的傑作嗎?
確實如此。簡直讓李白看了會沉默,讓杜甫看了會流淚。

這就是浪潮剛剛發佈的全球最大規模人工智能巨量模型,名曰「源1.0」。
除了能夠作詩賦詞,它還能對話、寫對聯、生成新聞、故事續寫…
2457億參數,這個全球最大規模人工智能巨量模型可是讀了2000億詞。
要知道,一個人的一生也沒有辦法讀完這麼多詞語。
既然稱為全球最大,有多大?
全球最大規模人工智能巨量模型!
全球最大這個稱號可不是鬧着玩的!
「源1.0」不管是在算法、數據還是算力上,都做到了超大規模和巨量化。
算法方面,相比於1750億參數的英文語言模型GTP-3,「源1.0」共包含了2457億個參數,是前者參數量的1.404倍。
而且,最重要的是,「源1.0」和GPT-3一樣都是單體模型,而不是由很多小模型堆砌起來的。就單單在這一個方面,「源1.0」就可以榮登全球最大的自然語言理解模型了。
圖源:writeup.ai
數據方面,「源1.0」幾乎是把近5年整個中文互聯網的浩瀚內容全部「讀」完了。通過自研的文本分類模型,獲得了5TB高質量中文數據集,在訓練數據集規模上領先近10倍。
此外,「源1.0」還閲讀了大約2000個億詞。這是什麼概念呢?
假如人一個月能讀十本書,一年讀一百本書,讀50年,一生也就讀5000本書,一本書假如20萬字,加起來也只有10億字,需要一萬年才能讀完2000億詞。在如此大規模的數據加持下,「源1.0」的數據集也自然成為了全球最大的高質量中文數據集。
算力方面,「源1.0」共消耗約4095PD(PetaFlop/s-day)。相對於GPT-3消耗3640PD計算量得到1750億參數,計算效率大幅提升。如果説,讓「源1.0」一天24小時不間斷「閲讀」的話,只需要16天就可以看完近五年中文互聯網的幾乎全部內容。
嗯?原來已經把近5年的中文互聯網內容全學完了?
u1s1,「源1.0」yyds!

成果如何呢?
你猜,這些對話中,每個問題對應的A和B中,哪個是「源1.0」生成的呢?(答案在文末)
對話
A
B
問題1
姐姐啥時候回來捏?
過年前幾天吧。
姐姐啥時候回來捏?
不知道,你要是想姐姐,就給姐姐寫信。
問題2
和喜歡的男生告白了他現在還沒回我
和喜歡的女生表白了她説我們只適合做朋友
和喜歡的男生告白了他現在還沒回我
我想知道結局
問題3
我買了那套章蜜糖的針織裙
哪套?有鏈接不?
我買了那套章蜜糖的針織裙
穿了嗎?好看不好看?
問題4
不吃東西真的好難啊
覺得今天如果真的吃的話,明天鐵定會變胖的
不吃東西真的好難啊
我也覺得!我一定要瘦
親自體驗「圖靈測試」是不是很好玩?別急,後面還有很多題等着呢!
現在我們先來看看「源1.0」最厲害的模仿能力。也就是,對於一個完全不存在的「詞語」,只需要一個用例,「源1.0」就能學會這個「詞語」的用法。
新詞
輸入-語義
生成文本
懸命
「懸命」是拼命,接近全力,做出最大努力的意思。他凡事必懸命,絕不打馬虎眼。用「懸命」造句:
他這個人做事太懸命了,為了取得第一手材料,連飯也顧不上吃
腕前
「腕前」與本領的意思相同。例:「他只使出了了一小部分腕前,就把事情完成得如此出色」。用「腕前」造句:
這個人的腕前很大,他很能完成這項任務
氣持
「氣持」是心情、精神狀態的意思。例:「那種消極的氣持又控制了他」。用「氣持」寫一句話:
他的氣持,使我無法接近
看到這些熟悉的「詞」是不是感覺有那味了(doge)。突然有些期待,如果「源1.0」學會了「小丑竟是我自己」這個詞會怎麼用,誒嘿嘿。

既然提到了圖靈測試,那我們就來看看測試的結果怎麼説?
「源1.0」在測試中實現了高達50.84%的平均誤判率!
圖靈測試採用「問」與「答」模式,即觀察者通過控制打字機向兩個測試對象通話,其中一個是人,另一個是機器。觀察者不斷提出各種問題,從而辨別回答者是人還是機器。
通常認為,進行多次測試後,如果機器讓平均每個參與者做出超過30%的誤判,那麼這台機器就通過了測試,並被認為具有人類智能。
在「源1.0」的測試結果中,受訪者的平均區分正確率是49.16%,這意味着平均誤判率為50.84%。在新聞生成這一領域,誤判率更是高達57.88%。
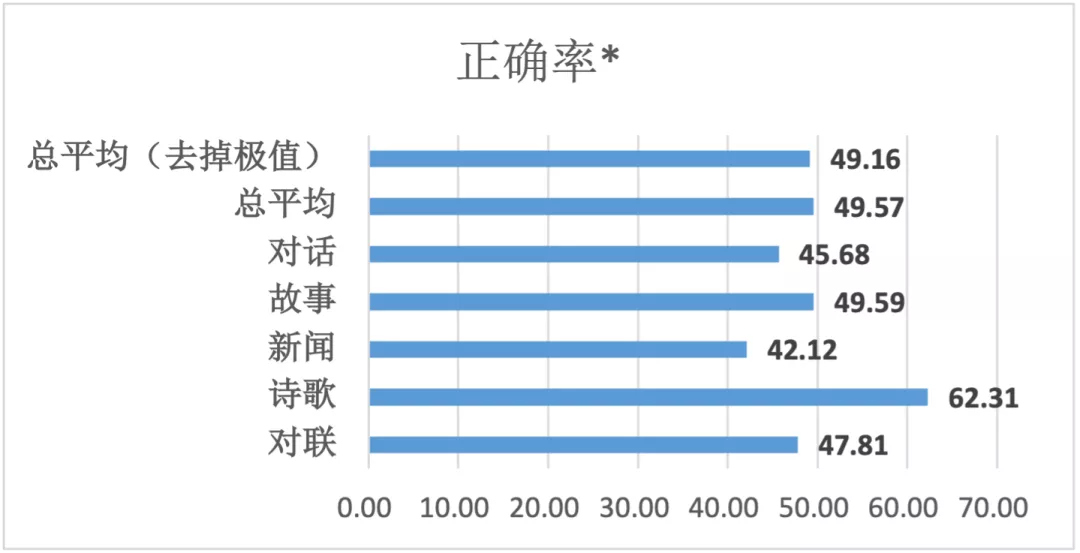
其中,正確率是指能正確將機器生成的文本識別出來的比例。正確率<70%,意味誤判率超過30%。
數據看着太單調?沒事!大家期待的「真題」環節來了!
對聯
上聯
A
B
問題1
五湖四海皆春色
三江八荒任我遊
萬水千山盡得輝
問題2
春來人入畫
福至夢開花
夜半月當燈
問題3
和風吹綠柳
時雨潤春苗
細雨潤青禾
問題4
三江顧客盈門至
四季財源滾滾來
百貨稱心滿街春
詩歌
A
B
問題1
滿目青山夕照明,願隨江舟泛輕風。
今生常憶多情事,香閨如夢領神會。
塞上長城萬里長,漫天風雪映重巒.
一邊江水人心去,滿目青山絕照還。
問題2
燕壘空梁畫壁寒,諸天花雨散幽關,篆香清梵有無間。
蝶夢似曾留錦袖,絳河如又濕團扇,風來香去苦欄干。
問題3
夜戰桑乾北,秦兵半不歸。
朝來有鄉信,猶自寄寒衣。
戰鼓催徵千嶂寒,陰陽交會九皋盤。
飛軍萬里浮雲外,鐵騎叢中明月邊。
答案在文末哦~
世界第一是怎樣一種體驗?
那麼,這個拿下世界第一的最大AI模型,到底有多強?
不如拉出來跑個分、刷個榜看看!
英文語言模型評測有GLUE、SuperGLUE,例如GPT-3這類的各種預訓練模型都會在上面進行評估。和GLUE類似,CLUE是中文第一個大規模的語言評估基準。其中包了括代表性的數據集、基準(預訓練)模型、語料庫和排行榜。而這些數據集也會覆蓋不同的任務、數據量、任務難度等。

順便安利一下最近新出的國內首個以數據為中心的AI測評DataCLUE。
言歸正傳,「源1.0」佔據了零樣本學習(zero-shot)和小樣本學習(few-shot)2項榜單的榜首。
在ZeroCLUE零樣本學習榜單中,「源1.0」以超越業界最佳成績18.3%的絕對優勢遙遙領先。其中,在文獻分類、新聞分類,商品分類、原生中文推理、成語閲讀理解填空、名詞代詞關係6項任務中獲得冠軍。
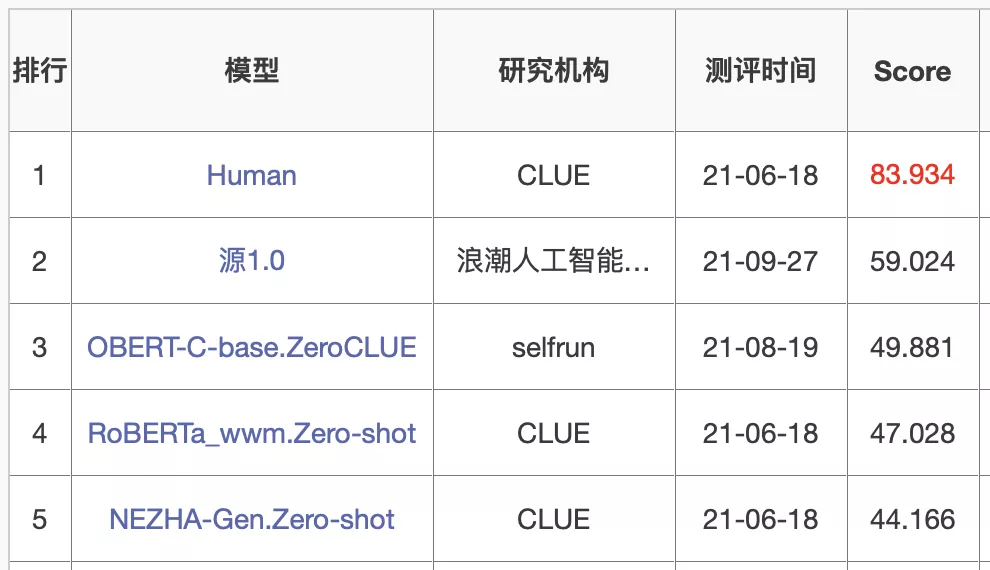
https://www.cluebenchmarks.com/zeroclue.html
在FewCLUE小樣本學習榜單中,「源1.0」獲得了文獻分類、商品分類、文獻摘要識別、名詞代詞關係等4項任務的冠軍。
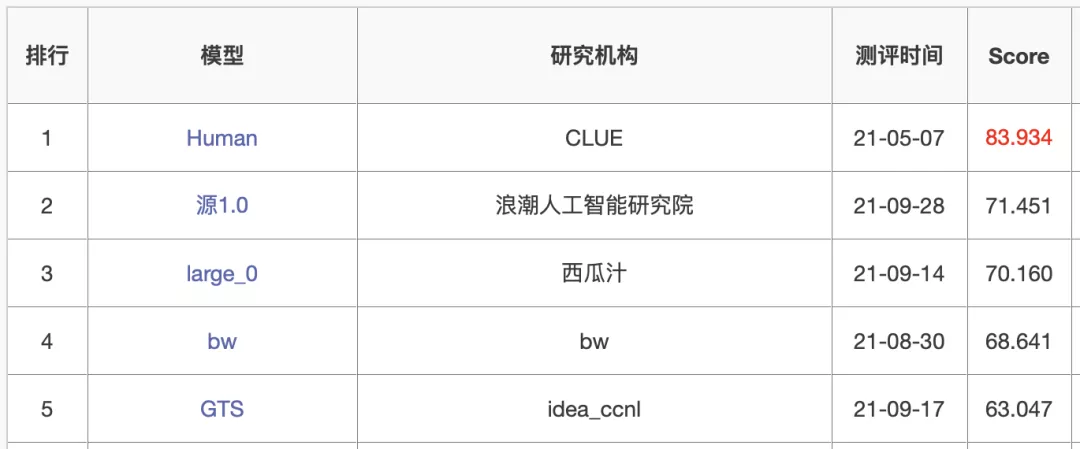
https://www.cluebenchmarks.com/fewclue.html
零樣本學習,就是訓練的分類器不僅僅能夠識別出訓練集中已有的數據類別,還可以對於來自未見過的類別的數據進行區分。從原理上來説,是讓計算機具備人類的推理和知識遷移能力,無需任何訓練數據就能夠識別出一個從未見過的新事物。
小樣本學習,就是使用遠小於深度學習所需要的數據樣本量,達到接近甚至超越大數據深度學習的效果。而是否擁有從少量樣本中學習和概括的能力,是將人工智能和人類智能進行區分的明顯分界點。因為人類可以僅通過一個或幾個示例就可以輕鬆地建立對新事物的認知,而機器學習算法通常需要成千上萬個有監督樣本來保證其泛化能力。
圖源:Akira AI
説了半天,「源1.0」的小樣本學習和零樣本學習這麼厲害有啥用呢?
這就要提到巨量模型的一個非常重要的意義了:強大的統一泛化能力。
對於大部分規模比較小的模型來説,需要針對每一個新的任務重新做微調,給它喂相應的數據集,在做了大量的工作之後才能在新場景下應用。而對於巨量模型,在面臨不同應用任務的時候,則不需要做大量的重新訓練和重新調整。
浪潮人工智能研究院首席研究員吳韶華表示:「你不用喂巨量模型那麼多數據去做訓練,就可以在一個新的應用場景裏面得到非常好的結果。」
所以説巨量模型的適應能力非常強,可以極大地減少產業界在應用模型的時候,不管是在數據還是在微調方面的投入,從而加快產業的發展進程。
如何評價?
大模型正在成為AI發展趨勢,是必爭的高地。
時間要倒回三年前… 當時的預訓練模型,讓深度神經網絡,以及大規模無標註數據的自監督能力成功激活。
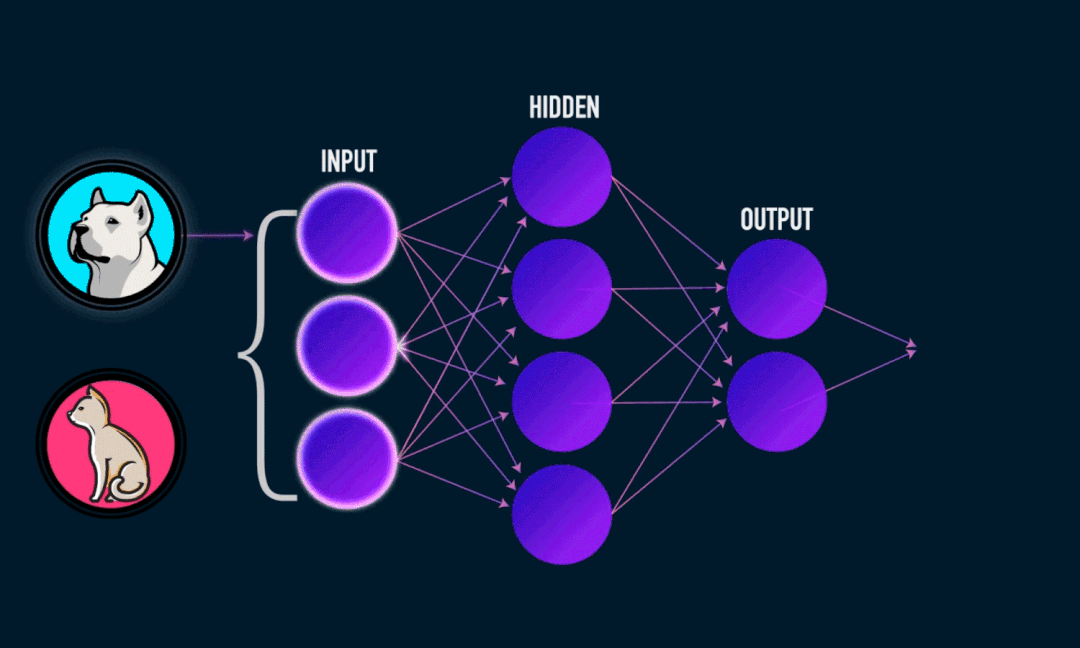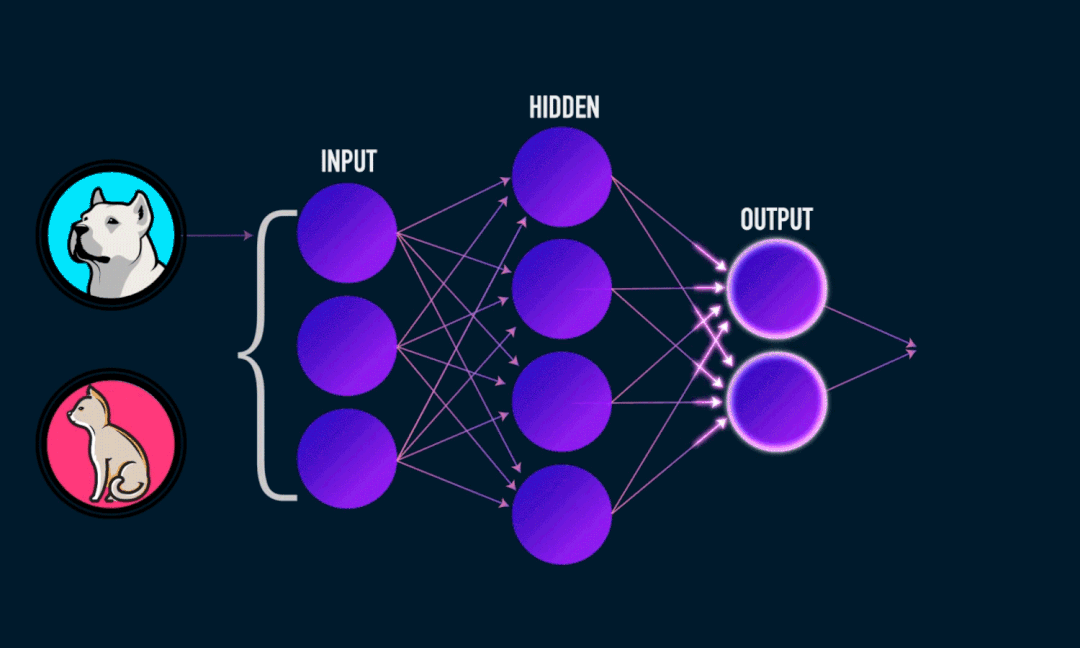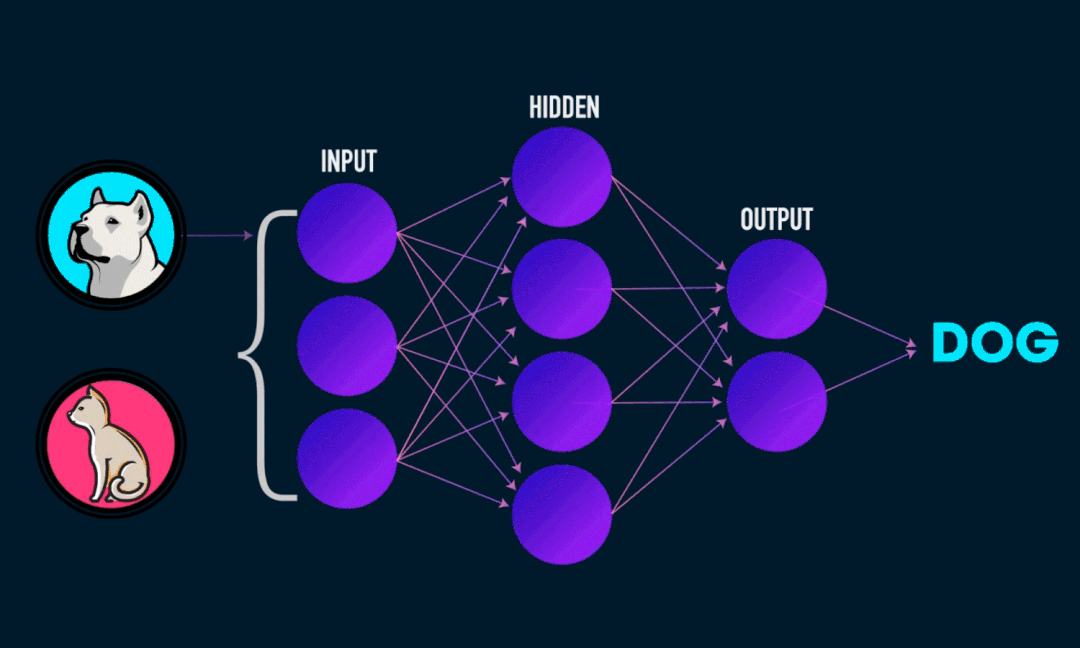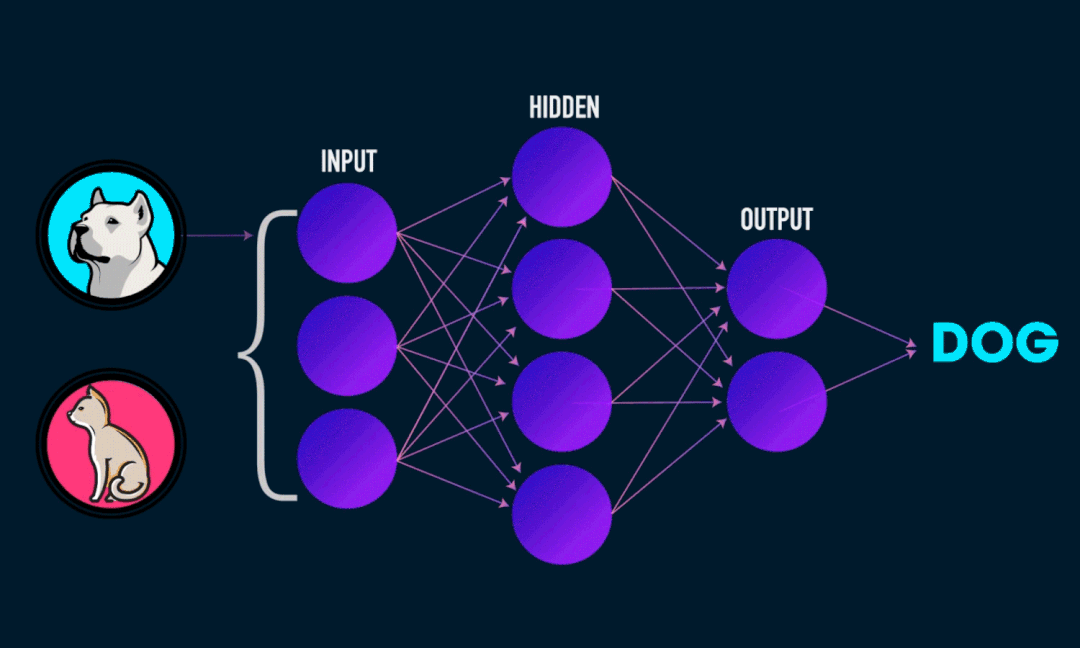
深度學習模型和性能這一開關同時被打開,尤其是NLP領域。
Big Tech 在嚐到與訓練模型帶來甜頭之後,紛紛對模型規模和性能展開了激烈的競爭。
從驚豔四座的谷歌BERT,到OpenAI的GPT-3,參數量不斷刷新,1750億參數,其能力也是不言而喻。
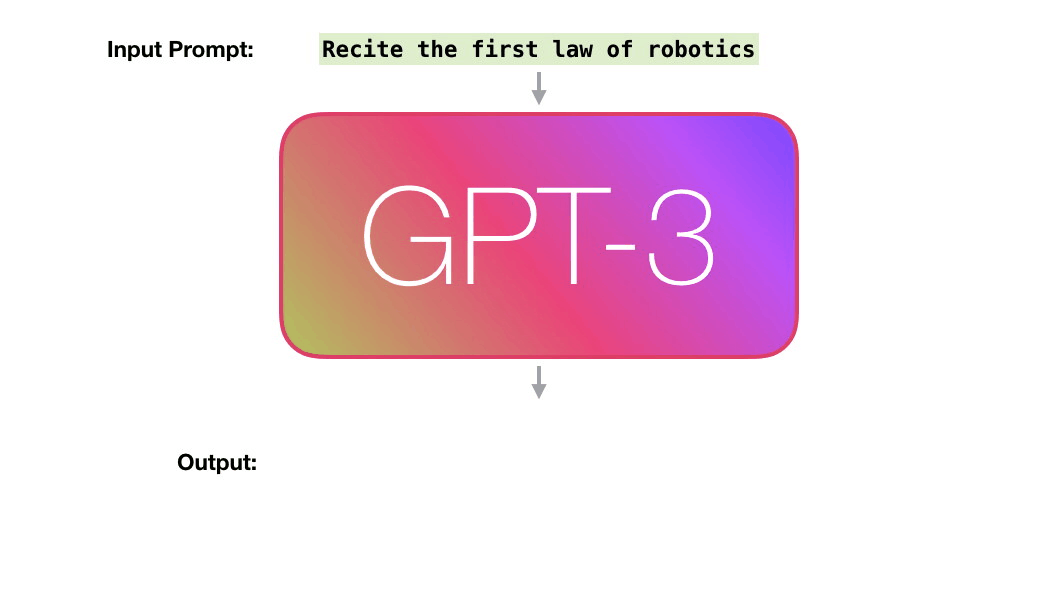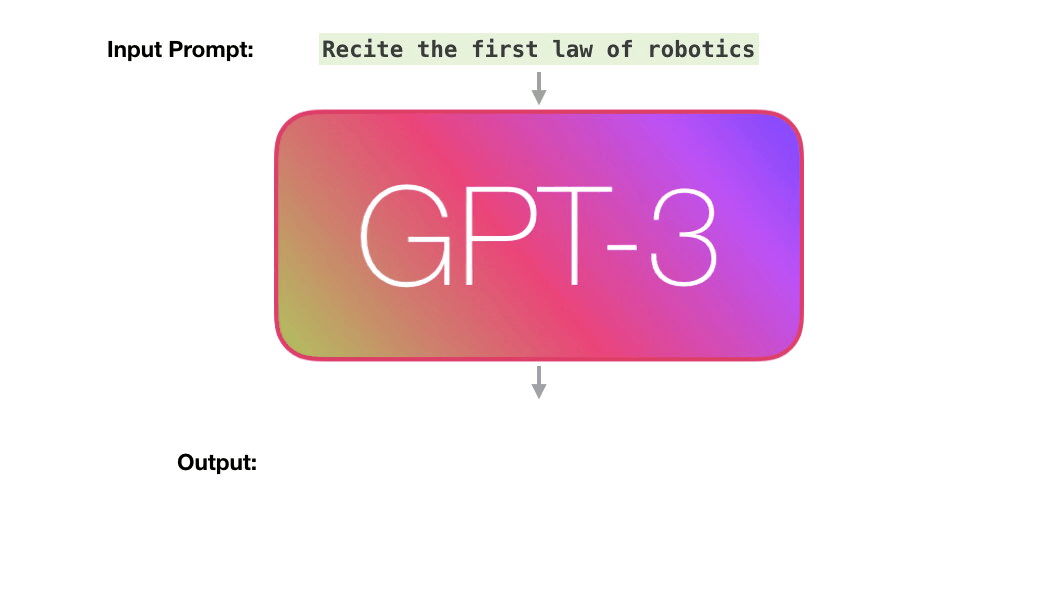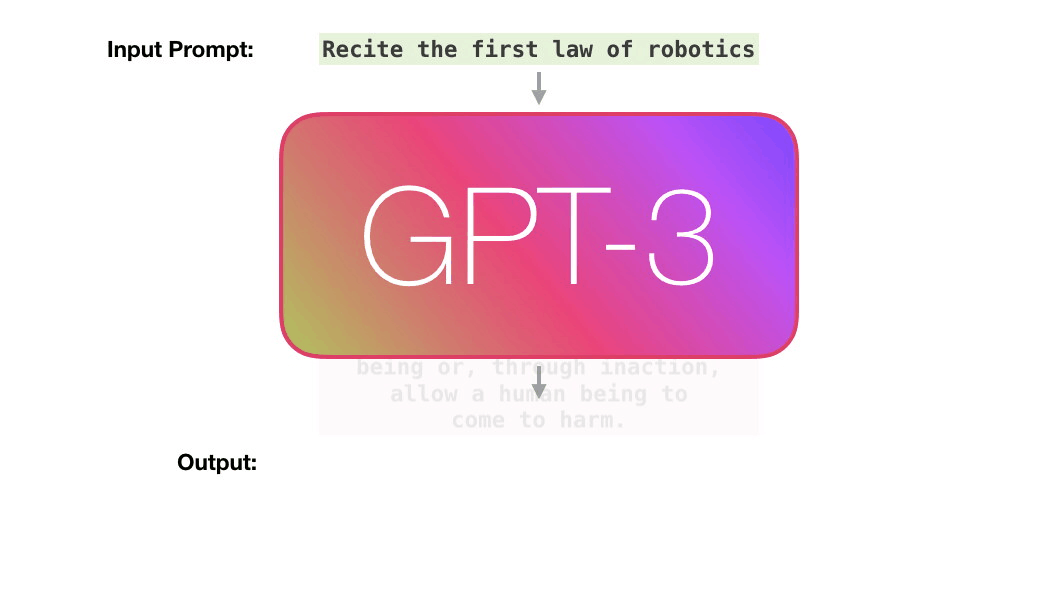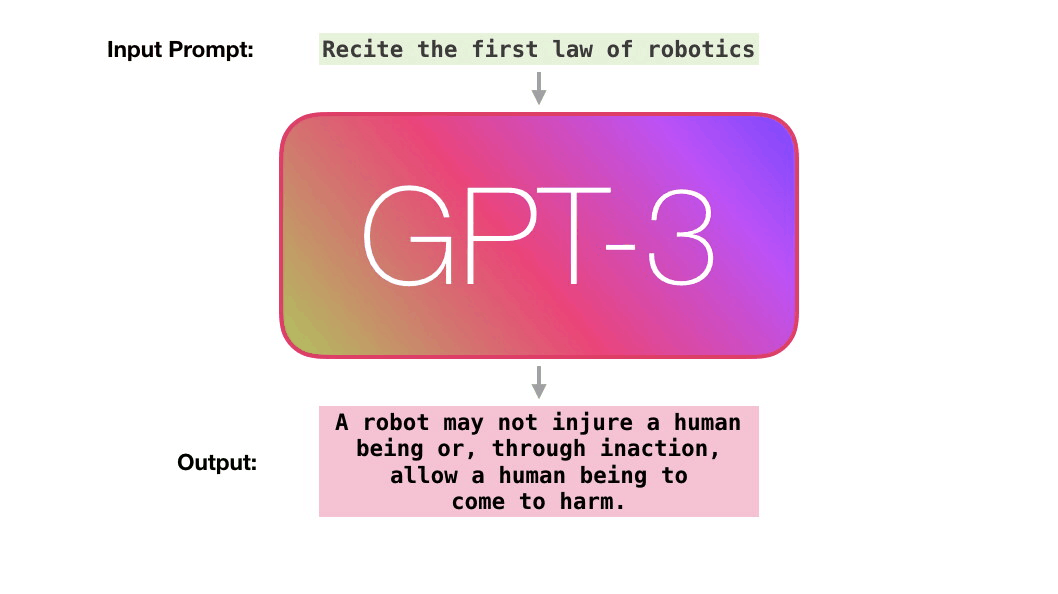
當前,語言模型的訓練已經從「大煉模型」走向「煉大模型」的階段,巨量模型也成為業界關注的焦點。
近日,李飛飛等斯坦福研究者在論文中闡述了類巨量模型的意義在於突現和均質。在論文中,他們給這種大模型取了一個名字,叫基礎模型(foundation model),並系統探討了基礎模型的機遇與風險。
https://arxiv.org/pdf/2108.07258.pdf
簡單説,大模型就是我們理解生命的進化,從簡單到複雜的這樣一個過程。
我們把模型比作是元宇宙裏面的生命,它擁有多大模型的這種複雜綜合系統的能力,可能就決定了未來在數字世界和智能世界裏,它的智能水平到一個什麼樣的程度。
今天,「源1.0」有2457億參數還不夠多,人類的神經元突觸超過100萬億,所以依然有很長的路要走。
而「源1.0」創新點在哪?通過協同優化,「源1.0」攻克了在巨量數據和超大規模分佈式訓練的擴展性、計算效率、巨量模型算法及精度提升等方面的業界難題。
算法上:
解決了巨量模型訓練不穩定的業界難題,提出了穩定訓練巨量模型的算法;
提出了巨量模型新的推理方法,提升模型的泛化能力,讓一個模型可以應用於更多的場景。
數據上:
創新地提出了中文數據集的生成方法,通過全新的文本分類模型,可以有效過濾垃圾文本,並生成高質量中文數據集。
算力上:
「源1.0」通過算法與算力協同優化,使模型更利於GPU性能發揮,極大的提升了計算效率,並實現業界第一訓練性能的同時實現業界領先的精度。

圖源:跨象乘雲
那麼,開發者們能從這塊「黑土地」上得到什麼?
浪潮源1.0大模型只是一個開始,它只是提供一片廣闊的肥沃土壤。
浪潮未來將定向開放大模型API,服務於元腦生態社區內所有開發者,供全球的開發人員在平台上開發應用於各行各業的應用程序。
各種應用程序可以通過浪潮提供的 API進行基於大模型的搜索、對話、文本完成和其他高級 AI 功能。
其實,不管是1750億參數,還是2457億巨量參數語言模型,最重要的是它能否真正為我們所用。要説上陣,真正的含義並不是在發佈會上的首秀,而是下場去在實際場景中發揮它的作用和價值。
浪潮信息副總裁劉軍表示,「首先從大模型誕生本身來説,還有另外一個意義,那便是對於前沿技術的探索,需要有大模型這麼一個平台,在這個平台上才能支撐更進一步的創新。」
「其次,在產業界我們很多產業代表提出來的殺手級的應用場景,比如説運營商智能運維,在智能辦公場景報告的自動生成,自動對話智能助手。」
「源1.0」大模型能夠從自然語言中「識別主題並生成摘要」的能力,讓各行各業公司的產品、客户體驗和營銷團隊更好地瞭解客户的需求。
例如,未來大模型從調查、服務枱票證、實時聊天日誌、評論等中識別主題、情緒,然後從這個彙總的反饋中提取見解,並在幾秒鐘內提供摘要。
如果被問到「什麼讓我們的客户對結賬體驗感到沮喪?」
大模型可能會提供這樣的見解:「客户對結賬流程感到沮喪,因為加載時間太長。他們還想要一種在結賬時編輯地址並保存多種付款方式的方法。」
未來,浪潮源1.0大模型將推動創新企業及個人開發者基於大模型構建智能化水平更高的場景應用,賦能實體經濟智能化升級,促進經濟高質量發展。
圖靈測試答案
對話
問題1
B
問題2
A
問題3
B
問題4
A
對聯
問題1
A
問題2
B
問題3
B
問題4
A
詩歌
問題1
A
問題2
B
問題3
B