Chiplet時代來臨,Die-to-Die接口成新挑戰_風聞
半导体行业观察-半导体行业观察官方账号-专注观察全球半导体最新资讯、技术前沿、发展趋势。2021-10-28 18:36
來源:內容由半導體行業觀察(ID:icbank)原創,作者:杜芹,謝謝。現在超大規模數據中心、人工智能和網絡應用芯片正在追求更高的數據速率和更復雜的功能。隨着芯片的尺寸越來越接近掩膜版極限,開發者不得不將芯片分成多個較小的Die,這些Die封裝在多芯片模塊(MCM)中,在多芯片模塊中,較小的Die通過Die-to-Die互連進行鏈接,這些互連必須具有極低功耗,而且每個Die的邊緣都具有高帶寬,以此來實現高良率並降低總體成本。合適的Die-to-Die接口是影響芯片性能的重要因素。Die-to-Die接口也成為行業趨勢的關鍵因素。
瞭解Die-to-Die接口
Die-to-Die接口是在同一個封裝內的兩個芯片裸片間提供數據接口的功能塊。為了實現功效和高帶寬,它們利用了連接裸片的極短通道的特徵。這些接口通常由一個PHY和一個控制器模塊組成,在兩個裸片的內部互連結構之間提供無縫連接。
Die-to-Die PHY使用高速SerDes架構或高密度並行架構實現,這些架構經過優化以支持多種先進的2D、2.5D和 3D封裝技術。
那麼,Die-to-Die接口如何工作?Die-to-Die接口就像任何其他芯片到芯片接口一樣,在兩個芯片之間建立可靠的數據鏈接。它在芯片運行期間建立和維護鏈路,同時嚮應用程序提供連接到內部互連結構的標準化並行接口。通過添加錯誤檢測和糾正機制(例如前向糾錯 (FEC) 和/或循環冗餘碼 (CRC) 和重試)來保證鏈路可靠性。
接口在邏輯上分為物理層、鏈路層和事務層。其中物理層架構可以是基於 SerDes 的或基於並行的。基於SerDes的架構包括並行到串行(串行到並行)數據轉換、阻抗匹配電路和時鐘數據恢復或時鐘轉發功能。支持NRZ信令或PAM-4信令,帶寬可達112Gbps。SerDes體系結構的主要作用是在簡單的2D封裝(如有機基板)中最小化I/O互連的數量。
基於並行的體系結構包括許多低速、簡單的並行收發器,每個收發器由一個驅動程序和一個具有轉發時鐘技術的接收器組成,以進一步簡化體系結構。支持DDR信令。並行架構的主要作用是在密集的2.5D封裝中最小化功耗,比如硅插入器。
Die之間的接口必須滿足以下多個需求:
首先是電源效率。多芯片系統實現應該與等效的單片實現一樣節能。Die-to-Die鏈路使用短距離、低損耗的通道,沒有明顯的不連續性。PHY 架構利用良好的信道特性來降低PHY複雜性並節省功耗。
其次是低延遲。將服務器或加速器 SoC 劃分為多個芯片不應導致不統一的內存架構,因為訪問具有顯着不同延遲的不同芯片中的內存。Die-to-Die接口實施簡化的協議並直接連接到芯片互連結構以最大限度地減少延遲。
高帶寬效率。高級服務器、加速器和網絡交換機需要在芯片之間傳輸大量數據。Die-to-Die接口必須能夠支持所有所需的帶寬,同時減少芯片邊緣佔用。通常使用兩種替代方法來實現此目標,通過部署具有每通道非常高的數據速率(高達 112 Gbps)的 PHY 來最小化所需通道的數量,或者通過使用更細的Bump來增加 PHY 的密度) 在大量並行化以實現所需帶寬的低數據速率通道(高達 8 Gbps/通道)。
強壯的鏈接。Die-to-Die 鏈接必須沒有錯誤。接口必須有足夠強大的低延遲錯誤檢測和糾正機制,以檢測所有錯誤並以低延遲代價糾正它們。這些機制通常包括 FEC 和重傳協議。
不同應用對Die-to-Die接口的要求
針對HPC、網絡、超大規模數據中心和人工智能 (AI)等應用,Die-to-Die接口主要有4個不同的用例。
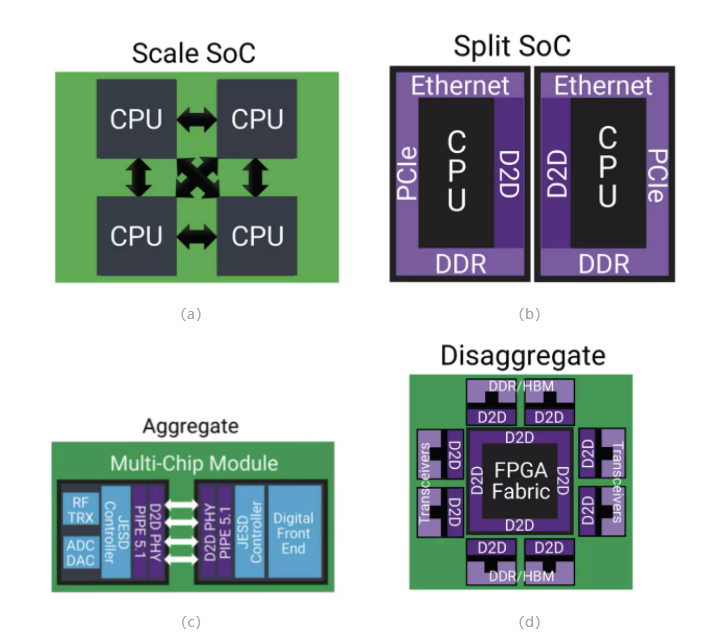
擴展SoC通過連接Die,以實現Die間緊密耦合的性能,從而提高計算能力,併為服務器和AI加速器創建多個SKU,如圖a)。拆分SoC可以製作規模非常巨大的SoC,同時也提高良品率,降低成本,並通過將大型單體SoC分成較小的裸晶組裝在一起,從而延伸了摩爾定律,如圖b)。**“聚合”使不同的裸晶實現多種不同功能,以充分利用每個功能的最佳工藝節點。這種方法還有助於在FPGA、汽車和5G基站等應用中降低功耗,並減小面積,如圖c)。“分解”**使中央數字芯片與I/O芯片分開,便於中央芯片向先進工藝遷移。而I/O芯片維持保守節點,以降低產品演進的風險和成本,支持重複使用,並加快上市速度,如圖d)。
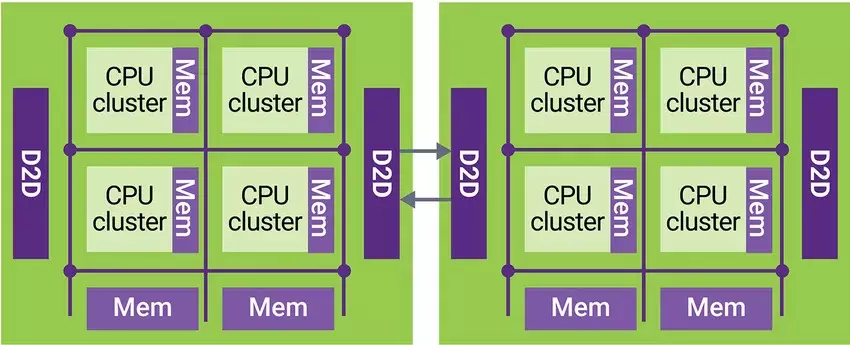
在高性能計算和人工智能應用中,大的芯片被分為兩個或多個同質Die;在網絡應用中,I/O和互連內核被分為單獨的Die。在這些不同種類芯片中, Die-to-Die的互連必須不影響整體系統性能,並且要求低延遲、低功耗和高吞吐量。對於多Die SoC 設計人員來説,需要關注鏈路延遲、跨鏈路的數據一致性、可接受的誤碼率 (BER) 及其控制機制、帶寬和分支以及Die到Die接口協議這些Die-to-Die接口的要求。
例如針對高性能計算 (HPC) 的多裸片SoC 的一個常見用例是在同一封裝中組裝多個同質die,如下圖所示,一個互連網格連接每個die中的所有 CPU 集羣和共享內存組。Die-to-Die鏈路連接兩個Die中的網狀互連,如同它們是同一互連的一部分。在這其中,至關重要的是,一個Die中的 CPU 能夠以最小的延遲訪問另一個die中的內存,同時支持緩存一致性。通常,利用CXL或CCIX 流量的優勢來降低鏈路延遲。
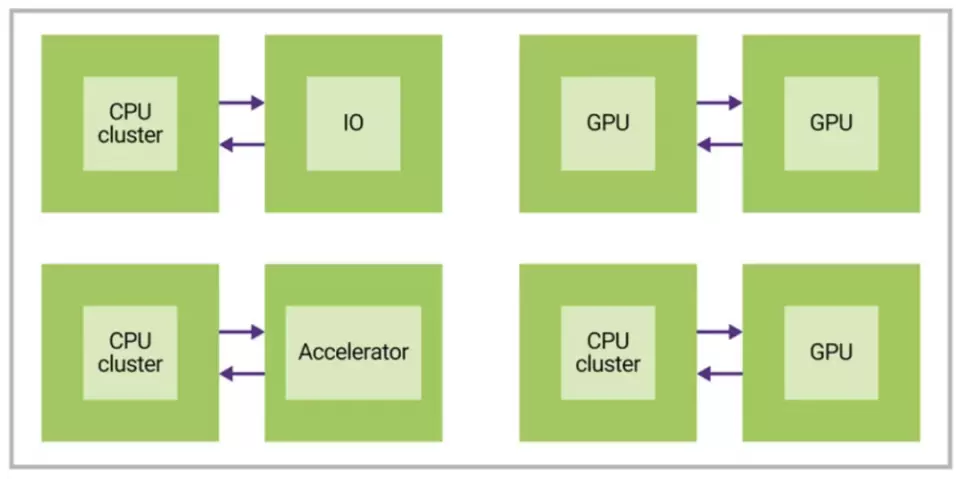
在 IO 訪問這樣的應用中,為了靈活性和效率,數字處理存在於 IO 功能之外的一個單獨的模塊中(IO示例可以是電子SerDes、光學、無線電、傳感器或其他),通常沒有一致性要求,對鏈接延遲更寬容。在這些情況下,IO 流量通常通過標準協議路由,如 AXI 接口。
類似情況如 GPU 和連接到 CPU 集羣的一些異構計算類的加速器這樣的並行架構,可能只需要IO一致性(如果加速器Die沒有緩存),或者根本不需要一致性,如下圖所示。
鏈路錯誤也是一大重要關注的點。為了避免因鏈路錯誤導致數據損壞,進而對系統運行造成災難性影響,Die-to-Die鏈路必須實現允許錯誤檢測和糾正的功能。根據系統要求和原始 PHY BER,有兩個主要選項可用於檢測和糾正傳輸錯誤,這些選項可單獨使用或結合使用:
與錯誤檢測功能結合的重試機制能夠糾正所有檢測到的傳輸錯誤。一個錯誤檢測碼,如奇偶校驗或循環冗餘檢查 (CRC) 碼被添加到發送的數據,以便接收端可以驗證接收的數據,在檢測到錯誤時,請求重新發送數據。前向糾錯 (FEC) 是與數據一起傳輸的更復雜的代碼,能夠檢測和糾正錯誤位。根據 FEC 算法的複雜度,檢測和糾正的錯誤數量可能更高。只是,FEC 編碼和解碼的延遲增加了複雜性。與其他芯片到芯片鏈路一樣,Die-to-Die鏈路的協議棧可以分割成與開放系統互連 (OSI) 模型棧定義一致的不同協議層,如下圖所示。PHY 層由物理介質無關 (PMA) 和物理介質相關 (PMD) 組成。PHY 層處理與通道的電氣接口。邏輯層位於 PHY 層的上方,將 PHY 層的信令特性與鏈路層隔離,輔助數據流構建和恢復。當他們在一起定義和驗證時,每一層都會得到優化,即使每一層都有預定義的接口。
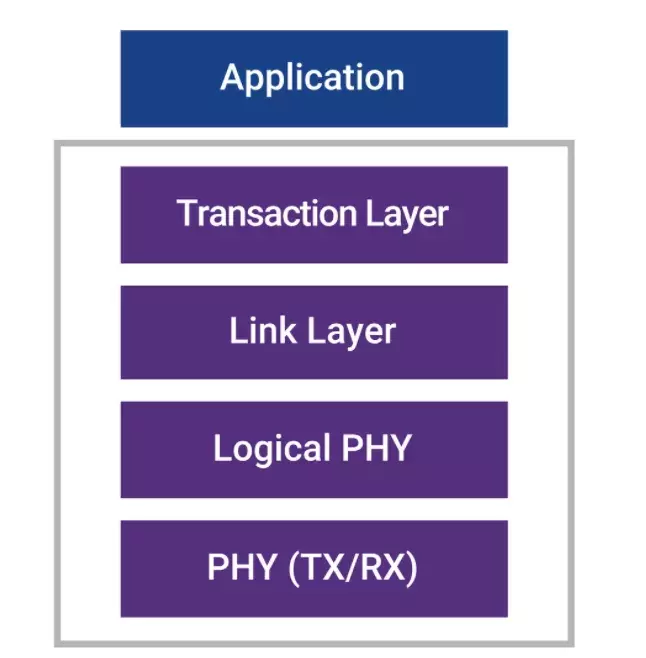
鏈路層管理鏈路將處理錯誤檢測和糾正機制,保證一個端到端無錯誤的鏈路。鏈路層還處理流控,調節發送方和接收方之間的數據通信量。傳輸層從應用層接收讀寫請求,從鏈路層創建和接收請求包。
Die-to-Die鏈路的特性使其不同於傳統的芯片到芯片鏈路。例如,在封裝多Die SoC 時,鏈路的兩端是已知且固定的。因此,Die-to-Die鏈路特性可以提前確定,通過軟件或寄存器在開機時進行設置,避免鏈路發現和協商步驟的複雜性。最好是,Die-to-Die鏈路是一個連接兩個Die的互連結構的簡單“隧道”,而沒有特定的已定義協議。為減少延遲並保證互操作性,理想的做法是將鏈接緊密優化,以便與die上互連結構進行操作。例如,Arm Neoverse 平台定義了支持緩存一致性的專用接口,可用於低延遲的Die-to-Die解決方案。或者,更通用的應用接口(例如 AXI)可用於附接到任何片上互連結構。
新思科技的Die-to-Die IP一網打盡這些需求
針對這些應用方面的不同需求,Synopsys 設計和開發了 完整的DesignWare Die-to-Die IP 解決方案產品組合,為HPC、AI和網絡等應用提供了SoC所需的高帶寬和低延時。完整的解決方案可以提供一個基礎架構,並且不需要重寫代碼或開發橋接。該IP解決方案包括:
DesignWare Die-to-Die控制器IP:它與DesignWare USR/XSR PHY IP集成,為端到端的Die-to-Die鏈接提供了業內最低的延時,並通過錯誤恢復機制實現更高的數據完整性和鏈接可靠性。控制器IP支持AMBA CXS和AXI協議,可實現相干及非相干的數據通信。它還與Arm Neoverse相干網格網絡集成,以增強多芯片、內存擴展和加速器解決方案的性能。DesignWare Die-to-Die PHY IP:包括USR/XSR PHY IP,採用每通道高達112 Gbps的高速SerDes PHY技術,適用於極短和超短距離鏈路,並採用高帶寬互連(HBI) PHY IP,以低延遲為高密度2.5D封裝SoC提供每引腳8 Gbps的Die-to-Die連接。Die-to-Die控制器和PHY IP是新思科技多裸片解決方案的一部分,其中還包括滿足HPC SoC HBM要求的DesignWare HBM IP和用於高級多裸片系統設計與集成的3DIC Compiler統一平台。這種多裸片解決方案有助於加快設計需要高級封裝的SoC。
由於計算密集型、工作負載繁重的HPC應用日漸增多,從單體芯片到Die-to-Die架構的演進勢頭肯定會持續。根據持續發展的標準規範開發和設計的高帶寬、低延遲IP,對確保超大規模數據中心等多種應用都至關重要。