【翻譯轉載】概覽中國的百億億次超級計算機_風聞
guan_15835260112264-2021-11-21 10:02
本人機翻潤色,轉自www.nextplatform.com,原作者Timothy Prickett Morgan 侵刪
美國和中國之間的貿易戰不僅僅是一場自上而下的政治和經濟戰爭,也是一場技術戰爭。而且可以説,2016年6月亮相的神威·太湖之光超級計算機,主要採用本土技術,而不是美國製造的芯片,是這個崛起大國和現有大國之間不可避免的衝突的最新階段的爆發點之一。
美國政客對向中國出售技術感到矛盾,而中國政客對依賴技術感到不情願。因此,中國有投入大量資金,通過同時設計幾個處理器和加速器,幾個互連繫統,以及主要基於其自身技術的千萬億級和現在的百億億級系統來對沖其賭注和減輕其風險。
中國政府在相當長的一段時間內對其高性能計算工作的上層採取了三合一的方法,我們在2016年7月報道了與百億億級系統開發有關的情況。正如美國和歐洲的情況一樣,最大的高性能計算中心傾向於選擇不同的架構和互連,以便在一種技術被推遲的情況下,所有中心都不會受到影響。而在2019年5月,中國政府採取了三管齊下的方式,讓國防科技大學(NUDT)、國家並行計算機工程技術研究中心(NRCPC)和服務器製造商曙光公司(原曙光公司)相互競爭,提出了三種依靠完全獨特組件的不同的級聯設計。
這三台機器中的一台的結構細節剛剛浮出水面,即神威的超大規模計算機,它是安裝在無錫國家超級計算中心的神威太湖之光系統的後續產品,是中國各地十幾個此類中心之一。太湖之光系統在2016年6月的國際超級計算會議上大張旗鼓地亮相,代表了中國早期令人印象深刻的混合計算努力,該機器主要專注於傳統的HPC模擬和建模工作負載,但也能夠進行數據分析和一些機器學習工作的規模。這台尚未命名的神威百億億超級計算機是太湖之光系統的後繼,前者從2016年6月到2018年11月,它被評為世界上最快的超級計算機,今天仍然排名第四。
在審查了神威太湖之光和神威百億億次系統的規格後,有一件事對我們來説是非常清楚的。申威架構從一開始就被設計為推入百億億次性能範圍及以上,而且它在實現專用混合架構方面做得比我們迄今為止看到的其他方法要簡潔得多。其他混合CPU-GPU或CPU-DSP設計--包括由國防科技大學為廣州國家超級計算機中心設計的天河系列系統(天河二號、天河二號A和未來的天河三號超大規模機器)--其串行和並行部件耦合得不那麼緊密。但是這些混合系統給了系統架構師一個機會,讓他們可以隨時調整這些組件的比例,這也是有價值的。這説明了一個工程原則,即你必須放棄一些東西才能得到其他東西。總是有一個折衷。或幾十個。
申威系統的處理器已經鎖定了這些比率,你沒有什麼辦法來改變它。但每瓦特的性能和可擴展性看起來更好。因此,有了這個
【在三個不同的載體上加倍努力以達到百億億次的目標】
在進入神威百億億次系統之前,回顧一下太湖之光系統的架構及其自制的SW26010 RISC處理器可能是個好主意。
正如今天的許多CPU實際上相當於2000年左右在單個芯片上實現了4或8個節點的整個嬰兒NUMA服務器一樣,SW26010處理器類似於在單個芯片上實現了4個節點的嬰兒混合超級計算機。太湖之光系統中的這些SW26010處理器在物理上是聯結在一起的,在邏輯上跨越了一台機器,圖像中的40,960個處理器有1,065萬個內核,都是以連貫的方式連接在一起。
下面是由NRCPC設計和製造的SW26010處理器的內部。
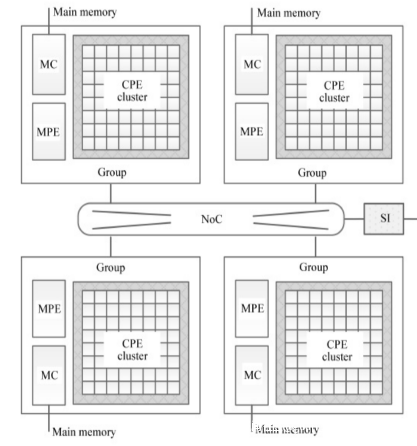
申威芯片有用於串行工作的胖核心和用於並行工作的瘦矢量核心網格,正是在這個意義上,它就像一台嬰兒混合超級計算機。這些胖子和瘦子核心的組合被稱為核心組,或稱CG。在SW26010處理器中,有一個胖核心,稱為管理處理元件(MPE),它直接連接到一個由64個計算處理元件(CPE)組成的8×8網格,通過網狀網絡連接。MPE和CPE核心都是基於一個不知名的64位核心,有趣的是兩者都支持256位寬的矢量單元。
MPE具有亂序執行功能,支持超標量處理,就像大多數RISC處理器多年來所做的那樣。它可以在用户或系統模式下運行,有32KB的L1數據緩存和256KB的L2緩存;CPE內核只在用户模式下運行,除了有256位矢量外,它們還有16KB的L1緩存和64KB的 “草稿紙內存”,據推測,所有CPE內核之間的緩存是不一致的。這些核心都以1.45 GHz的速度運行,這與我們現在看到的GPU核心的運行速度相同。
每個核心組都有一個共享的內存空間和自己的內存控制器,在這種情況下,它是一個DDR3內存控制器。SW26010處理器有四個這樣的核心組,通過芯片上的高速網絡連接在一起;它看起來像一個環形互連,就像我們在許多SoC和過去的一些單片CPU中看到的那樣,但論文中説它是一個 “片上環形網絡”。這就是四個MPE和256個CPE,共260個內核。因此,我們認為,申威處理器的名稱是:260個核心加上第一代等於2601,再加一個零為五位數,也許是為了在芯片製造上可能的子版本。
每個核心組都有一個系統互連(SI),將處理器與整個太湖之光集羣的管理網絡掛鈎,同時還有一個協議處理單元(PPU),圖中沒有顯示,它可能是實現PCI-Express 3. 0總線出去的網絡接口,更具體地説,我們知道這些接口以某種方式到達一組8個56Gb/sec FDR InfiniBand主機總線適配器,如下圖所示,在太湖之光超級節點上,每個主板上有8個SW26010處理器(4個在上面,4個在板子的下面)。像這樣。
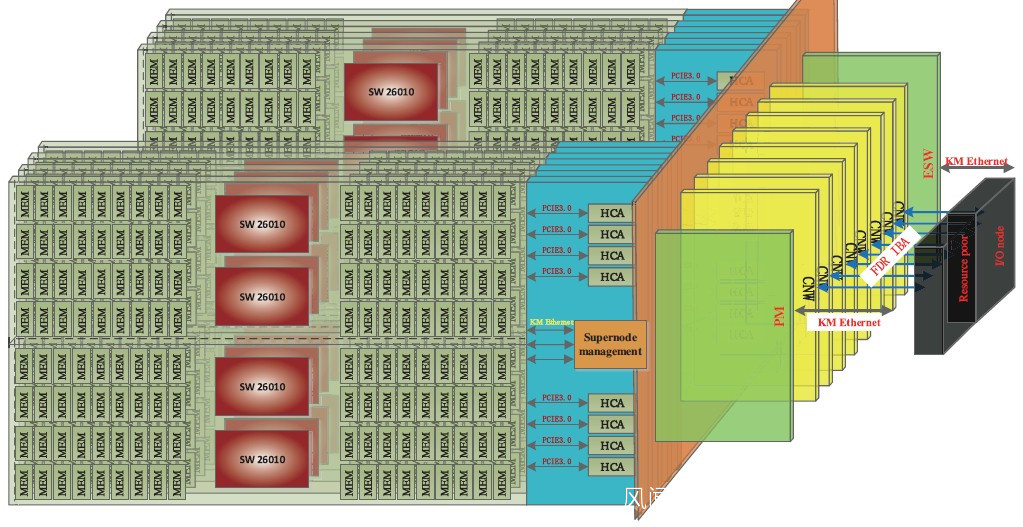
我們還注意到,每個內存控制器有九個DDR3 DIMM掛在上面,所以在系統板的內存上有一些冗餘數據保護。每個處理器可以訪問32GB的內存(每個核心組8GB),這並不是一個很大的內存,但是在40,960個節點上,加起來就是1.25PB,這絕對是一個很大的內存。
SW26010處理器的準混合型多核架構是神威超級計算機設計的秘訣,這也是為什麼它可以進行相當適度的調整而仍然達到百億億級性能的原因之一。我們將讓《中國科學報》上由高建剛(音)領導的論文作者來談這個問題,因為這很重要。
“基於HPC應用通常是可分離的和有規律的,SW多核處理器的性能通過整合大量的簡化計算核心得到了極大的提高。更復雜的通用核心也是處理程序的串行部分和滿足超級計算中心應用的多樣性的必要組成部分。與 “CPU+加速器 “的方法不同,SW多核處理器將不同類型的內核異質地整合在一個芯片中。在異構架構中,少數強大的管理處理元件(MPEs)負責發現指令級的並行性並管理芯片,而大量的計算處理元件(CPEs)旨在處理線程級的並行性,這大大提高了芯片的性能。這種多核處理器的異構性可以同時提供通用CPU的靈活性和加速器的高性能,有效提高計算密度。值得注意的是,採用了統一的指令集,便於軟件系統的設計和兼容”。
因此,如果你要建造神威太湖之光超級計算機,你將如何把它從125 千萬億次每秒峯值雙精度性能擴展到至少1 百億億次?有很多方法可以做到這一點,但根據本文,NRCPC採取了一些明顯的方法,部分原因是芯片工藝製造的縮減,而這些縮減無疑是由中芯國際集成電路製造有限公司提供的,該公司是中國的大型本土代工廠,正試圖通過其芯片代工廠與台灣半導體制造公司、三星電子和英特爾並駕齊驅。中芯國際的14納米FinFET工藝是在2019年批量生產的,所以SW26010使用的是更老的工藝,而中芯國際的新N+1工藝據説相當於三星的8納米工藝,比台積電的10納米工藝更好。這種N+1工藝用在可能在今年投產的芯片上有點年輕。因此,假設SW26010是用28納米工藝製造的,我們認為未來的信申威超大規模處理器--我們稱之為SW52020,原因一會兒就會很明顯--將有能力將處理器芯片尺寸縮小不少,保持時鐘不變或更低,並大幅提升芯片上的計算單元。通過使用14納米,NRCPC可以期望通過8納米或更小的製程--以嘗試在未來的機器上推進到10百億億次。
深入研究神威百億億次機器的架構,NRCPC所做的第一件事是將未來處理器上的核心組數量增加一倍,從SW26010的四個增加到我們稱之為SW52020的八個。這樣做的效果是將兩倍的計算元素塞進同一個構件,在相同的時鐘速度下,設備與設備之間的峯值性能提升了2倍。因此,從260個內核到520個內核,只是為了説明問題。
NRCPC所做的第二件事是將MPE和CPE內核中的矢量引擎從256位擴展到512位。而結合計算元素的翻倍,SW52020的性能現在更寬了。此外,矢量單元不僅支持32位單精度和64位雙精度浮點運算,而且現在還支持16位半精度浮點,這對某些HPC和許多AI工作負載來説是非常有用的。
無論如何,在相同的1.45GHz時鐘速度下,計算元素的翻倍將性能提升到約6.12兆位,NRCPC很可能會保持這個速度,而矢量寬度的翻倍將峯值性能再次提升到12.24兆位--文件中正式説 “超過12兆位--每塊芯片。因此,如果神威太湖之光系統在40,960個節點(在40個由160個超級節點組成的機櫃中,每個節點有256個SW26010處理器)上能夠達到125.4 千萬億次的性能,那麼只要加入新的處理器就能使系統達到501.4 千萬億次每秒的峯值性能。
這只是通往百億億規模的一半,除非你想四捨五入,四捨五入就是百億億—我們不想這樣做,NRCPC也不想這樣做。因此,在這一點上只有一個選擇,那就是擴大網絡,為系統增加更多的節點。而這正是NRCPC正在做的神威百億億次系統。論文中説該機器將有超過80,000個節點,但我們的計算表明,如果我們所説的SW52020的時鐘速度保持在1.45GHz不變,它將需要81,920個節點來完成工作。這將使你達到神話般的神奇的1.028 百億億次每秒峯值性能,未來的神威機器可以合法地被稱為HPC和AI的百億億次級系統。
下面是神威百億億次系統的方框圖。
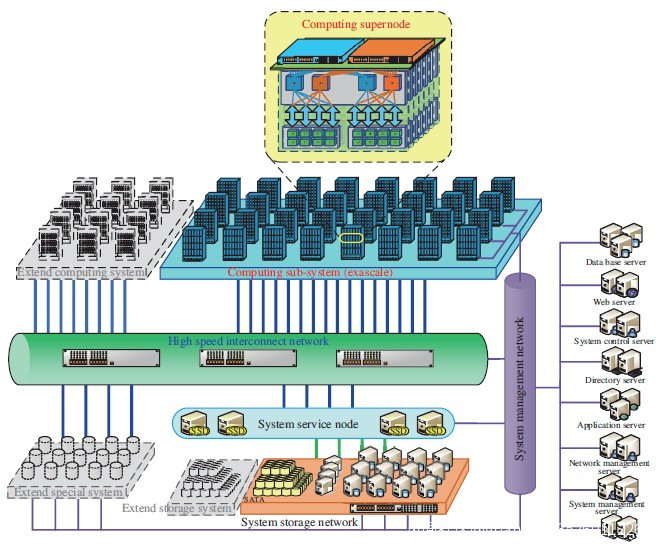
在這張圖片中很難看出來,但看起來一個超級節點仍將有256個SW處理器。我們將單獨鑽研這個未來的神威百億億次系統的網絡,並對此進行研究。
我們想知道的是,每個人都想知道的是,相對於神威太湖之光機器,神威百億億次系統的預期性能將是什麼,而論文的作者在這方面提供了一些指導。
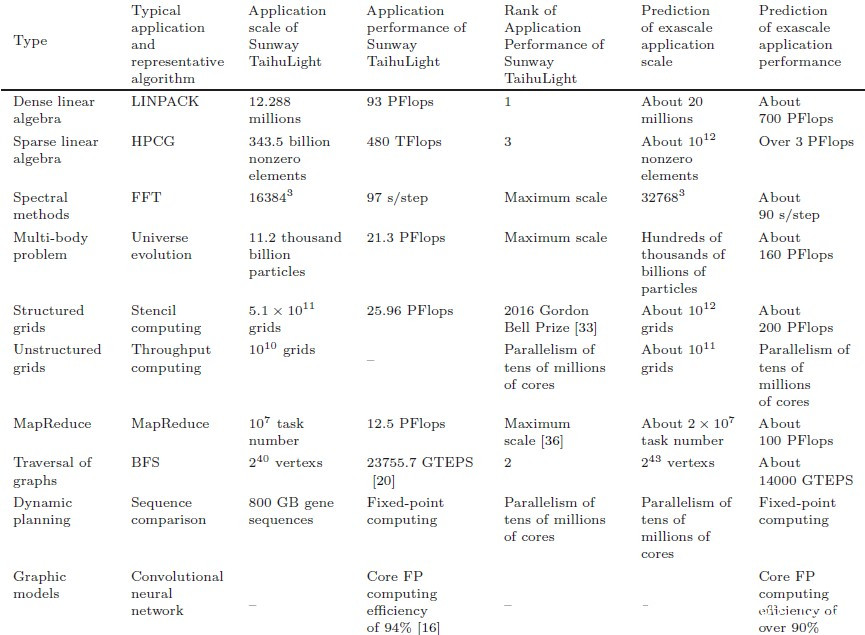
太湖之光系統的峯值理論性能為125.4 千萬億次每秒,在15.37兆瓦的功率範圍內,運行高性能Linpack(HPL)基準時,可計算93千萬億次每秒。這相當於74.2%的計算效率。預計在Linpack測試中,神威的超大規模機器將提供約700 千萬億次每秒的性能,而峯值機器為1 百億億次每秒,或約70%。網絡更大,而且有一些固有的延遲,我們將在另一篇後續文章中討論,但它也有更多的帶寬(8倍),處理器有更多的內存帶寬(6.8倍),足以彌補處理器性能的4倍增長和網絡的2倍規模,以覆蓋節點數的翻倍。淨效果是,正如你在上表中看到的,NRCPC預計Linpack的性能從太湖之光轉移到百億億次系統中會有7.5倍的增長,但是在超級計算機碾壓式的高性能共軛梯度(HPCG)基準上,有效性能將從480 萬億次每秒的有效性能上升至少6.3倍,超過3 千萬億次每秒的有效性能。
正如你在上表中所看到的,性能範圍從使用快速傅里葉變換的光譜方法基準的低2倍(好吧,2倍的規模和每步稍快的性能)。在上表中的許多測試中,應用程序的預期性能提升在7.5倍和7.7倍之間,這對於原始的8倍性能提升來説還不錯。有趣的是,MapReduce的規模將擴大8倍,但只能提供大約100 千萬億次每秒的性能。我們對一個與MapReduce掛鈎的浮點性能指標感到好奇,為什麼它似乎只用了神威百億億次系統或之前的太湖之光系統的十分之一。
接下來,我們將討論Sunway exascale系統的內存、存儲和網絡。(本文完)通過www.DeepL.com/Translator(免費版)翻譯