撬開驍龍8一看,滿滿都是頂會論文_風聞
量子位-量子位官方账号-2021-12-22 17:47
蕭簫 邊策 發自 凹非寺
量子位 報道 | 公眾號 QbitAI
“拍照優化、語音助手以外,手機AI還有什麼?”
今年全新一代驍龍8移動平台發佈時,高通再次翻譯翻譯了,什麼叫腦洞大開——
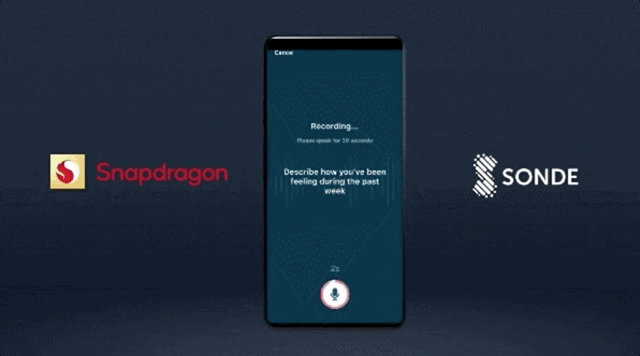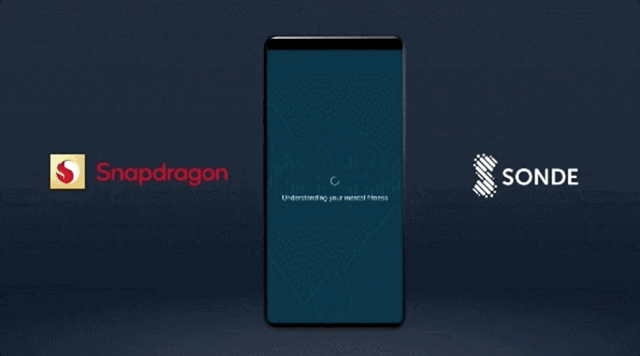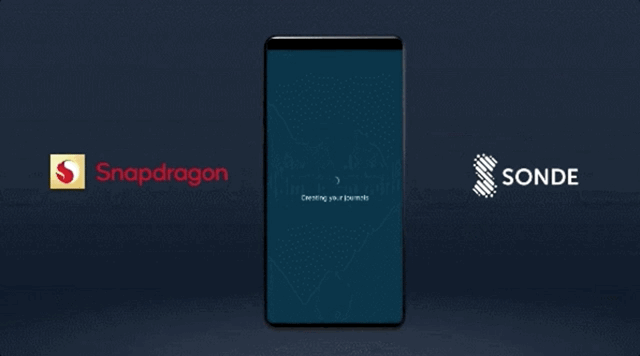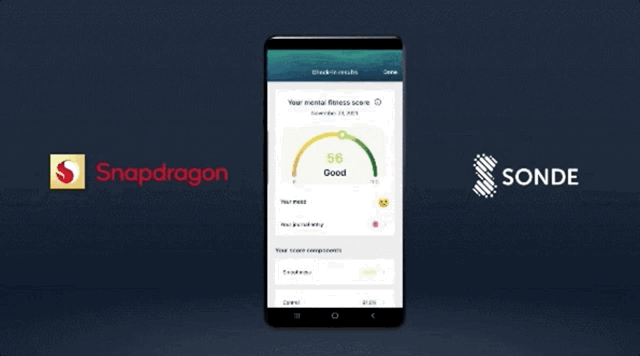
讓手機學會“聽診”,通過語音識別出用户可能存在的疾病,比如抑鬱症、哮喘;
讓手機實現“防偷窺”,通過識別陌生用户的視線,實現自動鎖屏;

讓手機遊戲搞定超分辨率,將以往PC端才有能力運行的畫質,搬到手機上體驗……
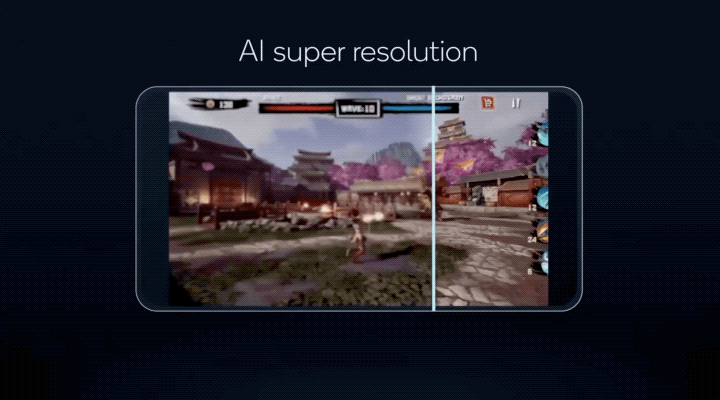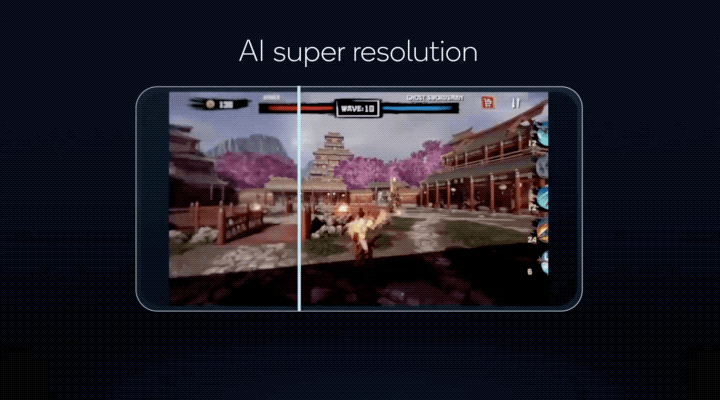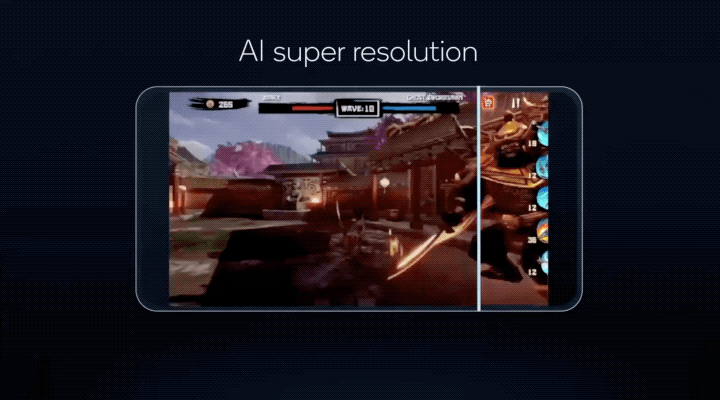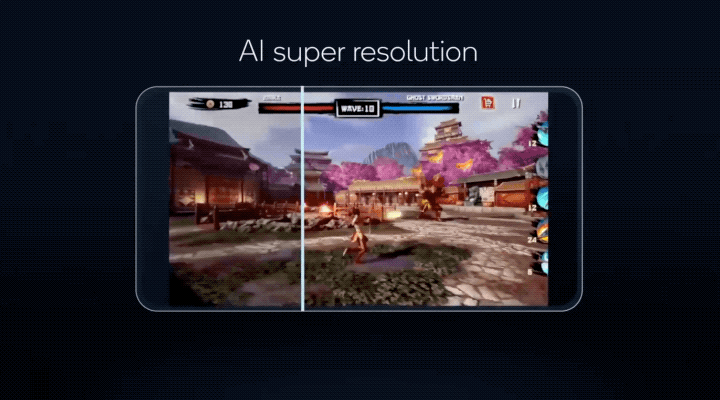
更重要的是,這些AI功能,驍龍8有能力同時運行!
高通聲稱,驍龍8搭載的第7代AI引擎,性能相比上一代最高提升了4倍。

這意味着我們玩手機的時候,同時“多開”幾個AI應用也沒問題。更重要的是,它不僅僅是簡單的AI性能提升,更能給用户帶來流暢的應用體驗感。
在硬件製程升級如此艱難的今天,高通是如何在第7代AI引擎的性能和應用上“翻”出這麼多新花樣的?
我們翻了翻高通發表的一些研究論文和技術文檔,從中找到了一些“蛛絲馬跡”:
在高通發佈的AIMET開源工具文檔裏,就有提到關於“如何壓縮AI超分辨率模型”的信息;
在與“防偷窺”相關的一篇技術博客中,介紹瞭如何在隱私保護的前提下使用目標檢測技術……
而這些文檔、技術博客背後的頂會論文,全都來自一家機構——高通AI研究院。

可以説,高通把不少研究院發表的AI論文,“藏”在了第7代AI引擎裏。
頂會論文“藏身”手機AI
先來看看第7代AI引擎在拍照算法上的提升。
針對智能識別這個點,高通今年將面部特徵識別點增加到了300個,能夠捕捉到更為細微的表情變化。
但同時,高通又將人臉檢測的速度提升了300%。這是怎麼做到的?

在一篇高通發表在CVPR上的研究中,我們發現了答案。
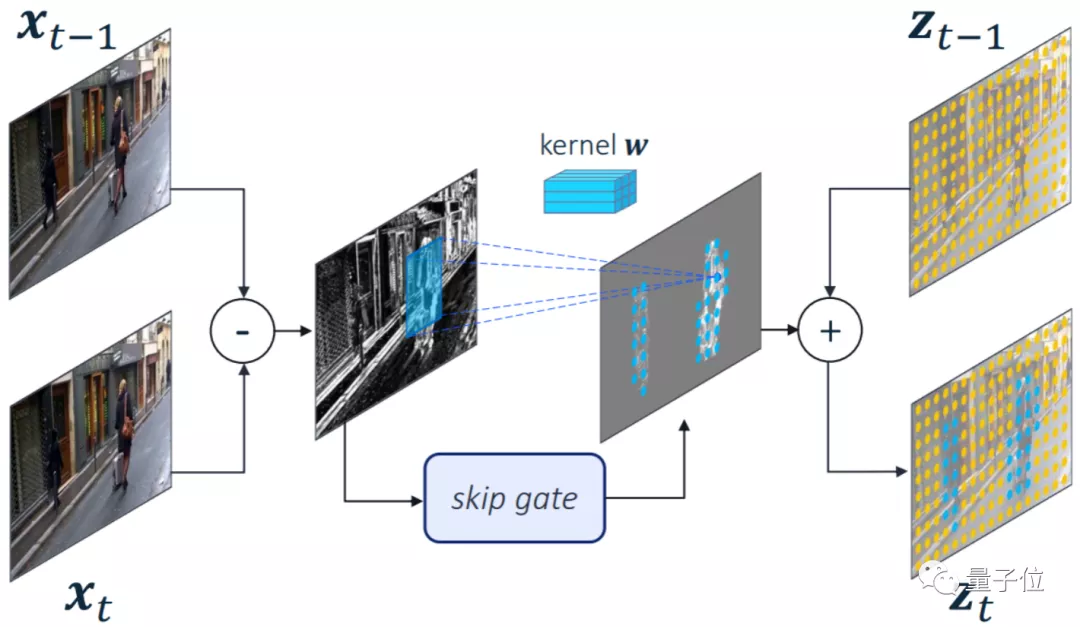
在這篇文章中,高通提出了名為Skip-Convolutions(跳躍卷積)的新型卷積層,它能將前後兩幀圖像相減,並只對變化部分進行卷積。
沒錯,就像人的眼睛一樣,更容易注意到“動起來的部分”。
這使得驍龍8在做目標檢測、圖像識別等實時檢測視頻流的算法時,能更專注於目標物體本身,同時將多餘的算力用於提升精度。
可能你會問,這樣細節的人臉識別對於拍照有什麼用?
更進一步來説,這次高通與徠卡一起推出了Leica Leitz濾鏡,用的是基於AI的智能引擎,其中就包括了人臉檢測等算法,使得用户能更不經思考智能地拍出更具藝術風格的照片。

不止人臉檢測,高通在智能拍攝上所具備的功能,還包括超分辨率、多幀降噪、局部運動補償……
然而,在高分辨率拍攝中的視頻流通常是實時的,AI引擎究竟如何智能處理這麼大體量的數據?
同樣是一篇CVPR論文,高通提出了一個由多個級聯分類器組成的神經網絡,可以隨着視頻幀的複雜度,來改變模型所用的神經元數量,自行控制計算量。
面對智能視頻處理這種“量大複雜”的流程,AI現在也能hold住了。
智能拍照以外,高通的語音技術這次也是一個亮點。
像開頭提到的,第7代AI引擎支持用手機加速分析用户聲音模式,以確定哮喘、抑鬱症等健康狀況的風險。
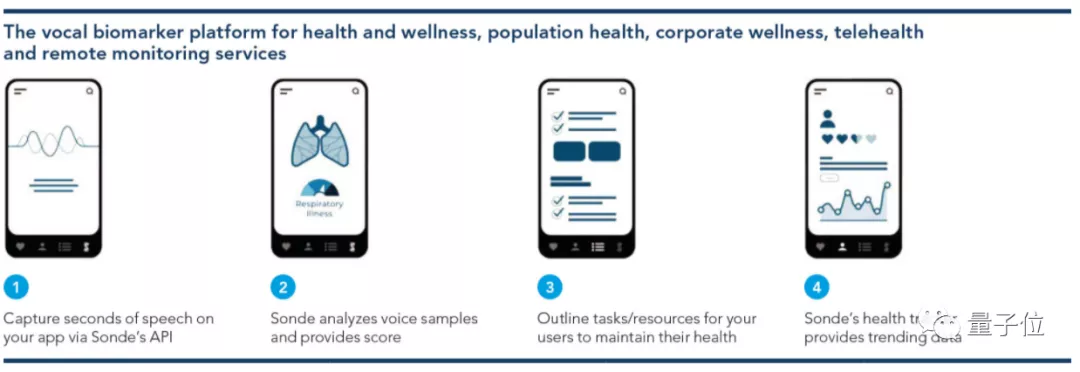
那麼,它究竟是如何準確分辨出用户聲音,而且又不涉及收錄數據的?
具體來説,高通提出了一種手機端的聯邦學習方法,既能使用手機用户語音訓練模型,同時保證語音數據隱私不被泄露。
像這樣的AI功能,有不少還能在高通AI研究院發表的論文中找到。
同樣也能尋到蛛絲馬跡的,是開頭提及的AI提升手機性能的理論支撐。這就不得不提到一個問題:
同時運行這麼多AI模型,高通究竟是怎麼提升硬件的處理性能的?
這裏就不得不提到高通近幾年的一個重點研究方向量化了。
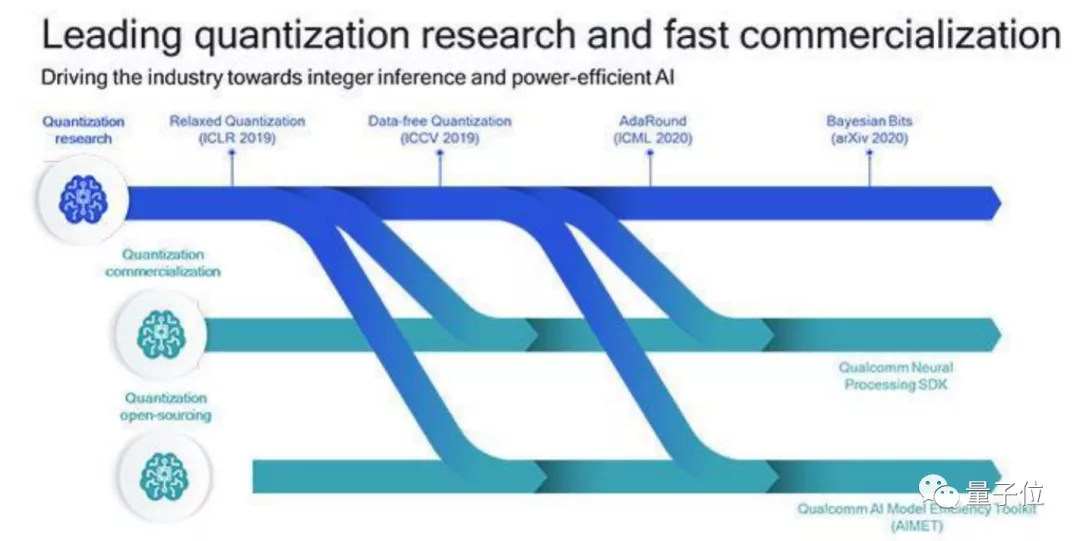
從高通最新公佈的技術路線圖來看,模型量化一直是AI研究院這幾年鑽研的核心技術之一,目的就是給AI模型做個“瘦身”。
由於電量、算力、內存和散熱能力受限,手機使用的AI模型和PC上的AI模型有很大不同。
在PC上,GPU動輒上百瓦功率,AI模型的計算可以使用16或32位浮點數(FP16、FP32)。而手機SoC只有幾瓦功率,也難存儲大體積AI模型。
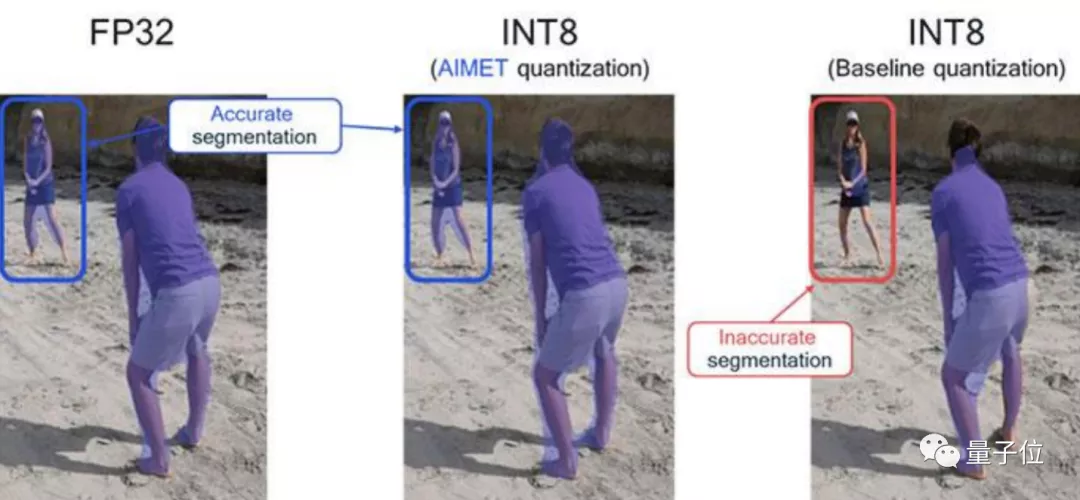
這時候就需要將FP32模型縮小成8位整數(INT8)乃至4位整數(INT4),同時確保模型精度不能有太大損失。

以AI摳圖模型為例,我們以電腦處理器的算力,通常能實現十分精準的AI摳圖,但相比之下,如果要用手機實現“差不多效果”的AI摳圖,就得用到模型量化的方法。
為了讓更多AI模型搭載到手機上,高通做了不少量化研究,發表在頂會上的論文就包括免數據量化DFQ、四捨五入機制AdaRound,以及聯合量化和修剪技術貝葉斯位(Bayesian Bits)等。
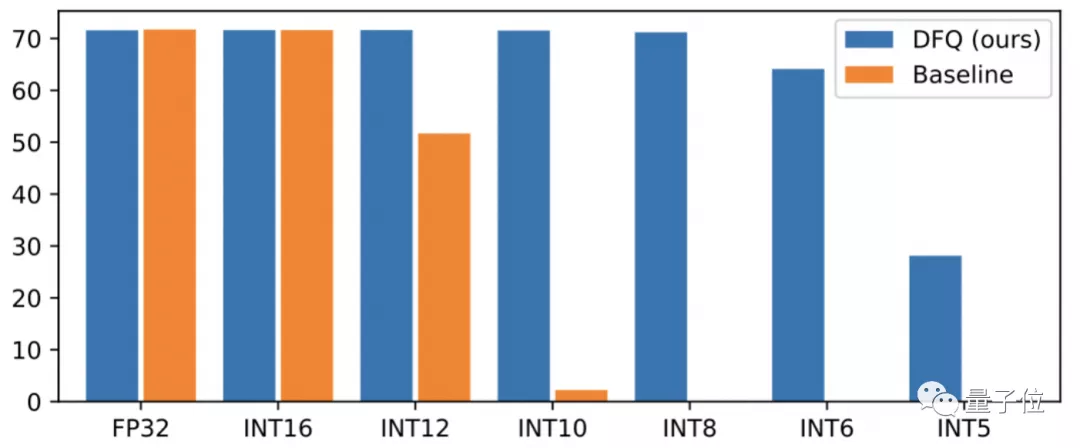
其中,DFQ是一種無數據量化技術,可以減少訓練AI任務的時間,提高量化精度性能,在手機上最常見的視覺AI模型MobileNet上,DFQ達到了超越其他所有方法的最佳性能:
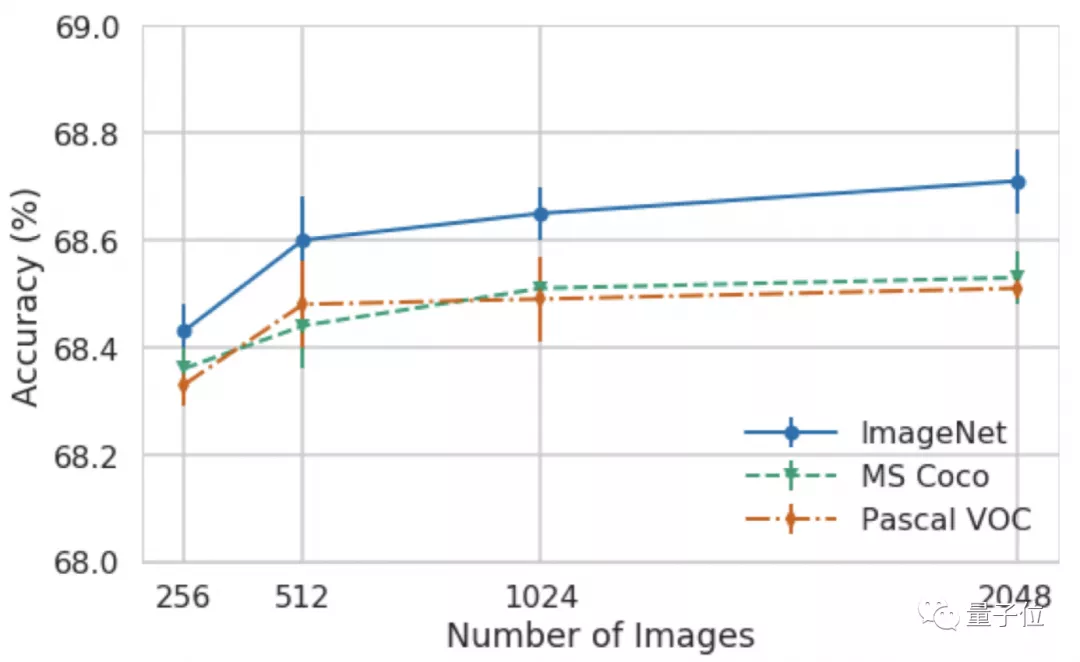
AdaRound則可以將複雜的Resnet18和Resnet50網絡的權重量化為4位,大大減少了模型的存儲空間,同時只損失**不到1%**的準確度:
貝葉斯位作為一種新的量化操作,不僅可以將位寬度翻倍,還能在每個新位寬度上量化全精度值和之前四捨五入值之間的殘餘誤差,做到在準確性和效率之間提供更好的權衡。
這些技術不僅讓更多AI模型能以更低的功耗在手機上運行,像原本只能在電腦上運行的遊戲AI超分辨率(類似DLSS),現在實現能在驍龍8上運行的效果;
甚至其中一些AI模型,還能“同時運行”,例如其中的姿態檢測和人臉識別:

事實上,論文還只是其中的第一步。
要想快速將AI能力落地到更多應用上,同樣還需要對應的更多平台和開源工具。
將更多AI能力釋放到應用上
對此,高通保持一個開放的心態。
這些論文中高效搭建AI應用的方法和模型,高通AI研究院通過合作、開源等方法,將它們分享給了更多開發者社區和合作伙伴,我們也因此能在驍龍8上體驗到更多有意思的功能和應用。
一方面,高通與谷歌合作,將快速開發更多AI應用的能力分享給了開發者。
高通在驍龍8上搭載了谷歌的Vertex AI NAS服務,還是每月更新的那種,意味着開發者在第7代AI引擎上開發的AI應用,其模型性能也能快速更新。
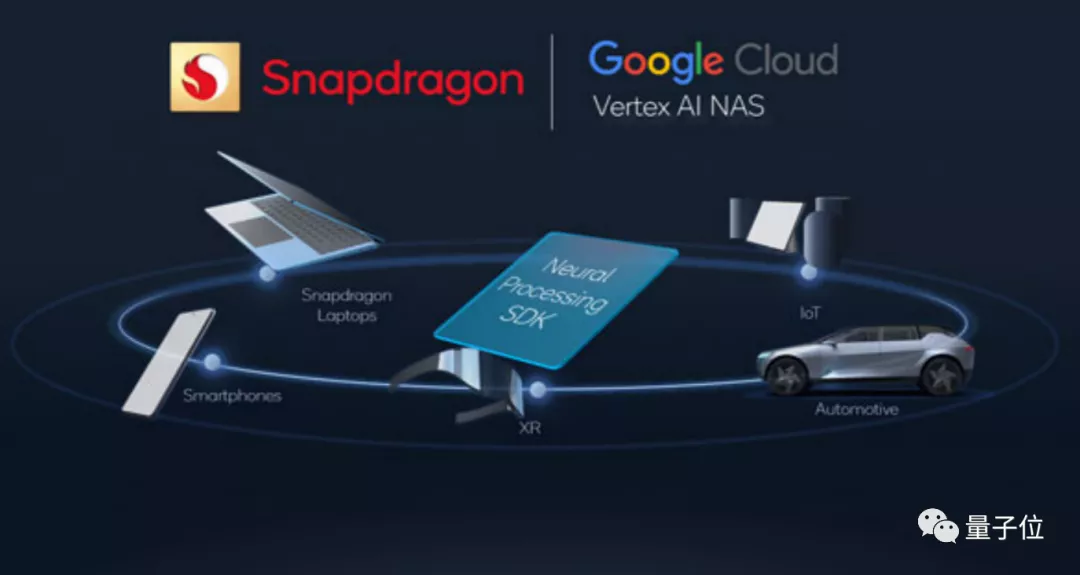
採用NAS,開發者就能自動用AI生成合適的模型,包括高通發表在頂會上的智能拍照算法、語音翻譯、超分辨率……都能包含在AI的“篩選範圍”中,自動為開發者匹配最好的模型。
這裏用上了高通的運動補償和插幀等算法。而類似於這些的AI技術,開發者們也都能通過NAS實現,還能讓它更好地適配驍龍8,不會出現“調教不力”的問題。
想象一下,你將來用搭載驍龍8的手機打遊戲時,會感覺畫面更流暢了,但是並不會因此掉更多的電(指增加功耗):

同時,關於AI模型的維護也變得更簡單。據谷歌表示,與其他平台相比,Vertex AI NAS訓練模型所需的代碼行數能減少近80%。
另一方面,高通也已經將自己這些年研究量化積累的工具進行了開源。
去年,高通就開源了一個名為AIMET(AI Model Efficiency Toolkit)的模型“提效”工具。
其中包含如神經網絡剪枝、奇異值分解(SVD)等大量壓縮和量化算法,有不少都是高通AI研究院發表的頂會論文成果。開發者用上AIMET工具後,就能直接用這些算法來提效自己的AI模型,讓它更流暢地在手機上運行。

高通的量化能力也不止開源給普通開發者,同樣能讓頭部AI企業的更多AI應用在驍龍8上實現。
在新驍龍8上,他們與NLP領域知名公司Hugging Face進行合作,讓手機上的智能助手可以幫用户分析通知並推薦哪些可優先處理,讓用户對最重要的通知一目瞭然。
在高通AI引擎上運行它們的情緒分析模型時,能做到比普通CPU速度快30倍。

正是技術研究的沉澱和技術上保持的開放態度,才有了高通不斷刷新手機業界的各種AI“新腦洞”:
從之前的視頻智能“消除”、智能會議靜音,到今年的防窺屏、手機超分辨率……
還有更多的論文、平台和開源工具實現的AI應用,也都被搭載在這次的AI引擎中。
而一直隱藏在這些研究背後的高通AI研究院,也隨着第7代AI引擎的亮相而再次浮出水面。
高通AI的“軟硬兼備”
大多數時候,我們對於高通AI的印象,似乎還停留在AI引擎的“硬件性能”上。
畢竟從2007年啓動首個AI項目以來,高通一直在硬件性能上針對AI模型提升處理能力。
然而,高通在AI算法上的研究,同樣也“早有籌謀”。
2018年,高通成立AI研究院,負責人是在AI領域久負盛名的理論學者Max Welling,而他正是深度學習之父Hinton的學生。
據不完全統計,高通自成立AI研究院以來,已有數十篇論文發表在NeurIPS、ICLR、CVPR等AI頂級學術會議上。

其中,至少有4篇模型壓縮論文已在手機AI端落地實現,還有許多計算機視覺、語音識別、隱私計算相關論文。
上述的第7代AI引擎,可以説只是高通近幾年在AI算法研究成果上的一個縮影。
通過高通AI的研究成果,高通還成功將AI模型拓展到了諸多最前沿技術應用的場景上。
在自動駕駛上,高通推出了驍龍汽車數字平台,“包攬”了從芯片到AI算法的一條龍解決方案,目前已同25家以上的車企達成合作,使用他們方案的網聯汽車數量已經達到2億輛。
其中,寶馬的下一代輔助駕駛系統和自動駕駛系統,就將採用高通的自動駕駛方案。
在XR上,高通發佈Snapdragon Spaces XR了開發平台,用於開發頭戴式AR眼鏡等設備和應用。
通過和Wanna Kicks合作,驍龍8還將第7代AI引擎的能力帶到了AR試穿APP上。

在無人****機上,高通今年發佈了Flight RB5 5G平台,其中有不少如360°避障、無人機攝影防抖等功能,都能通過平台搭載的AI模型實現。其中首架抵達火星的無人機“機智號”,搭載的就是高通提供的處理器和相關技術。
回過頭看,不難發現這次高通在AI性能上不再強調硬件算力(TOPS)的提升,而是將軟硬件作為一體,得出AI性能4倍提升的數據,並進一步強化AI應用體驗的全方位落地。
這不僅表明高通更加註重用户實際體驗的感受,也表明了高通對自身軟件實力的信心,因為硬件已經不完全是高通AI能力的體現。
可以説驍龍8第7代AI引擎的升級,標誌着高通AI軟硬一體的開端。
最近,高通針對編解碼器又提出了幾篇最新的研究,分別登上了ICCV 2021和ICLR 2021。
這些論文中,高通同樣用AI算法,展現了針對編解碼器優化的新思路。
在一篇採用GAN原理的研究中,高通最新的編解碼器算法讓圖像畫面不僅更清晰、每幀也更小了,只需要14.5KB就能搞定:

相比之下,原本的編解碼算法每幀壓縮到16.4KB後,樹林就會變得無比模糊:

而在另一篇用插幀的思路結合神經編解碼器的論文中,高通選擇將基於神經網絡的P幀壓縮和插幀補償結合起來,利用AI預測插幀後需要進行的運動補償。
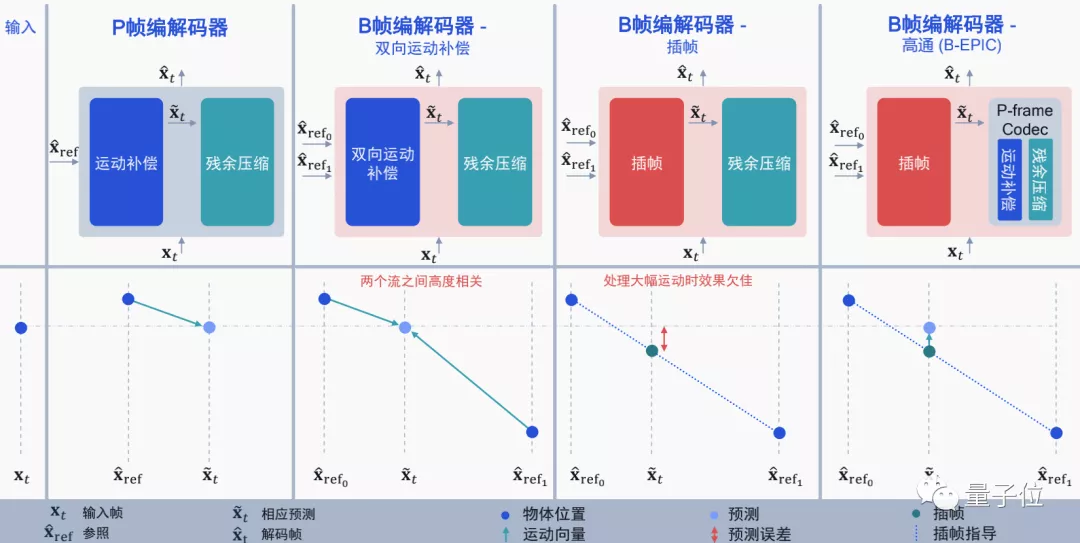
經過測試,這種算法比谷歌之前在CVPR 2020上保持的SOTA紀錄更好,也要好於當前基於H.265標準實現開源編解碼器的壓縮性能。
將AI模型應用於更多領域中,高通已經不是第一次嘗試,像視頻編解碼器的應用,就又是一個新的方向。
如果這些模型能成功被落地到平台甚至應用上,我們在設備上看視頻的時候,也能真正做到不卡。
隨着“軟硬一體”的方案被繼續進行下去,未來我們説不定真能看見這些最新的AI成果被應用到智能手機上。
結合高通在PC、汽車、XR等領域的“秀肌肉”……
可以預見的是,你熟悉的高通、你熟悉的驍龍,肯定不會止於手機,其AI能力,也將不止於手機。
部分論文地址:[1]https://arxiv.org/abs/2104.11487
[2]https://arxiv.org/abs/2104.13400
[3]https://arxiv.org/abs/2104.08776
[4]https://arxiv.org/abs/1906.04721
[5]https://arxiv.org/pdf/2004.10568.pdf
[6]https://arxiv.org/abs/1906.04721
[7]https://arxiv.org/pdf/2104.00531.pdf
參考鏈接:https://www.qualcomm.com/news