全面覆蓋CV任務!這個國產“書生”只學10%內容,性能就超越同行_風聞
量子位-量子位官方账号-2021-12-23 22:02
邊策 金磊 發自 凹非寺
量子位 報道 | 公眾號 QbitAI
河邊有個AI攝像頭可以檢測偷排污水,能不能順手讓它幫個忙,有人掉河裏時也發個警告?
很難。
這要求有更通用的智能,因為對AI來説這是兩個完全不同的任務。況且,可用的數據很少。
得有大量人掉河裏的數據。可惜素材並不好找。難道讓程序員親自“跳進污水河”來構建一個數據集?
一個看似簡單的附加小需求,實則很難且成本很高。
而這就是當下要突破的核心瓶頸:
具備零樣本和少樣本學習能力的全能AI勢在必行。
自然語言領域首先邁出了第一步,GPT-3讓我們看到在海量數據下AI舉一反三的能力。
現在計算機視覺領域也迎來了一次“變天”。
繼通用語言模型的巨大成功之後,在“大力出奇跡”這件事情上,搞計算機視覺的也邁出了這樣的重要一步。
上海人工智能實驗室聯合商湯科技、香港中文大學、上海交通大學共同發佈了通用視覺模型(General Vision Model)“書生”(INTERN)。

這位“書生”的學習效率有多高呢?
據透露,只要“書生”看過每種花的一兩個樣本,就能實現**99.7%**的花卉分類準確率。
也就是説,在開頭那個問題中,只要城市的安防攝像頭捕捉到一次意外事故,今後AI就可以做到識別和預警。
揹負猜想能力“書生”
從通用視覺技術體系的名字來看,團隊將其命名為“書生”背後有着這樣的一個希冀:
可通過持續學習,舉一反三,逐步實現計算機視覺領域的融會貫通,最終實現靈活高效的模型部署。
而現實情況是,過去的CV領域對AI模型的研究多集中於處理單一任務上。
但是隨着AI技術在產業中的不斷深化,AI的應用也在向複雜的多任務協同演進。
以自動駕駛為例,一套視覺模型要識別各個物體的種類,還要預測障礙物距離、行人可能的運動軌跡。
無論如何,這都是單一視覺模型無法完成的。

同時AI模型還有很多無法顧及的長尾、碎片場景。
舉個例子:
某工廠生產線引入AI質量檢測技術,希望用攝像頭代替肉眼檢測次品。但是如果產線的良品率非常高,那麼只有極少數次品。

我們都知道,一般AI模型在數據不足的情況下,會導致訓練不足,錯誤率高。在這種情況下,AI模型很難達到很難部署到產線上。
過去的做法是開發特定模型用於不同這類特殊碎場景,AI的應用成了專家才能參與的“作坊式”開發。
如果有一個通用AI模型,只需針對不同環境做微調,就能立即適應,便可以擺脱“作坊式”開發的低效率模式。
通用視覺模型“書生”應運而生,它已經在訓練階段“吃進”大量數據成為通才,只需要看到少量樣本,就具備了“舉一反三”的能力。
在自動駕駛、智能製造、智慧城市中還有很多類似的“長尾”場景,它們的共同點都是數據獲取通常困難且昂貴。

通用視覺“書生”為打破了AI在以上場景中應用提供了可能。
而且從實驗結果來看,“書生”的路數也在印證這種方式的正確性。
它能夠同時解決圖像分類、目標檢測、語義分割、深度估計四大任務,而且做到樣樣精通。
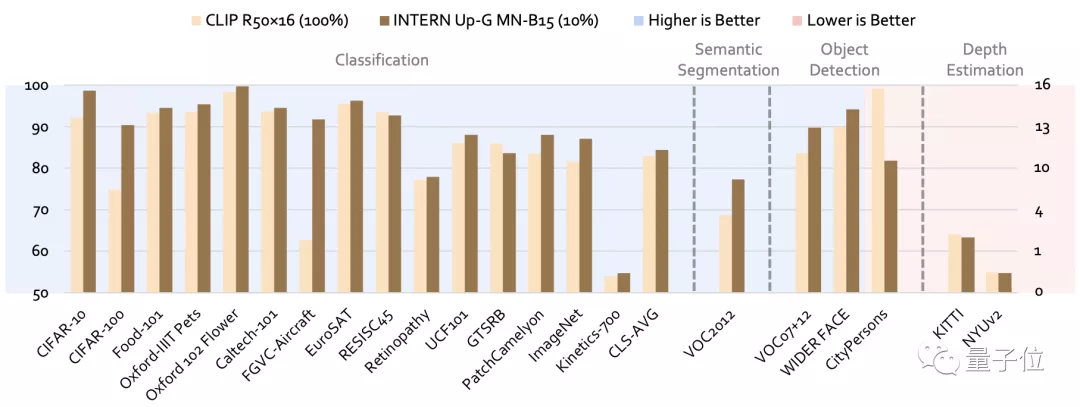
例如與當今最強的開源通用模型CLIP相比,在CV領域的四大任務26個數據集上,“書生”的平均錯誤率分別降低了40.2%、47.3%、34.8%和9.4%。

和CLIP一樣,“書生”也需要強大算力作為支撐, SenseCore商湯AI大裝置恰好派上用場。
今年商湯宣佈在上海臨港的AIDC投入運營,這是目前亞洲最大的人工智能算力中心,僅僅是商湯AI大裝置的一部分。
在商湯CEO徐立看來,AI大裝置是推動機器猜想的一個基礎要素。那麼“書生”則是在此基礎上揹負商湯“猜想”能力的具體實現。
通才“書生”是怎麼煉成的?
整體而言,“書生”這個視覺通用體系包含七大模塊——三個基礎設施模塊和四個訓練階段模塊。
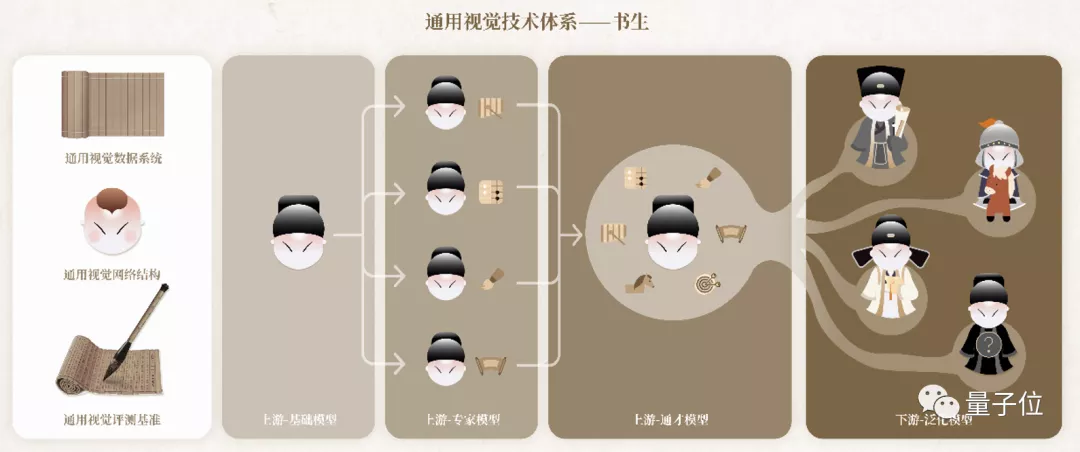
其中,三個基礎設施模塊分別為:
通用視覺數據系統
通用視覺網絡結構
通用視覺評測基準
它們三個就像是“藏經閣”一樣,奠定了在通往通才道路上海量知識和建模等能力的基礎。
例如通用視覺數據系統就包含了一個超大規模視覺數據集,擁有100億個樣本和各種監督信號。
它還提出了一個廣泛的標籤系統,包括11.9萬個視覺概念,可以説是涵蓋了自然界的眾多領域和目前計算機視覺研究中的幾乎所有標籤。
通用視覺網絡結構,則提供了強悍的建模能力。
具體而言,它是由一個具有卷積和Transformer運算符的統一搜索空間構建而成。
通用視覺評測基準就像是一個“擂台”,收集了4種類型共26個下游任務。
在此基礎上,讓“書生”產生的模型和已公佈的預訓練模型同台競技。
並且這個“擂台”還引入了百分比樣本(percentage-shot)的設置,如此一來,下游任務訓練數據被壓縮的同時,還可以很好地保留原始數據集的長尾分佈等屬性。
但也正如剛才提到的,除了基礎設施模塊之外,“書生”還有四個訓練階段模塊。
而這條路徑所採取的是一種階梯式學習的方法。
其中,前三個訓練階段是屬於技術鏈條的上游,主要的發力點是在表徵通用性方面。
它們分別叫做基礎模型(Amateur)、專家模型(Expert)和通才模型(Generalist)。
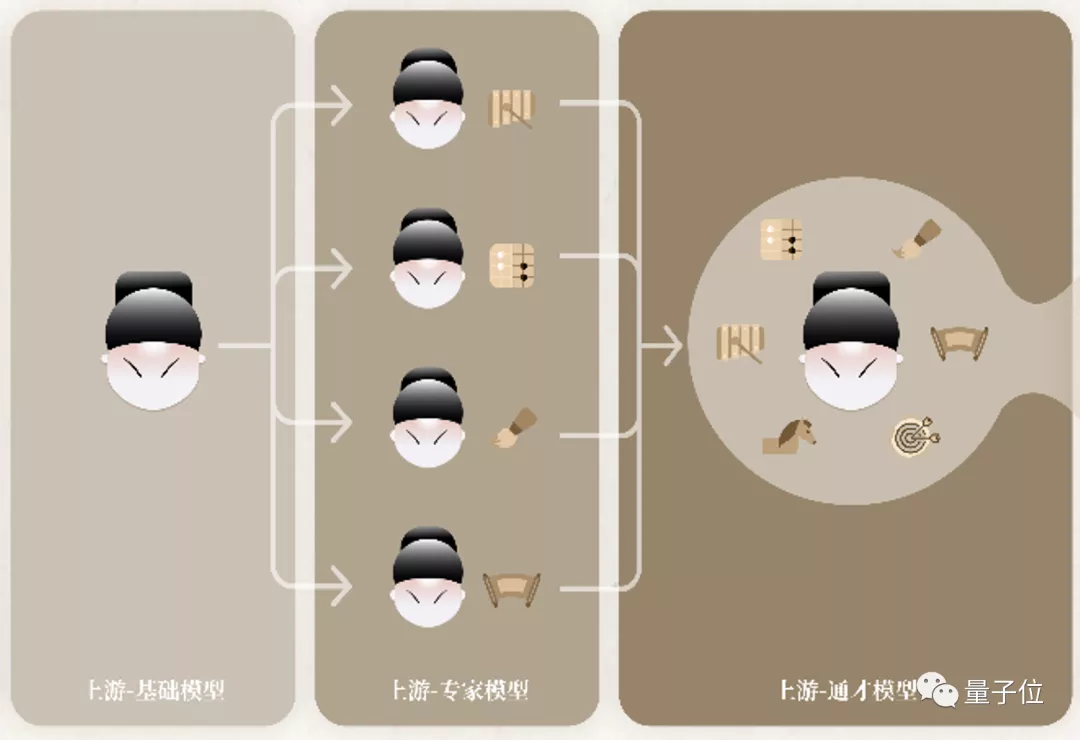
在基礎模型階段,如其名,要做的事情就是讓“書生”打下廣泛且良好的基礎。
具體而言,它是一個獲取基礎模型的多模態預訓練階段,也就是同時使用來自圖像-文本、圖像-圖像和文本-文本對的監督信號來訓練任務,並診斷模型。
而在基礎模型階段“歷練”後得到的輸出,將作為下一階段,即專家模型的初始化輸入。
專家模型要培養的是“書生”的專家能力,也就是讓多個專家模型各自學習某一領域的專業知識。
主要是通過多源監督(multi-source supervisions)的方式,來積累某個類型任務中的專業知識。
值得一提的是,在這個過程中每位專家只關注自己的專業,不干擾“其他人”的學習。
上游的第三個階段,便是通才模型。
它是一個組合式的預訓練階段,這個階段的結果就是產出一個通用模型。
這個模型整合了專家的知識,並生成能夠處理任何已知或未知任務通用表示的最終形式。
在經歷了前三個訓練階段模塊後,便來到了最後的泛化模型 (Adaptation)。
這個階段屬於技術鏈條的下游,用來解決各式各樣不同類型的任務。
而這也是最考驗“書生”舉一反三能力的時刻。
換言之,它需要在這個階段把之前學到的通用知識,融會貫通地應用到特定的不同任務中去。
以上便是“書生”這個通用視覺技術體系完整的一套流程,它的全景如下圖所示:
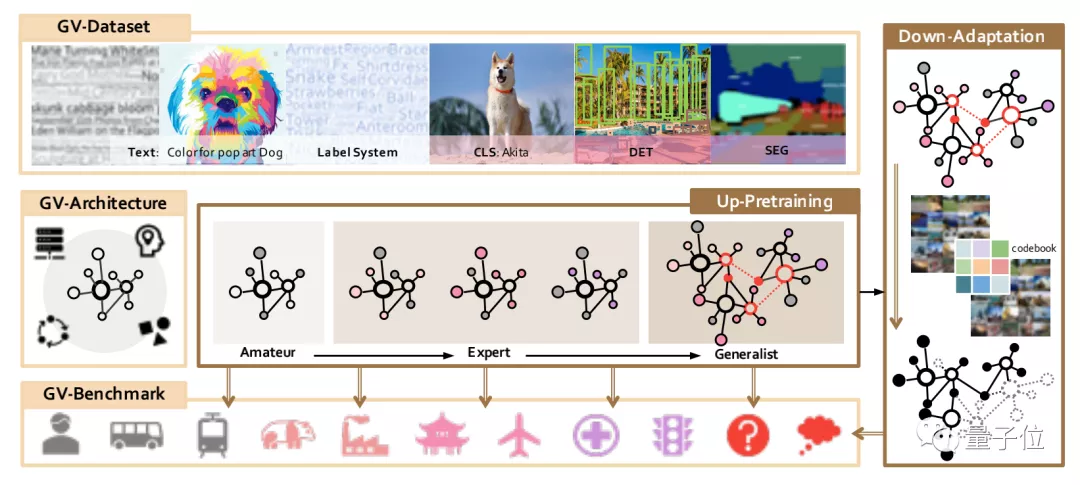
總而言之,在“書生”煉成之後,便是有了一種“兵來將擋”的味道了。
無論是面對智慧城市、智慧醫療、自動駕駛,亦或是未知領域,“書生”都能以專家的實力來迎刃而解。

像“書生”這樣實現以一個模型完成成百上千種任務的新範式,體系化解決人工智能發展中數據、泛化、認知和安全等諸多瓶頸問題。
而這只是“書生”在算法層面上的煉就功法,但對於大模型來説,算力也是非常重要且必要的硬性要求。
這就不得提到商湯早在數月前發佈的SenseCore AI大裝置。
它可以説是商湯引擎的底層架構了,可以類比為整個引擎夯實有力的地基。
具體而言,先從算力角度來看,商湯通過結合AI芯片以及AI傳感器,構建了亞洲最大的人工智能智算中心(AIDC)。
這個AIDC的計算峯值可以達到3740Petaflops (1 petaflop等於每秒1千萬億次浮點運算),相當於一天處理時長達到23600萬年!
除此之外,從平台角度來看,AI大裝置打通了從數據處理、模型生產、模型訓練、高性能推理運算,以及模型部署等等各個環節。
而且不同於其它廠商採用開源工具,商湯這“一整套”都是自研的,具備更強的適配性,更利於模型的部署和應用。
如此一來,在算法、算力、平台“三位一體”之下,便可明顯區別於“小作坊式”的模型打造方式了。
但畢竟常言道學無止境,那麼已經具備如此實力的“書生”,還能通過怎樣的方式來提高自己呢?
“書生”還要加碼開源的力量
從人工智能技術發展的歷史長河來看,多數主流AI工具都具備一個共性——開源。
開源的力量可以説是不言而喻了,越開放、越分享,就會越發讓AI工具具備活力。
而這,也是“書生”要做的一件事情:
基於“書生”的通用視覺開源平台OpenGVLab也將在明年年初正式開源。
更具體的,上海人工智能實驗室聯合商湯要將向學術界和產業界公開的不僅僅是預訓練模型,還包括它的使用範式、數據系統和評測基準等。

但“書生”的開源佈局圖還不止於自身。
OpenGVLab將與上海人工智能實驗室此前發佈的OpenMMLab 、OpenDILab一道,共同構築開源體系OpenXLab。
其背後所要實現的目的,就如商湯所説的,持續推進通用人工智能的技術突破和生態構建。
從涉足領域來看,這個生態裏,應該包括了智慧城市、智慧醫療,也包括了自動駕駛和智能交通……
開源的“書生”,仗劍變革,前景廣闊。
論文地址:
https://arxiv.org/abs/2111.08687