眼見真的為實?技術檢測“AI換臉術”是防範治理基礎
【文/觀察者網 尹哲 編輯/周遠方】
常言道,眼見為實。然而,隨着人工智能的迅猛發展,一些使用Deepfake(深度偽造)技術製作的換臉視頻也在網絡上屢見不鮮,該技術甚至被別有用心的人利用,成為詐騙、誣陷等罪惡勾當的工具,給社會和個人帶來嚴重威脅。
7月9日,在2021WAIC世界人工智能大會上,北京瑞萊智慧科技有限公司(RealAI)發佈DeepReal深度偽造內容檢測平台。

瑞萊智慧副總裁唐家渝在演講中表示:該檢測平台能夠通過研究深度偽造內容和真實內容的表徵差異性辨識、不同生成途徑的深度偽造內容一致性特徵挖掘等問題,快速、精準地對多種格式與質量的圖像進行真偽鑑別,為遏制和防範深度偽造技術的大規模濫用提供技術支撐。
特朗普電視直播曾中招
在接受採訪時,瑞萊智慧副總裁唐家渝向觀察者網指出,深度偽造技術持續進化,網絡數字內容多變、隱匿性強,監管難度大,因此開展主動技術防範與檢測工作是必要的。
所謂“深度偽造”,譯自英語中新出現的一個組合詞Deepfake,是計算機的“深度學習”(Deeplearning)和“偽造”(fake)的組合,出現於人工智能和機器學習技術時代。
眾所周知,在2019年紅極一時的換臉軟件“ZAO”上,用户只需上傳一張照片,就能秒變“戲精”,甚至還能與偶像同台飆戲,效果極其逼真;不久前,短視頻領域出現的“螞蟻呀嘿”熱潮,其基礎也是深度偽造技術。

這種技術被稱作一種合成媒體(syntheticmedia),是通過自動化的手段、特別是使用人工智能的算法技術,進行智能生產,操縱、修改數據,最終實現媒體傳播行為的一種結果。
通俗理解,“深度偽造”就是把圖片和聲音輸入機器學習的算法,從而可以輕易地進行“面部操作”(facemanipulation)——把一個人的臉部輪廓和表情放置在其他任何一個人的臉上,同時利用對聲音的逼真處理,製造出實為合成卻看似極真的視頻——用以躲避識別、混淆視聽、娛樂用户,以及實現其他虛假宣傳的目的。
近年來,非法利用AI技術偽造他人肖像吸引流量牟利,甚至從事侮辱、誹謗、網絡詐騙、色情宣傳等違法犯罪活動的案例已屢見不鮮。
唐家渝以美國前總統特朗普的一次電視直播意外舉例。

在一次福克斯旗下的Q13電視台直播中,特朗普一直做出吐舌頭的動作,之後信號被掐斷。經電視台排查,編輯在直播中利用技術手段播放了偽造視頻,最終涉事編輯被解僱。
2019年初,Facebook的CEO扎克伯格也遭遇被偽造,偽造者發佈了宣揚侵犯個人隱私數據的不實言論,這些事件將Facebook、隨後又將人工智能造假推向了社會輿論的風口浪尖。
此前,常州的王某報警稱自己被裸聊詐騙11萬餘元。他出於好奇,接受了一名女網友請他下載某軟件並提出視頻邀請,掛電話後不久,王某就收到了一段有自己頭像的不雅視頻。騙子用AI換臉技術把他的臉合成到他人的視頻上,並以此威脅其轉賬。

因此,基於深度偽造技術存在的社會風險,2020年5月28日,十三屆全國人大三次會議表決通過《中華人民共和國民法典》中第1019條規定:“任何組織或者個人不得以醜化、污損,或者利用信息技術手段偽造等方式侵害他人的肖像權。未經肖像權人同意,不得製作、使用、公開肖像權人的肖像,但是法律另有規定的除外”。
該法規總體要求了禁止利用信息技術手段偽造的方式侵犯他人的肖像權和聲音。
與此同時,美國、歐盟、德國、新加坡、英國等國也出台了相關的監管政策。
“魔高一尺**”更需“道高一丈****”**
然而,不僅要在法律層面,AI作惡要有“緊箍咒”來約束;在技術層面,“魔高一尺”還要有“道高一丈”來抗衡。

唐家渝向觀察者網指出,隨着人工智能的廣泛應用,整個產業面臨的三大困境逐漸浮現:
**第一是算法可靠問題。**深度學習算法為黑盒,缺乏可理解的決策邏輯和依據,無法量化不同決策的可靠程度,導致難以應用至金融、醫療等高可靠性要求場景;同時,基於對抗樣本攻擊技術可以破解安防監控、手機刷臉解鎖、人臉識別閘機等識別系統,實現身份偽裝或隱身逃逸,為個人財產安全與社會公共安全帶來全新挑戰。
**第二是數據安全問題。**提升AI能力需要挖掘數據價值,但在特定AI應用場景中,所需要用到的數據往往涉及個人隱私信息,簡單明文數據傳輸和利用很可能導致隱私泄露;而有價值的數據分散形成數據孤島,在打破數據孤島的過程中,數據用途和用量難以控制,存在被濫用和複製的可能,同時數據權屬不明確,數據收益不清晰。
**第三是應用可控問題。**AI算法偏差導致不公平性問題,比如人臉識別算法存在種族歧視與性別歧視,AI信貸模型對特定地域人羣的歧視等,缺乏有效衡量算法公平性的方法和工具;同時,AI技術的濫用引發道德倫理問題,比如深度偽造技術的濫用帶來的個人和社會風險問題。

另外,深度偽造技術檢測工作當前面臨兩大難點:
一是造假算法在不斷豐富,偽造圖像越發逼真。
最初的偽造視頻其實是有一些反常識的特徵的,比如一段1分鐘的視頻中,人沒有眨一次眼睛,於是我們可以基於人體的生理特徵去對人物的真假進行判定;但是自然而然地,造假者隨後也通過在視頻中隨機生成眨眼動作,很大程度上逃避了這種檢測方式。
另外,深度偽造的視頻人物,為了與背景有比較好的融合,會對邊緣進行簡單的高斯模糊處理,而當檢測算法基於這樣的特徵進行檢測以後,偽造算法也對人臉邊緣做了更精細化的處理。
二是利用深度學習的缺陷繞過檢測算法。
通過在圖片上添加對抗樣本噪音,可能使得偽造視頻躲避自動檢測。
他坦言:“正是由於深度偽造治理有着巨大的挑戰,勢必需要有着深厚技術實力和AI對抗經驗的團隊,才能做出真正能落地的解決方案。”
據他介紹,DeepReal深度偽造檢測平台算法基於大數據量進行訓練和測試,截至目前,數據量已達到千萬級,數據集已覆蓋三大類,包括:學術深偽數據集、網絡深偽數據集和自研深偽數據集。

同時,通過結合貝葉斯學習框架和深度神經網絡,來估計模型在預測新樣本時的不確定性。以上,有效保障了DeepReal深偽檢測算法的泛化能力。
在測試結果方面,DeepReal在學術數據集和ZAO等主流方式生成的網絡數據集中,已達到99%以上的準確率;在實際應用中,DeepReal的檢測準確率也已達到業界頂尖水平,遠超Facebook此前舉辦的Deepfake檢測挑戰賽所公佈的最好成績。
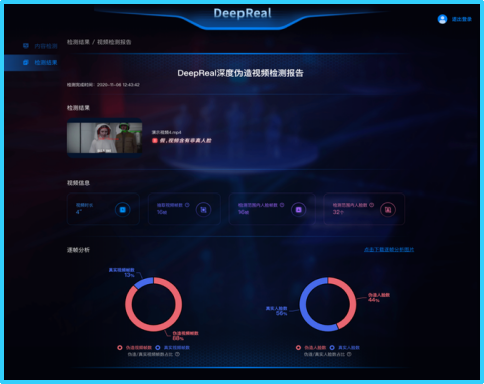
DeepReal深度偽造內容檢測平台檢測報告示意圖
他補充道:該平台對於單張圖像的檢測耗時不到30毫秒,支持橫向擴展與集羣部署,適用於大規模實網落地。針對互聯網環境中眾多的深度偽造類型,平台也進行了全面的覆蓋。包括針對真實人物的面部替換、表情操縱,以及完全合成的虛假人物等。
同時,實網環境中的偽造視頻不斷變化,需要有強對抗的手段加以遏制。
他介紹道,一是使結果具有可解釋性,這樣才能真正讓人信服AI的檢測結果是可靠的:“利用貝葉斯深度學習,我們將偽造視頻的先驗知識進行融合,同時能夠輸出更加準確的置信度,以此增加對預測結果確定性的預判;結合精細化的具有可解釋性的數據集的標註和構建,能夠使預測結果的確定性和可解釋性都有很大提升”。
另外,要能夠快速即時應對新型的深度偽造類型。除了貝葉斯深度學習,還利用了小樣本增量學習的方法,使得在初期見到少量新型偽造數據時,便能迅速學習到偽造特徵。
他指出:“我們對深度偽造的治理進行了全面的技術佈局。比如實戰環境中有音視頻數據,所以我們會利用多模態分析算法綜合分析;對抗環境中使用對抗學習技術,在部署環境中支持多模型和單模型,同時通過不確定量化和配合溯源技術提升可靠性。”
同時,為了進一步提升檢測的可靠性,我們不僅做預測,更佈局了溯源技術,進一步對深度偽造視頻進行具有可解釋性、可靠的綜合治理。
“雖然成績頗豐,但我們清醒地認識到針對深度偽造的風險,一定是需要從監管到研究再到落地實戰進行全方位的治理。”最後,他呼籲:“我們積極與監管部門、科研機構、實戰部門等進行合作,共建深度偽造治理生態。我也代表我們團隊,誠摯邀請和歡迎社會各界機構和企業的加入。”
本文系觀察者網獨家稿件,未經授權,不得轉載。