百度TextMind跨模態文檔模型ERNIE-Layout刷新4項任務紀錄
*【環球網科技綜合報道】*近日,百度提出跨模態文檔理解模型ERNIE-Layout,首次將佈局知識增強技術融入跨模態文檔預訓練,在4項文檔理解任務上刷新了記錄。
據瞭解,對多模態文檔(如文檔圖片、PDF文件、掃描件等)的深度理解和分析,是文檔智能的核心能力。文檔智能應用行業包括金融、保險、能源、物流、醫療等,常見的應用場景包括財務報銷、招聘簡歷、企業財報、合同文書、動產登記證、法律判決書、物流單據等。針對不同行業和應用場景的需求,文檔智能的技術方向囊括文檔抽取、文檔解析、文檔比對等。
文檔視覺問答DocVQA是跨模態的文檔抽取任務,要求文檔智能模型在文檔中抽取能夠回答文檔相關問題的答案,需要模型在抽取和理解文檔中文本信息的同時,還能充分利用文檔的佈局、字體、顏色等視覺信息,這比單一模態的信息抽取任務更具挑戰性。
正是由於文檔視覺問答任務需要結合視覺解析、佈局分析、語義理解、信息抽取等一系列AI技術,是綜合AI能力的集大成者,其技術挑戰與實用價值正得到越來越多的重視。
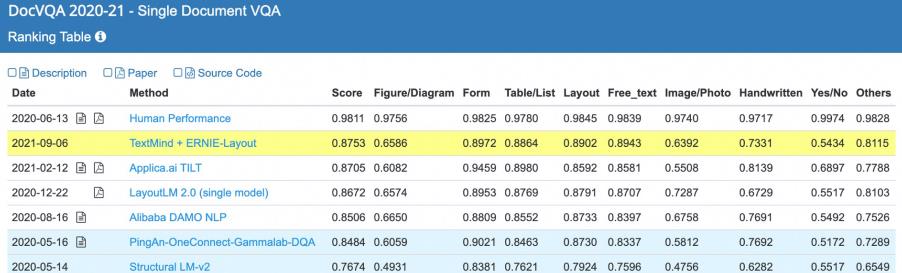
ERNIE-Layout以世界領先的語義理解模型ERNIE為底座,創新提出佈局知識增強技術,對文本、圖像、佈局等信息進行聯合建模,創新了該任務的世界記錄,縮小了機器在文檔理解能力上與人類的差距。
對文檔理解來説,文檔中的文字閲讀順序至關重要,目前主流的基於OCR(Optical Character Recognition,文字識別)技術的模型大多遵循“從左到右、從上到下”的原則,然而對於文檔中分欄、文本圖片表格混雜的複雜佈局,根據OCR結果獲取的閲讀順序多數情況下都是錯誤的,從而導致模型無法準確地進行文檔內容的理解。
據介紹,人類通常會根據文檔結構和佈局進行層次化分塊閲讀,受此啓發,百度研究者提出在文檔預訓模型中對閲讀順序進行校正的佈局知識增強創新思路。TextMind平台上業界領先的文檔解析工具(Document Parser)能夠準確識別文檔中的分塊信息,產出正確的文檔閲讀順序,將閲讀順序信號融合到模型的訓練中,從而增強對佈局信息的有效利用,提升模型對於複雜文檔的理解能力。
基於佈局知識增強技術,同時依託文心ERNIE,百度研究者提出了融合文本、圖像、佈局等信息進行聯合建模的跨模態通用文檔預訓練模型ERNIE-Layout。如下圖所示,ERNIE-Layout創新性地提出了閲讀順序預測和細粒度圖文匹配兩個自監督預訓練任務,有效提升模型在文檔任務上跨模態語義對齊能力和佈局理解能力。