商湯首付56億!上海建成亞洲最大AI“發電廠”,萬億參數大模型訓練無壓力_風聞
量子位-量子位官方账号-2022-01-24 19:36
夢晨 蕭簫 發自 凹非寺
量子位 | 公眾號 QbitAI
剛剛,商湯又多了一項“亞洲第一”。
就在上海臨港,商湯自建的人工智能計算中心(AIDC)交付使用,一舉成為亞洲最大的AI超算中心(至少是之一)。
這也是“亞洲營收第一”,“亞洲AI軟件第一股”之後,商湯開啓的新標籤。
不同的是,這次,很硬。
單從算力來看,商湯AIDC總算力達到3740 Petaflops,相當於每秒進行374億億次浮點運算,374後面16個“0”,可完整訓練萬億參數大模型。
這個規模,放在全國、甚至全亞洲已投產的計算中心裏都是第一梯隊。

在剛剛過去的2021年,各大城市建設AIDC你爭我趕,好不熱鬧。
北上廣深自不必説、南京武漢合肥西安AIDC項目也紛紛上馬。
根據國家工信安全智庫發佈的《新一代人工智能算力基礎設施發展研究》,國內AIDC建設整體思路是政企合作。
建設模式多為政府出資招標、政企合資,承建方也多為傳統IT基礎設施服務商、雲服務商。
商湯AI算法起家,僅一期就自投56億元研發建設一個如此重資產的項目屬實少見,開了國內先例。
這家AI公司的基礎設施建成了什麼樣子?有什麼特別之處?又為何選擇自建?
這一系列問題自商湯AIDC項目自2020年3月首次宣佈以來都是外界好奇所在。
今天藉着正式落成的機會,我們就來一一解答。
耗資56億元打造出大裝置的“基石”
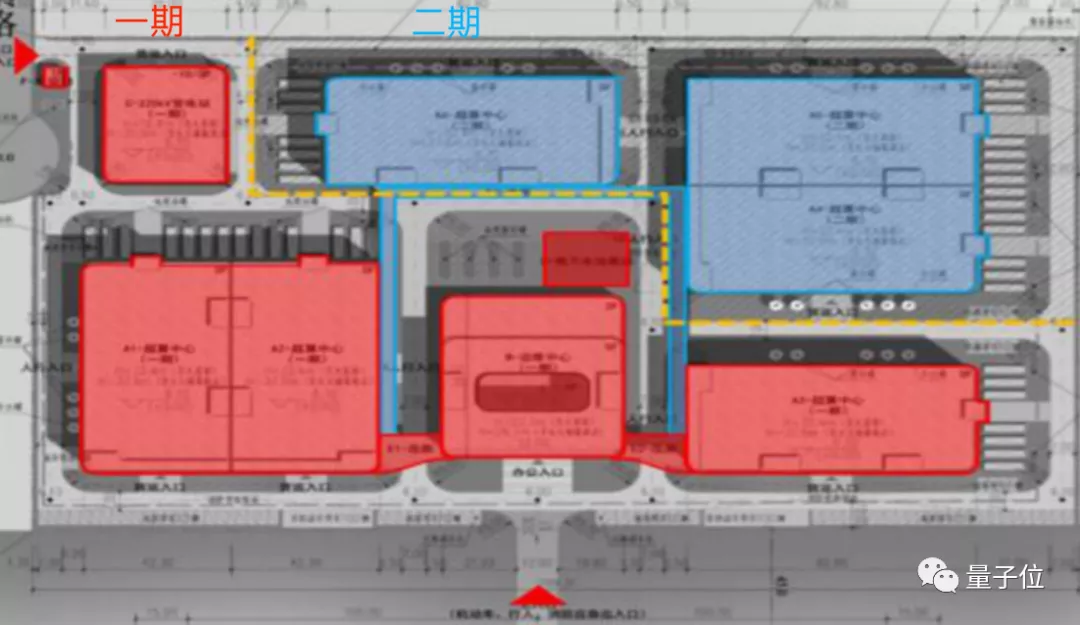
據瞭解,商湯AIDC佔地面積80畝,建築面積13萬平方米,是亞洲最大的超算中心之一。
其中,光是投入運營的一期機櫃數量就達到5000個,國產硬件佔了50%;後續二期“完成體”建成後,算力會比現在的3740P至少翻一番。
作為AI算法和平台的底層基礎設施,商湯AIDC並非僅僅是一個堆疊大量服務器、AI專用處理器、聯網設備等硬件的“物理倉庫”,相反自研了不少技術來提升算力:
高性能計算引擎。這個引擎介於硬件和平台之間,專門用來“壓榨”各種芯片,提升它們的計算能力。結合全圖優化技術,還能將引擎能力延展到AI模型計算、預處理和後處理階段。
分佈式任務調度系統。單一芯片以外,多芯片的協同計算能力同樣重要,商湯的這一系統便是為此研發,目前在已投入使用的集羣中每年調度超過2000萬個任務,進一步降低成本。
除了這兩大硬件技術以外,商湯還針對數據交換(輸入/輸出)、軟硬件協同設計和系統安全進行了設計,在提升模型生產效率、拔高算力的同時,確保用户使用的安全性。

問題來了,一度以AI算法出名的商湯,為何要投入56億元自建一個智算中心?
這就要提到AIDC在商湯版圖中的定位了——它是整個商湯大裝置的“基石”。
商湯大裝置,類似於AI版“發電廠”,包含計算基礎設施、深度學習平台和模型層,能夠像大規模發電一樣,批量化地生產各種AI算法模型(還能部署、迭代和升級)。
AIDC上運行着商湯大裝置中的所有AI算法和平台,此次投入使用,相當於將整個大裝置的能力完全開放了出來,即整個商湯這些年儲備的“AI能力”。
這個能力,本質上是從0到1半自動、自適應化生產AI模型的能力:
一個人無需擁有AI知識,只需要給定模型的輸入和輸出條件(端到端,例如輸入一段話,輸出一幅畫),商湯大裝置就能快速DIY一個AI模型。

因此,AIDC既能獨立作為智算中心、也能作為大裝置的基石運行。
從智算中心角度而言,商湯AIDC最近加入了國家(上海)新型互聯網交換中心,不僅能提供網絡服務,本身也能作為算力雲平台進行使用。
事實上,在AIDC正式對外開放之前,商湯內部就已經在它基礎上,訓練出了不少成功的算法案例。
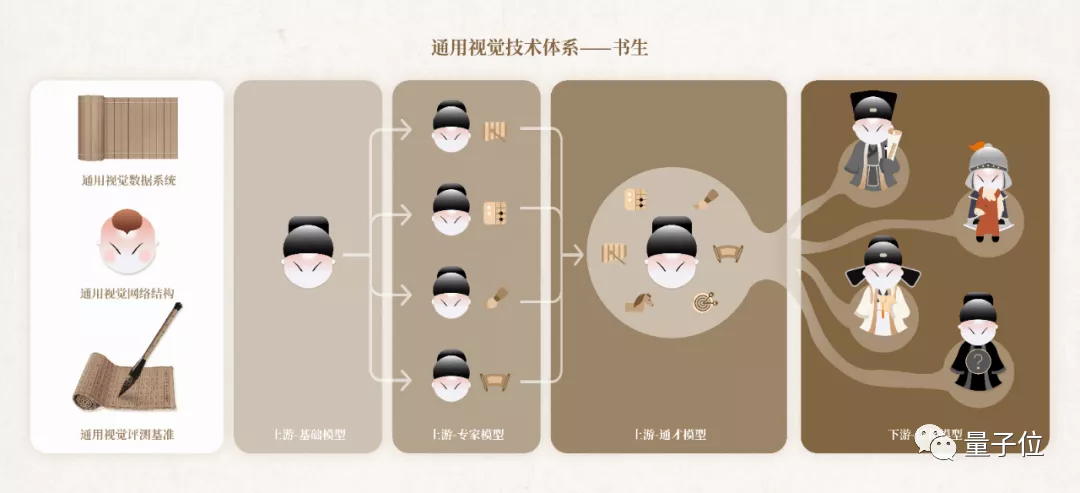
例如,最近剛發佈的“書生”模型(INTERN),覆蓋了分類、目標檢測、語義分割、深度估計四大視覺核心任務,就是在AIDC上訓練出來的。
相較於OpenAI的CLIP,“書生”只需要10%的下游數據,就能超過CLIP基於完整下游數據的任務準確率,很好地hold住了數據量不足的長尾場景、以及通用大模型的需求場景這兩大問題。
而作為大裝置的一部分,商湯AIDC在面對產業、科研和政府的“AI+”需求時,又能很好地作為一個物理平台去生產和運行AI模型。
其中,產業中的大量傳統行業,就能借助大裝置更快地完成數字化轉型;政府則能利用AI進行城市治理、打造智慧鄉村;而針對如今AI for Science場景,像生物方向的蛋白質結構預測、或是理化方向的公式推導等,大裝置同樣能幫助科研機構實現一整套用AI算法完成理論實驗的流程。

當然,這些還都只是從定義上來看,AIDC所能實現的基礎能力。
從商湯角度來説,這一整套自建的AIDC,相對於其他的智算中心究竟有什麼優勢?
“商湯版”AIDC,有何優勢?
主要有五大核心競爭力。
其一,高彈性算力。
作為一年AI頂會發表五十餘篇論文、有“算法工廠”之稱的商湯,從算法角度對於各種模型的硬件訓練和需求有自己的話語權。
小到某一特定任務的算法模型,大到百億參數的通用模型,研究人員都需要在AIDC上運行,這方面的經驗商湯已經積累成了一個算法平台,也因此能讓AIDC的算力在最大程度上被充分利用。
用商湯副總裁楊帆的話來説就是:“我們的AI算法科學家會對硬件算力提出需求,所以知道這個智算中心最好要做成什麼樣子。”

其二,低算力成本。
一方面,商湯通過提升軟件平台的兼容性,來適配各種國產硬件,從而實現成本降低。也就是無論模型在哪個牌子的硬件上訓練或推理,商湯的平台都能兼容,這就使得在供應鏈上能取得話語權,從而降低硬件成本。
另一方面,商湯對於AI數據的存儲進行了一個針對性的設計,相比於過去的結構化數據,商湯自研的存儲系統能針對性地根據特定類型的任務,提速AI數據的存取。
其三,高安全性。
商湯AIDC針對隱私計算做了大量工作,包括沙箱和多方安全計算等,不僅能做到數據的網絡隔離,而且能做到物理隔離。
同時,針對數據使用權進行了一個界定,最大程度上確保客户的數據不被泄露、或是在確保隱私的情況下被合理使用。

其四,低網絡時延。
對於AIDC本身而言,接入國家(上海)新型互聯網交換中心不僅讓訪問時延更低,而且意味着整體網絡服務成本更低,質量更高;
同時,對於大裝置而言,AIDC的集羣網絡設計基於RDMA(高速通信網絡)技術,又能進一步提升模型訓練的速度。
其五,低碳性。
除了性能以外,商湯AIDC的能耗也控制得不錯,PUE做到了1.28,這意味着相對於運行服務器等硬件的能耗,支撐數據中心運行的燈光和空調等費用是非常低的。
具體來説,AIDC功耗比國內其他數據中心低10%,相當於每年都能節省約4500萬度電(一台普通手機使用一年,功耗總量也不到10度電)。
這也使得商湯AIDC雖然不是最早做的,但卻能在行業中站到一個相對領先的位置。

回望過去的計算中心發展史,這大約並不是一個“偶發性事件”。
誕生於AI時代洪流之中
聽上去,AIDC或者叫人工智能計算中心,似乎是一個頗為新鮮的概念。
但其實在它之前,DC(數據中心)、IDC(互聯網數據中心)、甚至是超級計算中心,就已經出現在人們的視野中。
被稱作“人工智能”計算中心的AIDC,究竟為何會在時代的洪流中脱穎而出?
在新一輪深度學習熱潮之前,大數據首先在互聯網行業得到發展。
由此催生的IT基礎設施便是互聯網數據中心 (IDC),若再往前追溯,則是大企業內部的數據中心 (DC)。

從DC到IDC,表面上看只是給數據中心“拉了根網線”,實際上是服務對象的變化、價值的升級。
硬件設施集中在一起,帶來數據存儲和處理能力增強和邊際成本下降,超出企業內部需要的能力後,就可以打包成資源輸出給外部客户。
隨着互聯網行業的崛起、成為過去數年間發展最快的行業之一,行業分工也由此發生細化,出現了專門的數據中心,專門給互聯網廠商提供基礎設施服務。
然而,在IDC中吃了一波時代紅利的人可能沒想到,AI的到來會再度催生出名為AIDC的產物。
隨着AI大模型的出現,算法對算力的要求越來越高,人們對數據中心的要求不再是隻提供基礎設施服務,還希望它能夠更高速地運行各種AI算法,並落地成各種智能應用。

服務對象也不再限於互聯網行業,還擴展到了更多希望通過“AI+”實現轉型的傳統領域。
智慧製造、智慧能源、智慧城市都是近一段時間的突出代表。
靠傳統IT技術沒能做到的產業數字化轉型,終於在AI的作用下成了一股不可阻擋的趨勢。
根據權威諮詢機構國際數據公司(縮寫也是IDC)預測,算力指數平均每提高1個點,數字經濟和GDP將分別增長3.3‰和1.8‰——
AI除了技術的發展,也正在成為拉昇經濟的重要“戰力”。

但除了數據中心以外,領域內已經有很多現成的超算中心,人工智能計算中心的出現,是否並非必然?
事實上,二者仍然有很大不同。超級計算機主要面對尖端科技發展需要,如天氣預測、能源勘探、衞星遙感。
科學和工程計算主要處理結構化的數值數據,對計算精度的要求最高,往往需要使用64位雙精度計算,由CPU提供。
而AI面對的,則是大量文本、圖像、視頻這樣的非結構化數據,對精度要求沒那麼高,對速度和效率更看重,更多靠GPU提供高並行的低精度算力。
AI在訓練階段主要用到32位單精度和16位半精度,在實際應用時的推理階段,則經常只用16位甚至更低精度來保證運行效率。

顯然,從服務對象和技術自身兩方面來看,AI都要求有專門的基礎設施,AIDC本身其實是“洪流之下”的一大趨勢。
然而要説商湯這次在上海建的AIDC全是順應時代所然,仍舊不免讓人產生疑問:
投入成本上,他們選擇承擔自建自投的風險,一出手就是56億元;
建設方案上,他們沒有照搬已有的智算中心“作業”,而是針對人工智能計算的特點對傳統IT基礎設施服務能力做了優化和升級。
這背後有些什麼考量?
帶着這些問題,我們與商湯聯合創始人、副總裁楊帆聊了聊。
他説建設AIDC這事,還要從2018年説起……
“降低重複成本是永遠的追求”
2018年後來被稱為“人工智能商業化落地元年”。
那一年,商湯正處於業務拓展期。
大眾容易感知到的,是AI雙攝、AI美顏落地到OV、小米等各品牌手機上;不容易感知到的,還有智慧園區、智慧城市上更多項目開始起步。
楊帆回憶道,從那時起他們就隱約感到AI需要大算力基礎設施這個趨勢。

這個感覺來自技術研發,也來自產業發展。
技術方面,從ELMo到BERT,預訓練模型的規模越來越大,對更大算力提出要求;產業方面,隨着AI在更多場景落地、滲透到更多領域,產業分工開始細化,規模化的基礎設施會成為需求。
這種變化,在過去很多行業都曾見過,比如大數據中心、雲計算中心。
剛開始,商湯對這個基礎設施的輪廓沒有勾勒得很明確,是在後面的探索中才逐漸清晰。
從互聯網公司、科技數碼產品公司到傳統工廠、物流、園區、政府,AI開始服務於離技術更遠的客户,在這之中,商湯比較看重為客户提供端到端的服務,提供完整解決方案。

楊帆覺得AI開發平台應該像是操作系統,需要主動去對硬件和應用都搞好兼容,硬件基礎設施也不能只是提供一個物理的環境,還要具備提供相應服務的能力:
與IDC的“租地皮”模式不同,AIDC更像“開餐館”模式。
而決定自投自建,則主要有兩方面原因。
一是是商湯看好AIDC未來的前景,希望以“自己吃螃蟹”來表明決心,向外界傳遞明確的信號;
二是作為一個探索性的項目,完全由自己出資有更大的自主決策權。
建設節奏也能把控得更快,2020年3月,商湯與上海臨港簽署合作協議,7月拿地開工,22年初就已經投入使用。
商湯AIDC建成後,對不同類型的客户可以提供不同層次的服務:
最基礎的就是提供算力和AI算法生產工具體系,也就是深度學習平台;對於希望拿到應用級解決方案的用户,商湯可以提供端到端服務;甚至對於有科研需要的客户,商湯“連科學家也可以作為服務的一種,一併提供”。
商湯最不缺的就是科學家。按截至去年6月末的數據,商湯擁有40位教授,250多位博士,3500多位科學家和工程師,研發人員佔比超過三分之二。
研發人員普遍信奉一個格言:
如果一件事需要重複做的次數超過3次,就要創造一個工具來做。
對於科技企業,用工具去提升效率,降低重複性的成本是永遠的追求。
商湯把這個工具的概念放大,就成了AI大裝置。

AI的三大要素,都能在大裝置中得到進化。
**先是數據。**楊帆認為數據作為智能時代最重要的生產要素,與農業時代、工業時代的土地、能源有本質不同。
數據是越用越多的,且可以低成本共享,越多數據放在一起產生的價值是非線性增長。
**再説算力。**提供算力的AI芯片,特別是國產GPU芯片在大裝置中與算法平台和應用得到適配。
建設大裝置所下的大量訂單也能幫助國產GPU形成規模化量產能力,攤薄流片成本,加速國產芯片商業化進程。
**然後是算法。**算法創新的成本正在因算力和工具的發展急劇下降。
商湯研發人員每年人年均生產商用模型的數量,從2019年0.44個,2020年3.45個,2021年上半年到了5.24個,效率提升11.9倍。
在2021年上半年,商湯擁有的總算力是每秒1.17百億億次浮點運算;上海臨港AIDC投產之後,這個數值超過每秒4.91百億億次浮點運算……算法的生產效率還將進一步提高。
AI算法生產的邊際成本降低後,一方面可以降低AI現有服務對象所要付出的成本,另一方面則可以覆蓋更多中長尾客户和場景提供定製化的AI能力。

目前,商湯AIDC已經被上海市經濟和信息化委員會授予“上海人工智能融合賦能中心”稱號。
楊帆透露稱,現在已投產的部分只是第一期,後續還會擴建,以及隨着試運營經驗的積累持續改善節能減排,而在上海之外,對更多有AI產業需求的地區,商湯未來也會逐步去覆蓋。
今天落成的上海臨港AIDC,還只是商湯AI大裝置中基礎設施部分的起點。