存算一體芯片,人工智能時代的潛力股_風聞
果壳硬科技-果壳旗下硬科技内容品牌2022-02-21 14:16
算力與經濟增長緊密相關,算力指數平均每提高1個點,數字經濟和GDP將分別增長3.3‰和1.8‰。目前,城市、交通、能源、金融、零售都開始冠以智慧的稱號,大面積搭載人工智能(AI),這背後是每兩個月就要翻一倍的算力需求[1]。
然而,傳統計算芯片存在瓶頸,算力漸趨飽和,同時在碳中和和可穿戴的背景下,芯片還要保持低功耗特性。有什麼捷徑,能讓芯片獲得成百上千倍的能效比?
看似痴人説夢,但早在上世紀90年代,業界就已提出存算一體的全新芯片架構,可顯著降低延遲和功耗。人腦作為大自然的造物,其實也是存算一體的,這何嘗不是最科學的計算架構。
受限於技術的複雜度、高昂的設計成本和匱乏的應用場景,過去幾十年業界對存算一體芯片的研究進展緩慢,業內也僅存一些小算力存算一體芯片。
隨着AI的爆發,業界迫切需要這項技術來解決算力瓶頸。時至今日,新型存算技術和新型存儲介質都發展到新階段,大算力存算一體芯片已成可能,終端智能電子設備和雲端服務器等領域即將迎來新的一撥商業落地[2]。
付斌丨作者
李拓、劉冬宇丨編輯
果殼硬科技團隊丨策劃

用存算一體越過兩面牆
計算芯片要遵循PPA的設計原則。PPA是Performance、Power、Area的簡稱,即性能、功耗、尺寸,通常計算芯片會根據使用場景平衡三者的分配。
但摩爾定律(Moore’s Law)趨近的極限和馮·諾依曼架構(Von Neumann Architecture)長期固有的缺陷,限制着計算芯片在保持優良的功耗和尺寸上進一步發揮性能,制約了現有計算機技術和算力發展[3]。
摩爾定律正在放緩甚至失效:半個多世紀以來,集成電路一直遵循摩爾定律的技術軌跡發展,定律中指出集成電路芯片上所容納的晶體管數目每隔18~24個月將增加一倍,同時處理器功能和處理速度會翻一番[4]。但在2010年後,晶體管密度增速放緩,逐漸偏離摩爾定律預測的週期。2016年,Nature論文指出,半導體技術發展或將不再以摩爾定律為目標[5];同年,全球半導體技術路線圖(ITRS)史無前例地放棄了以摩爾定律為主導的思路[6];其創造者戈登·摩爾也曾表示摩爾定律是有極限的[7]。現階段,摩爾定律已在物理、功耗、成本三個方面趨近極限[8],並被業界稱為“後摩爾時代”。
馮·諾依曼架構長期擁有缺陷:當前最先進的計算機採用基本都是馮·諾依曼架構,分為運算器、控制器、存儲器、輸入系統、輸出系統五個部分,並遵循二進制和程序順序執行的特性[9]。但這種架構中,數據的處理和存儲卻是分離的。
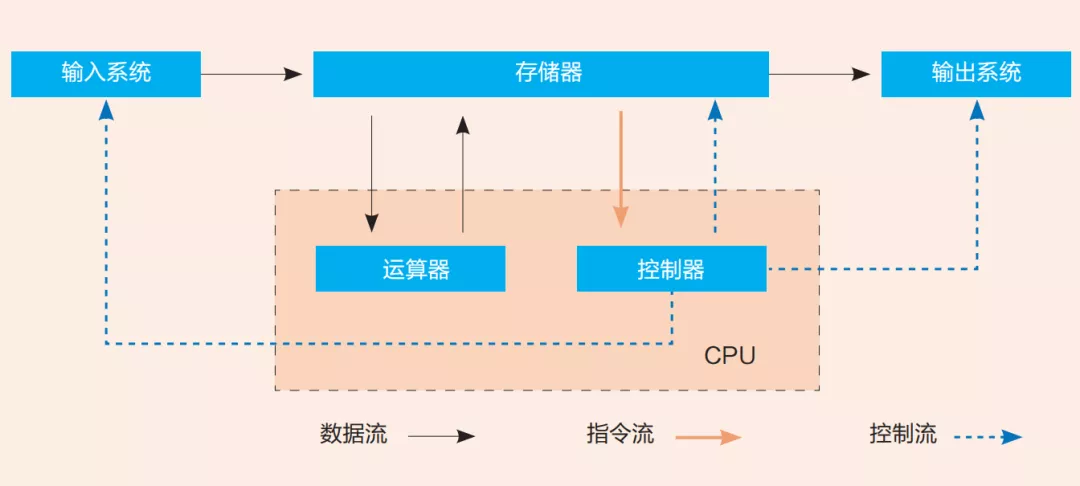
以CPU為例的馮·諾依曼架構示意圖,圖源丨中國教育網絡
摩爾定律和馮·諾依曼架構的現狀會引發存儲****牆與功耗牆兩大問題。
存儲牆:馮·諾依曼架構的存算分離會導致外部存儲器運行速度遠遠小於處理器的運算速度,系統整體會受到傳輸帶寬瓶頸的限制,導致算力會遠低於處理器標定的理論算力[10]。
功耗牆:馮·諾依曼架構中,數據在處理器和外部存儲器中頻繁高速傳遞,會導致系統功耗很高。與此同時,摩爾定律接近瓶頸,芯片特徵尺寸已進入量子效應顯著的範圍,引起一系列次級物理效應,包括柵隧穿泄漏、載流子界面散射、強場速度飽和、源漏寄生電阻佔比增大等,導致功耗密度快速上升[11]。
為什麼人們要死磕這兩堵牆?這是因為只有低功耗基礎上的大算力才可持續。在泛人工智能時代,地球將無法承受今天芯片的能量消耗。後摩智能向筆者展示的一組數據顯示,全球數據中心2025年的耗電量將達到總耗電量20%,而L5級無人駕駛所需的4000 TPOS算力水平,預計一年需要3萬多億度電,將佔全球發電量12%;再比如AlphaGo下棋打敗了人類,但人類只用了20瓦的大腦能耗,而AlphaGo的能耗則達到2萬瓦,如果更多的腦力勞動被機器取代,芯片散發的熱量會讓地球變得滾燙。
面對兩堵牆的挑戰,一種是繼續延續摩爾定律和馮·諾依曼架構,採用類硅模式材料;另一種則是跳出馮·諾依曼架構(non-von Neumann)的思路,採用低電壓亞閾值數字邏輯ASIC、神經模態(Neuromorphics)計算和模擬計算等新興技術,而其中存算一體是最直接高效的一種[12],也是目前能夠最接近落地的技術。

後摩爾時代下芯片架構的進化行徑

存儲的變形記
存算一體是將存儲器和處理器合併為一體,但由於實現形式不同,目前存內計算的概念並沒有非常明確的定義。
阿里達摩院告訴筆者,就目前和未來的趨勢來看,存算一體芯片分為近存儲計算(Processing Near Memory)、內存儲計算(Processing In Memory)、內存執行計算(Processing With Memory)三種技術路線。
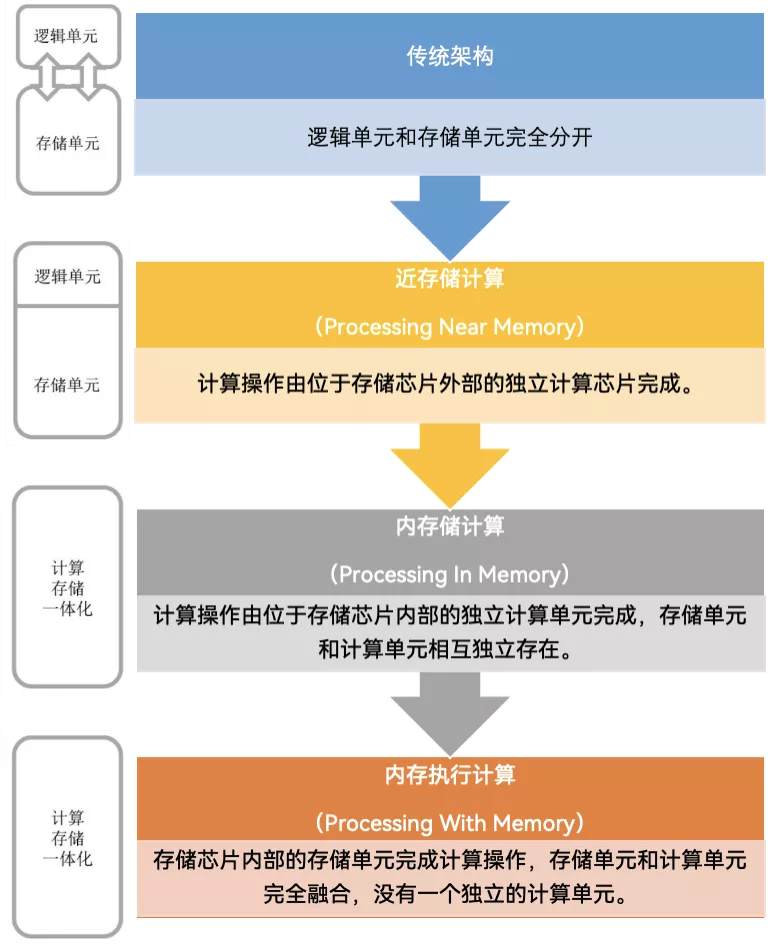
存內計算幾種實現形式,製圖丨果殼硬科技
資料來源丨阿里達摩院,信息通信技術與政策
讓芯片存算一體化擁有兩種方案:其一是將處理器和存儲器放在同一芯片上,以減少數據交換、提升計算效率,但處理器和存儲器的製備工藝不兼容,且芯片中存儲器密度受限,以目前及未來一段時間的技術水平來看,製造這種存算一體芯片的難度較大;其二是基於新型存儲材料和器件,是目前業界積極推進的一種方案[13]。
存儲器有許多種介質,不同介質實現存算一體的關鍵點也不同。從目前的存算一體發展技術路徑來看,處於多種存儲介質百花齊放的格局,包括各種易失性存儲器件和非易失性存儲器件(NVM)。
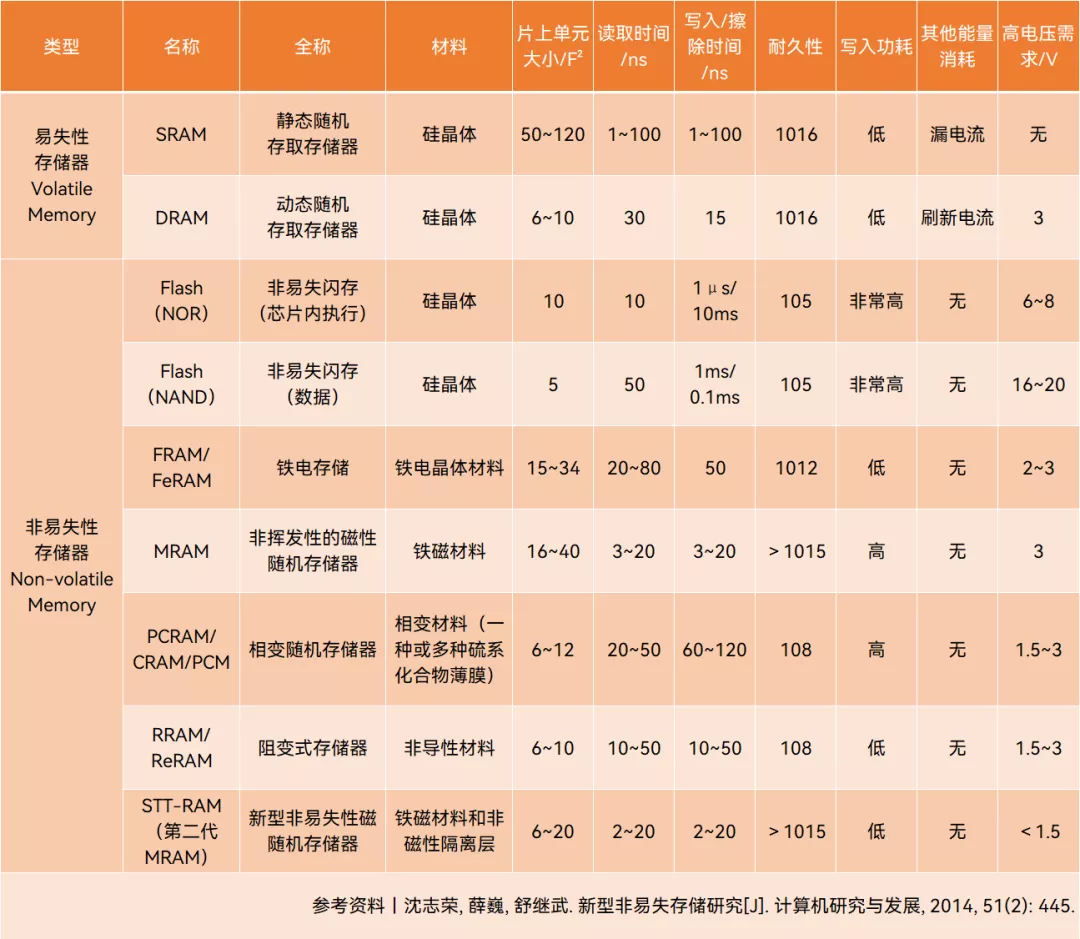
不同介質類型存儲器對比,製表丨果殼硬科技
近期前沿研究更多偏向於技術成熟的SRAM來探索和設計存算一體架構。SRAM方案在現階段具有三點優勢:其一,SRAM是所有存儲類型中最快的,且沒有寫次數限制,對於追求快響應的場景幾乎是必選;其二,SRAM可向先進製程兼容,從而達到更高的能效比和麪效比;其三,相對新型存儲器,SRAM的工藝成熟度較高,可以相對較快地實現技術落地與量產。
但SRAM也有瓶頸,其較大的單元面積會導致隨着工藝發展,CMOS擴展難度會相應增大,芯片計算密度增長會逐漸放緩。
相比之下非易失性存儲(NVM)在計算密度方面表現出更大的潛力[14]。不過,目前NVM尚不成熟,基於該技術設計的存算一體架構短時間很難得到廣泛應用[15]。
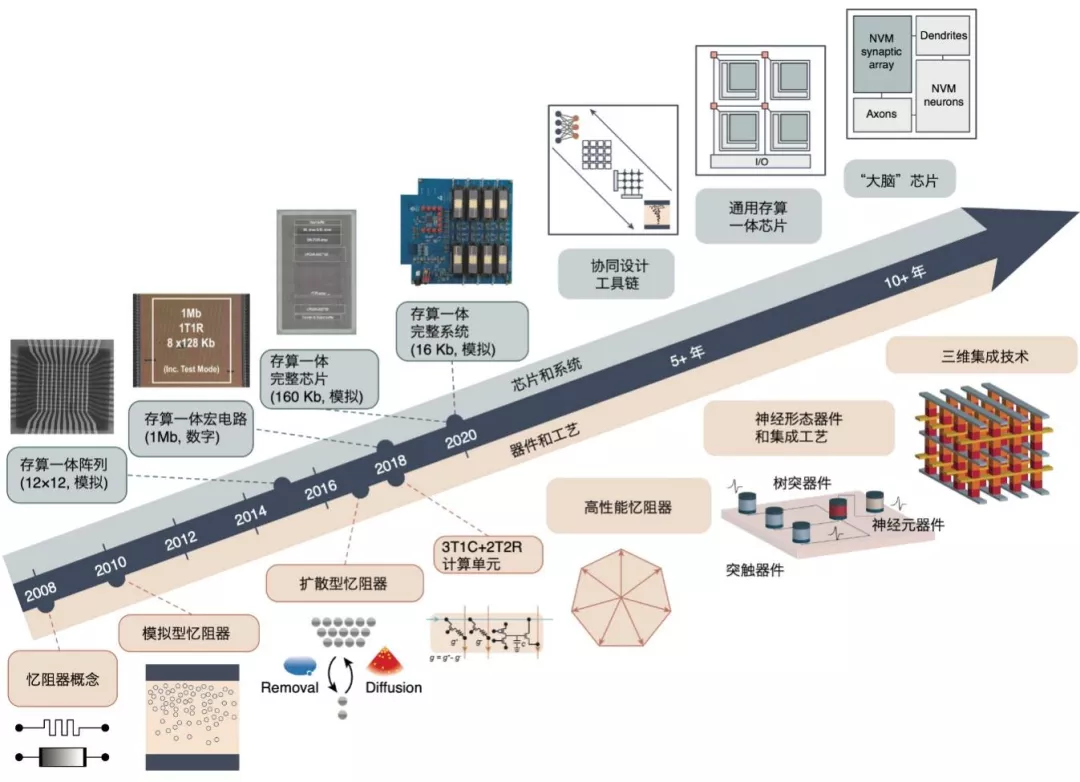
存算一體芯片發展路徑,圖源丨清華大學

以AI為契機的國產市場
近幾年,存算一體在學術界受到的關注度越來越高,如ISSCC 2022就有多篇關於存算一體技術的論文。在市場需求驅動下,存算一體領域正在從學術界向工業界進軍。
國外巨頭早已佈局這一領域,英特爾、三星、IBM、東芝、SK海力士等持續進行相關產品的研發,代表存儲器未來趨勢的磁性存儲器(MRAM)和憶阻器(RRAM)相繼在頭部代工廠傳出量產消息。
目前成果較為明顯的是三星在2021年發佈的HBM2-PIM,其使用的Aquabolt-XL技術是圍繞HBM2 DRAM這種存儲介質進行內存儲計算,可實現高達1.2 TFLOPS的計算能力,從而使內存芯片能夠處理通常需要CPU、GPU、ASIC或FPGA的任務。
國產方面,主要以AI為契機,實現特定領域、特定功能的AI存算一體芯片。現有AI芯片基本也都採用的是馮·諾依曼架構,算力提升有限,同時AI屬於數據密集型計算應用,大量的數據搬運導致功耗居高不下,“芯片大算力和高能效比”是人工智能場景必須解決的剛性需求。
當前大量存算一體芯片公司陸續出現,且大都還在A輪之前,未來存算一體芯片發展還有巨大潛力,有望成為AI時代變革算力格局的源動力。
據果殼硬科技(ID:guokr233)統計,天眼查網站共計40條專利與存算一體相關,以存算一體芯片為目標的企業已超過十家,量產產品以SRAM為主要形式,Nor Flash、RRAM等NVM為主要佈局方向。另外,一些國產企業也正利用2.5D/3D封裝等相關集成技術實現近存儲計算。
後摩智能認為,存算一體這種顛覆性的新興技術才是真正趕超巨頭的機會。“高舉國產替代旗幟的GPGPU賽道,已經聚集了一隻手數不過來的創企。要替代英偉達,起碼要比英偉達的產品性能好5~10倍,只需要1~2倍的改良客户可以等待英偉達下一代產品,沒必要忍受一個新的、沒那麼順手的產品。存算一體是不與業界同質化,且能兼顧高能效與通用性優勢的產品[16]。”
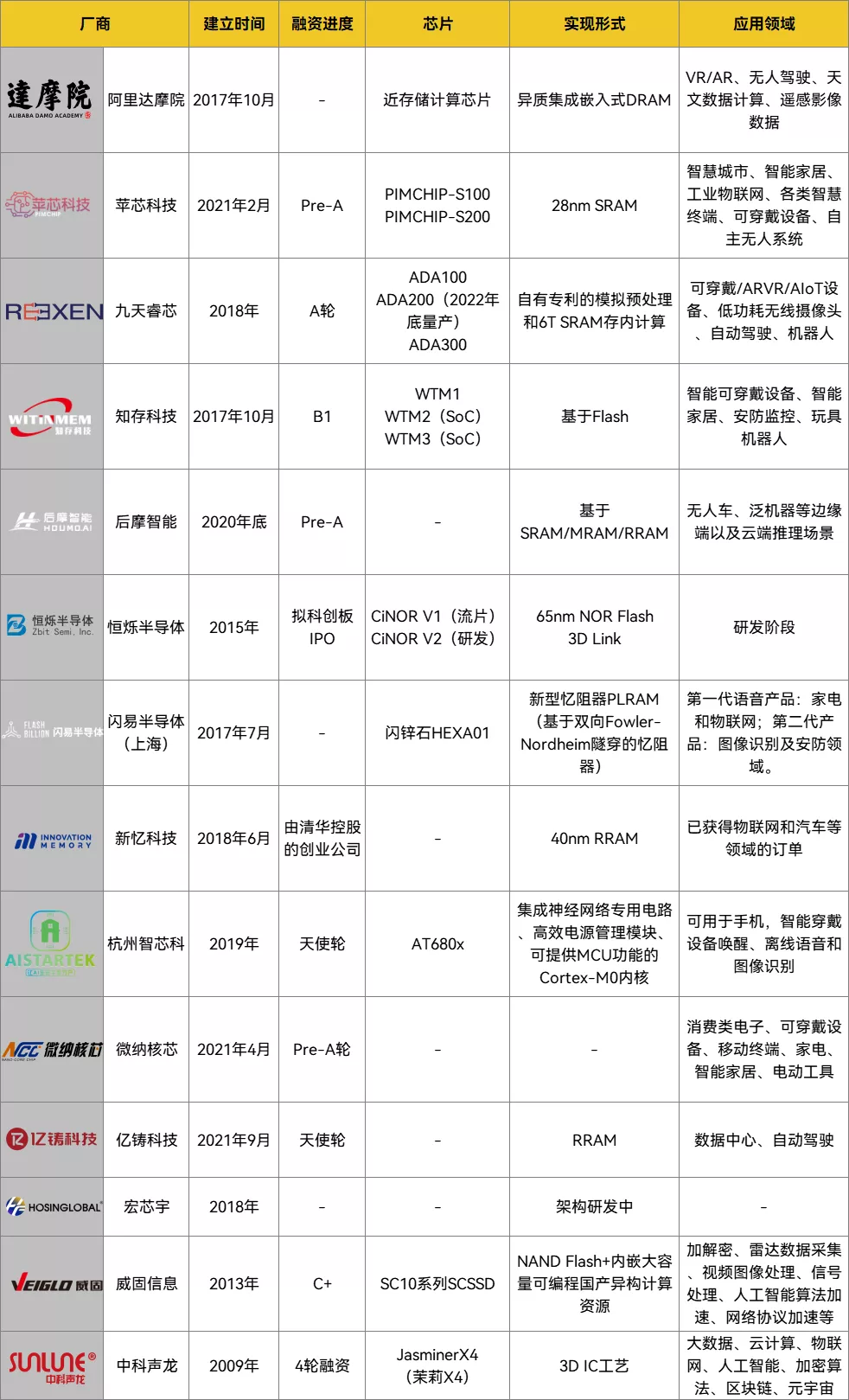
國內主要存算一體芯片企業情況,製表丨果殼硬科技
資料來源丨各公司官網、公告、新聞
筆者探問了阿里達摩院、九天睿芯、蘋芯科技、後摩智能四傢俱有代表性的存算一體企業,展現了國產企業在存算一體上的不同理解。
阿里達摩院
阿里達摩院向筆者表示,其佈局的方向是與現有計算芯片架構設計最為接近的近存儲計算方案,通過在內存單元採用異質集成嵌入式DRAM,將計算資源和存儲資源距離拉近。在此技術路線上,阿里達摩院採用了基於混合鍵合(Hybrid Bonding)的3D堆疊技術進行芯片封裝,將計算芯片和存儲芯片face-to-face用特定金屬材質和工藝進行互聯。比起業內常見的封裝方案HBM,混合鍵合3D堆疊技術擁有高帶寬、低成本等特點,被認為是低功耗近存計算的完美載體之一。此外,阿里達摩院還研發設計了定製化的流式加速器架構,對推薦系統進行“端到端”的加速,包括匹配、粗排序、神經網絡計算、細排序等任務。這種近存架構也有效解決了帶寬受限的問題。經AI搜索推薦場景測試驗證,達摩院存算一體芯片性能提升達10倍以上,能效比提升高達300倍。
九天睿芯
九天睿芯擁有自有專利的模擬預處理與6T SRAM存算一體技術,解決了傳統計算架構的瓶頸和耗電散熱難題,做到更低的延遲和更快的處理速度。之所以選取6T SRAM,是因為低功耗模擬前處理可以做更高層次有效信息提取,並且6T SRAM擁有數值與物理運算一一對應、電荷域運算計算數值精度高、較小面積的外圍電路、受PVT影響小、遷移到先進工藝節點容易、沒有讀寫次數限制的優勢。
使用上述技術的產品包括語音芯片、視覺芯片和高性能ADC,主要面向國內外自動駕駛、AR/VR/XR、智能物聯網和可穿戴市場。對於輕量級的應用領域,還會提供完整的芯片級解決方案。產品優勢包括:一、採用自主專利授權的主流CMOS存算技術,用成熟製程即可實現與傳統數字芯片在先進製程工藝下達成的同樣的性能;二、可同時支持CNN、Transformer及以SNN代表的類神經元計算架構;三、架構靈活,陣列化計算效率不衰減。
蘋芯科技
“目前蘋芯選擇了SRAM技術路線,未來將推進基於eNVM新型存儲器的計算技術。”蘋芯科技向筆者表示,選擇這種技術路線的出發點在於工藝成熟度、加入計算功能的複雜度和結果精度、向上對神經網絡算法要求的支持程度、落地成本等方面。
蘋芯已開發實現多款基於SRAM的存內計算加速單元並已完成流片,目前處於外部測試和demo階段,同時正與智慧穿戴、圖像物體識別領域的頭部客户做技術驗證。而在研發中的基於eNVM(嵌入式非易失存儲器)的新型存儲器產品,可提供更高效的存儲密度、讀寫速度和計算效率。另外,蘋芯科技還提供以存算一體為基礎的超高性能的通用型AI加速計算單元,並以此技術核心搭建面向不同級別應用場景的智能感知決策平台,依靠性能指標數量級的提升和實際成本的降低為AI系統的落地實際賦能。
後摩智能
後摩智能採用CIM(Computing In Memory)-SRAM/MRAM/RRAM等先進的存算一體技術和存儲工藝,實現芯片的大算力和高能效。
2021年8月,後摩智能完成了基於存算一體的核心技術驗證流片,是國內首家用存算一體技術實現數百Tops大算力的AI芯片公司。其高算力、低功耗芯片及解決方案可應用於無人車、泛機器人等邊緣端,以及雲端推薦、圖像分析等雲端推理場景。
後摩智能存算一體技術擁有三個核心優勢。一、大算力:非馮·諾伊曼架構的存算一體架構中,計算單元和存儲單元完全融合,提升算力只需要複製“存算一體單元”,工程上更簡潔,性能上更強力;二、高能效:存算一體在存儲單元內完成運算,有效的解決了困擾業界許久的“存儲牆”問題,減少數據搬運過程中高達90%的功耗消費,提升計算能效比;三、更安全:存算一體減少了數據遷移和計算單元無效的等待時間,降低了延時,在自動駕駛賽道,低延時可能意味着挽回生命。

超前技術是難啃的硬骨頭
“當然,要讓技術實現真正的規模化落地仍然有很多難題需要攻克,至今業界都沒有一家企業和機構的技術解決方案得到市場的廣泛認可。”阿里達摩院如是説。
難攬的瓷器活
存算一體技術較傳統計算加速單元具有顛覆性的性能優勢,其技術本身是一門非常複雜的、技術壁壘極高的設計方法學,屬於需要多年經驗積累、大量資源以及時間投入才能實現的尖端領域。
拿內存儲計算和內存執行計算來説,面臨着諸多挑戰,例如:外圍電路(數模AD/DA轉換電路等)的面積和功耗開銷,存儲單元有限的數值精度,存儲單元的失效,計算單元和存儲單元的工藝集成等難題。
另外,提升存算一體單元的面效比和能效比和高能效計算如何有效控制存內計算接口,都是重要的挑戰。
誰擁有兼顧計算密度與存儲密度的存內計算硬件架構,誰就擁有了打開高能效計算的金鑰匙,但顯然能攬下這種活並不容易。
沒有外援的戰鬥
實際上,存算一體芯片產業化尚處於起步階段,會面臨產業鏈上游支撐不足,下游應用不匹配的諸多困局。例如,在芯片設計階段,由於存算一體芯片區別於常規芯片設計方案,所以目前市面上沒有成熟的專用EDA工具輔助設計和仿真驗證;芯片流片之後,也沒有成熟的工具協助測試;在芯片落地應用階段,暫時沒有專用的軟件與之匹配[17]。
九天睿芯向筆者指出,軟件編譯器要適配架構完全不同的存算一體,如果編譯器做得足夠好,可以反過來指導網絡模型設計。
蘋芯科技向筆者分析,存算一體硬件的出現,本身在催生一種編程觀念上的革命,也就不能再套用傳統的功能分離的思維去理解。從功能上來説,存內計算既可以存儲數據,又可以做特定的計算,本身並不矛盾。從可編程的角度講,面向AI的存算一體技術的出現將會很大程度上影響人們如何去編寫軟件,或者説為更有效率的去編寫軟件提供了一個非常好的基礎平台和機會。
阿里達摩院表示,目前存算一體芯片大多是解決特定領域、特定問題的專用芯片,軟件上是需要給原本應用程序提供存算一體芯片API的,需要一定程度的軟件修改和適配的工作。隨着存算一體芯片涵蓋的應用領域不斷拓廣,通用性的處理能力有望引入存算一體芯片,而對於用户軟件的影響和修改會進一步縮小甚至消失。雖然現階段在存算一體的設計中還沒有看到軟件在運行時配置硬件的範例,但不排除將來會有類似的方案出現的可能,打破軟件和硬件之間的壁壘,提供一定程度的硬件可編程性。
活在千里眼裏的生意
雖然存算一體的未來是光明的,但超前技術仍然較難導入市場。“至今業界都沒有一家企業和機構的技術解決方案得到市場的廣泛認可。我們認為,存算一體芯片規模化落地還需要3~5年的時間。”阿里達摩院這樣向筆者解答。
行業人士指出,存內計算適合原本就對存儲需求較大的場景,這是因為隨着容量的增加,成本往往呈指數級增長,性價比不理想導致內存計算無法惠及更多用户、更多場景。而對於本身存儲需求並不高的場景,為了引入內存計算而加上一塊大內存反倒會適得其反地增加成本。
蘋芯科技分析,存算一體中早期產品將更多出現在端側對低功耗和高能效有強烈需求的場景。“隨着智能城市、智能生態等應用的普及,我們預測從邊緣端接入的智能設備的市場體量將快速增長,應用場景的多樣性也將不斷快速拓展。長遠地看,存算產品的適用範圍也可能會延伸至超大算力領域。”
References:
[1] 浪潮官網:IDC發佈全球AI服務器市場數據,浪潮排名全球第一.2021.3.26.https://www.inspur.com/lcjtww/445068/445237/2551384/index.html
[2] 清華大學官網:清華大學微納電子系在《自然·電子》發表存算一體芯片研究綜述.2020.8.11.https://www.tsinghua.edu.cn/info/1175/21347.htm
[3] 李雅琪,温曉君.存算一體化的發展現狀與挑戰[J].機器人產業,2020,(01):28-31.
[4] Moore, G.E. ,“Cramming More Components onto Integrated Circuits”. Electronics.1965,38(8): pp.114-117.
[5] Waldrop, M. M., “The Chips are Down for Moore’s Law.” Nature.2016, 530(7589): pp.144.
[6] “What Is the IRDS”. IEEE.2021, https: / / irds.ieee.org / .
[7] 紀磊. 摩爾定律的困難與前景——從摩爾第二定律談起[J]. 科技導報, 2006, 24(0607): 89-92.
[8] 戚聿東, 徐凱歌. 後摩爾時代數字經濟的創新方向[J]. 北京大學學報 (哲學社會科學版), 2021, 58(6): 138-146.
[9] 致敬計算機之父——馮·諾依曼[J].中國教育網絡,2017,(Z1):38-39.
[10] 恆爍半導體(合肥)股份有限公司:首次公開發行股票招股説明書(申報稿).2021.10.19.https://data.eastmoney.com/notices/detail/A21521/AN202110191523750446.html
[11] 高雅麗,李晨,王之康. 解決重大原創問題 勇闖創新“無人區”[N]. 中國科學報,2021-06-01(004).DOI:10.28514/n.cnki.nkxsb.2021.001764.
[12] 許居衍、黃安君:《後摩爾時代的技術創新》,《電子與封裝》2020 年第 12 期,第 3—6 頁。
[13] 樊貞. 讓拓撲相變存儲數據[J]. 物理學進展, 2020, 40(3): 84.
[14] Zhang, W., Gao, B., Tang, J. et al. Neuro-inspired computing chips. Nat Electron 3, 371–382 (2020). https://doi.org/10.1038/s41928-020-0435-7
[15] 曾劍敏, 張章, 虞志益, 等. 基於 SRAM 的通用存算一體架構平台在物聯網中的應用[J]. 電 子 與 信 息 學 報, 2021, 43: 6.
[16] 後摩智能官網:對話後摩智能CEO吳強:用存算一體解鎖大算力芯片,不復制別人走過的路.2021.11.15.https://www.houmo.ai/newsdetail.php?id=8
[17] 李雅琪,温曉君.存算一體化的發展現狀與挑戰[J].機器人產業,2020,(01):28-31.