漫畫:大數據的社交牛逼症是怎麼得的?_風聞
谭婧在充电-谭婧在充电官方账号-偏爱人工智能(数据、算法、算力、场景)。-2022-03-16 13:32
圖文原創:譚婧
指導專家:魯蔚徵


用户在APP裏不是靜止的,買買,逛逛,點點,劃劃就會產生海量行為數據。
很多人可能不知道,手機APP裏有很多“埋點”。

你在手機APP裏的動作,會觸發“埋點”。

後台大數據系統悄咪咪地記錄下來。理解成“埋雷”也説得通
那麼問題來了,埋雷,不是,埋點的密度有多大?
這是每家互聯網公司的商業秘密很難知道。
但是,埋點越密集,越多,你在手機APP裏的一舉一動,就越會被詳細記錄。
有了這些記錄,大數據系統就得了社交牛逼症。
每天,只要你打開互聯網公司的手機APP,就在和大數據系統“打交道”。
比如,週五的晚上,我點開看了體育新聞,左滑,右滑,上翻,下滑,閲讀了新聞,點贊,評論,這些行為,產生了使用記錄。
大家的行為,都記在“超大表格”裏。
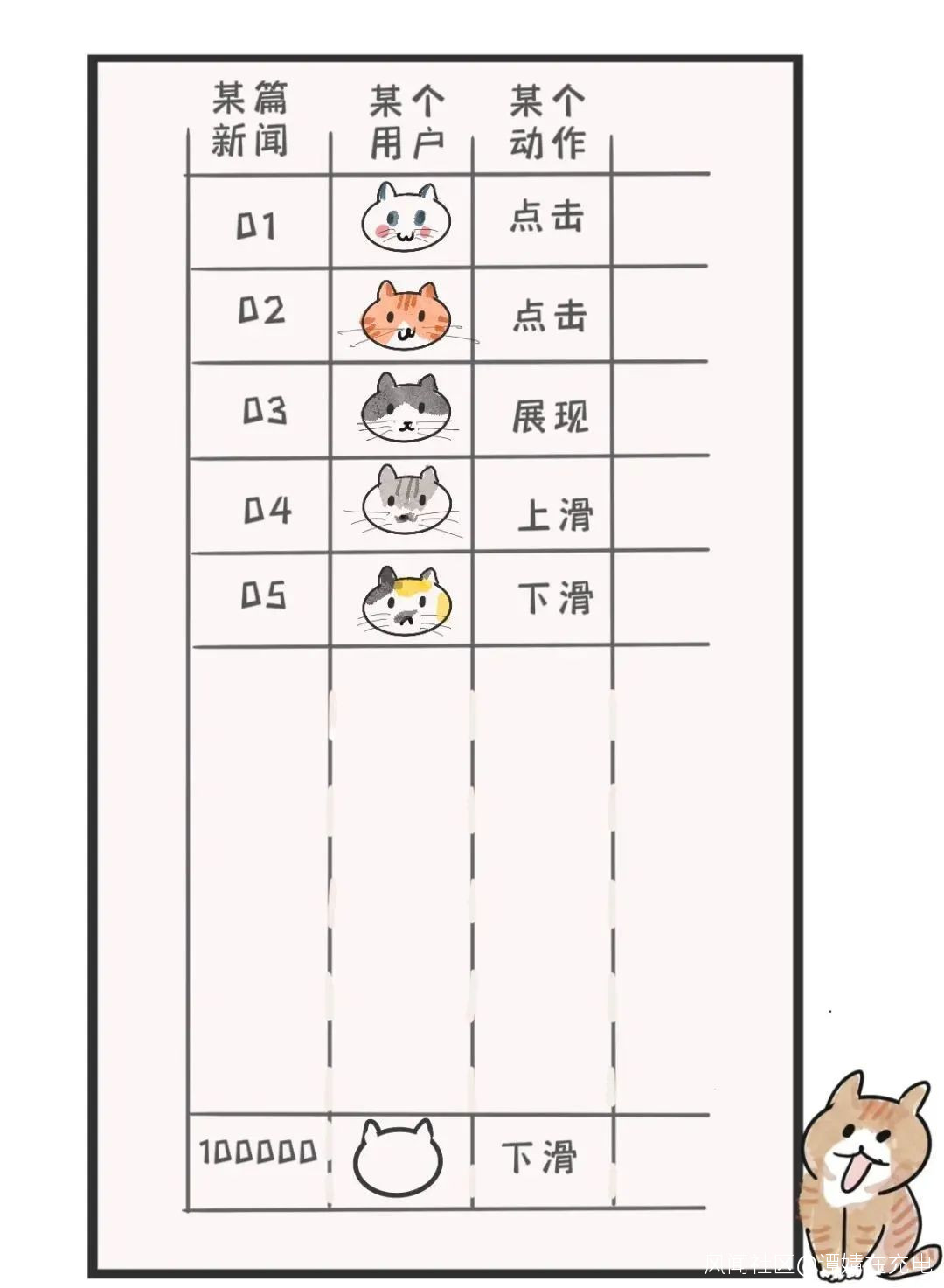
這個超大表格有多大?
假設一個國民級的APP,2億日活。
好比2億人,每天等電梯的時候,隨手玩一小會某短視頻APP。
所產生的表格,大約將會有400T大小。
400T有多大?
一部電影大約4G,那這個表格的大小等同於存下10萬部電影的大小。
一個Word文檔4M,就是1億個Word文件。
再假設2億人,睡前刷了一小時短視頻APP,超大表格會有多大?
一小時產生5萬行表格,再X2億等於一張10萬億行的表格。

這個量級用excel肯定是處理不了的。

這張“用户行為表”只是其中之一而已。

之後,這些記錄去哪裏了?
手機產生的用户行為記錄,也就是“超大表”裏一行一行的數據,通過網絡不斷流入數據中心,進入數據中心的服務器集羣。
數據中心的服務器集羣裏有什麼?
安裝了一個卡夫卡(Kafka)系統。
對,就是小説家卡夫卡。
卡夫卡的作者們認為,數據日夜不停“寫入”存儲,像一位作家,於是,致敬自己喜歡的作家,以其名字來命名。

“卡夫卡”是一種大數據領域的開源消息隊列框架(一種接收消息併發送消息的技術,功能之一是把數據寫入持久化存儲裏)。

消息隊列,顧名思義,很多消息在排隊。
“超大表格”經過“卡夫卡”,寫入Hadoop分佈式文件系統(HDFS)裏。
如果是一台服務器壞了,很有可能是多個文件包部分受損。
但是,HDFS“狡兔三窟”(有3份冗餘,一個文件寫了三份)。
公有云計算廠商提供的大數據系統服務很多,比如一鍵創建HDFS。
數據彷彿一條河流,簡稱數據流。
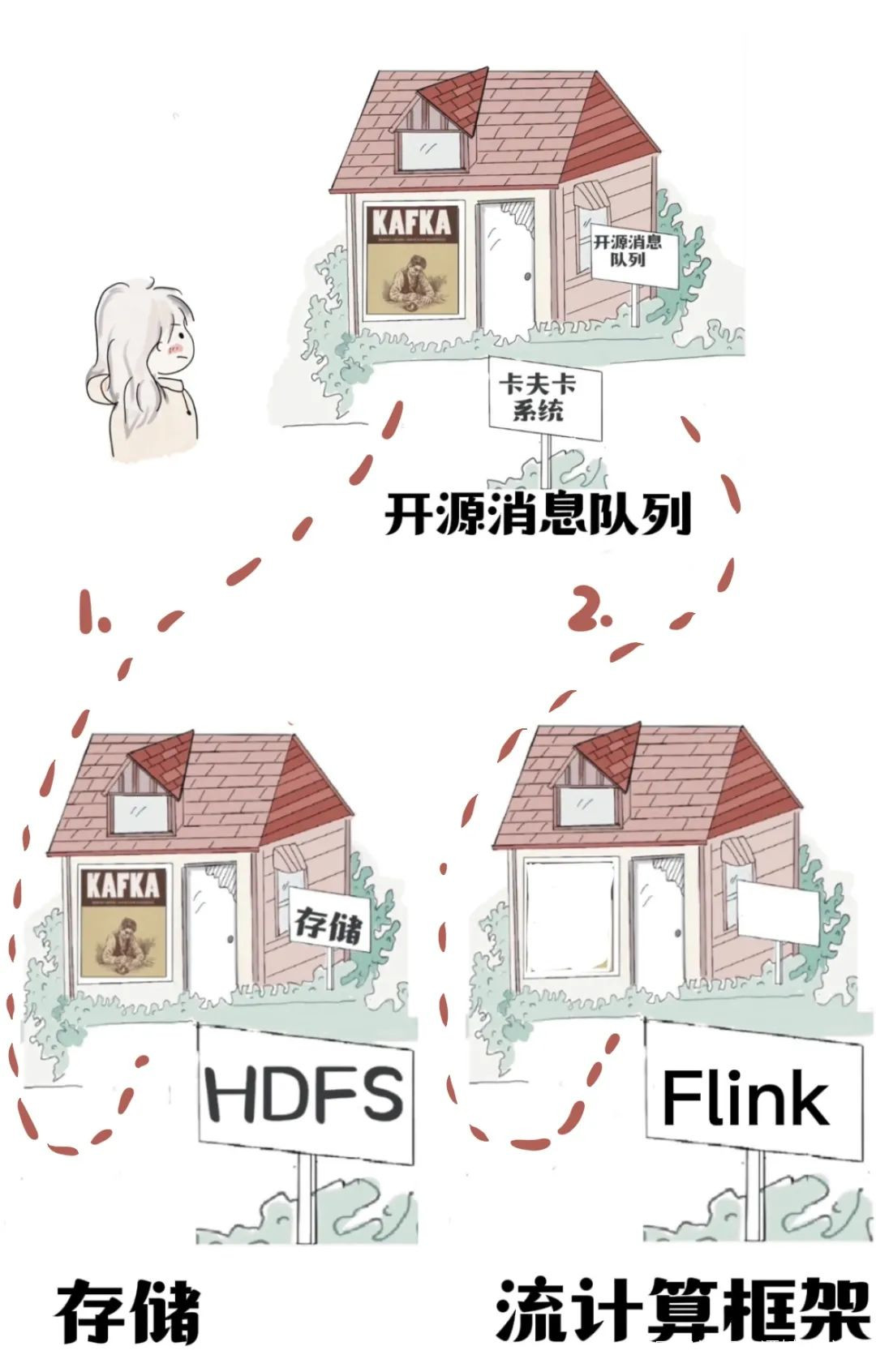
數據流來了,經過卡夫卡開始“有序排隊”。
先往HDFS裏面寫一份,相當於備份,為其他工作準備材料。
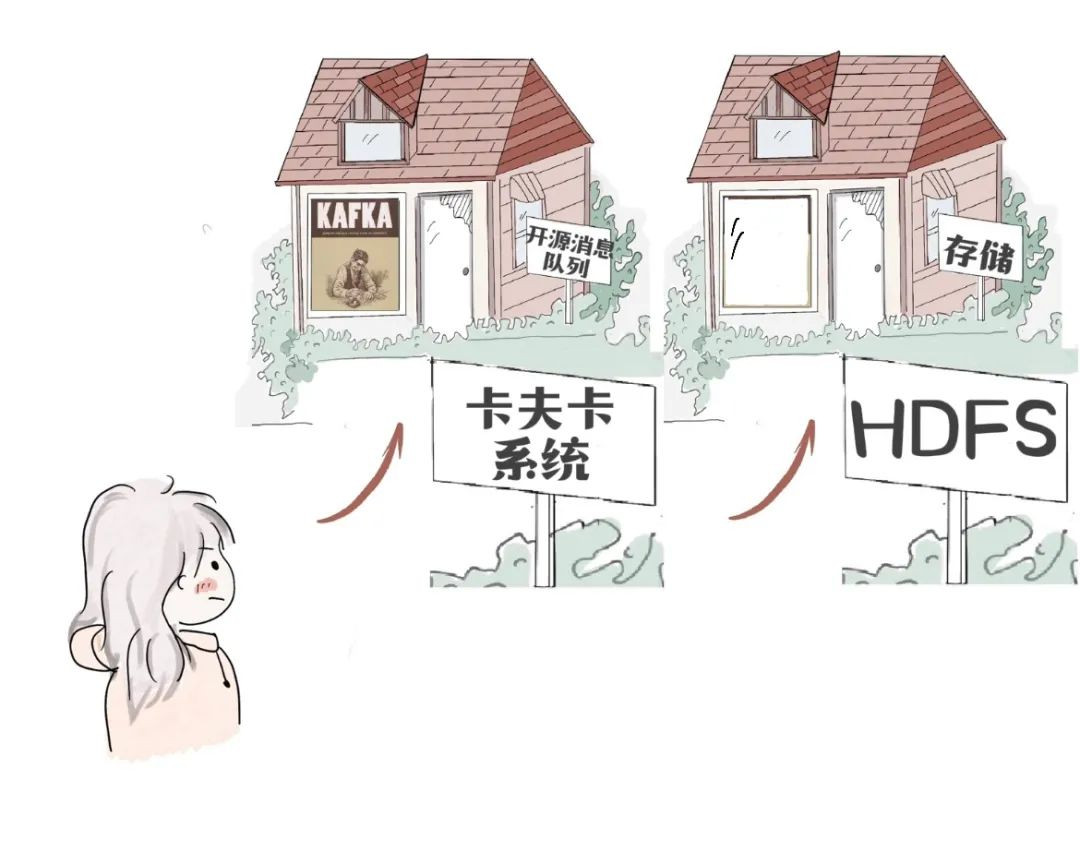
消息隊列還有另一個功能“分流”,把數據分發給不同的地方,存儲,還是計算。
一份數據流向存儲。
另一份數據流向,流計算框架Flink,直接計算。
“超大表格"裏還可以記錄時間,用表裏的時間來精確計算使用APP的時長,幾點幾分進入APP,幾點幾分退出APP。
這取決於“埋點”的密度。
“你看的新聞”和“你購買的商品”背後是有一套標籤體系。
“經常閲讀”和”反覆購買“,這些行為就會成為用户的一部分標籤,日積月累,成為用户畫像。

標籤是怎麼被打上的?
被大數據計算系統計算出來的。
有兩種計算方法:
第一,批處理。
一段時間,計算一下。每小時啓動一個定時任務。這就是典型的批處理。啓動定時任務的時間由工程師來定,也可以追求一分鐘計算一次的“極致”,但是,這樣程序員和系統可能都要重新投胎。
批處理,可以一個小時計算一次。那麼,就一個小時計算一下標籤。

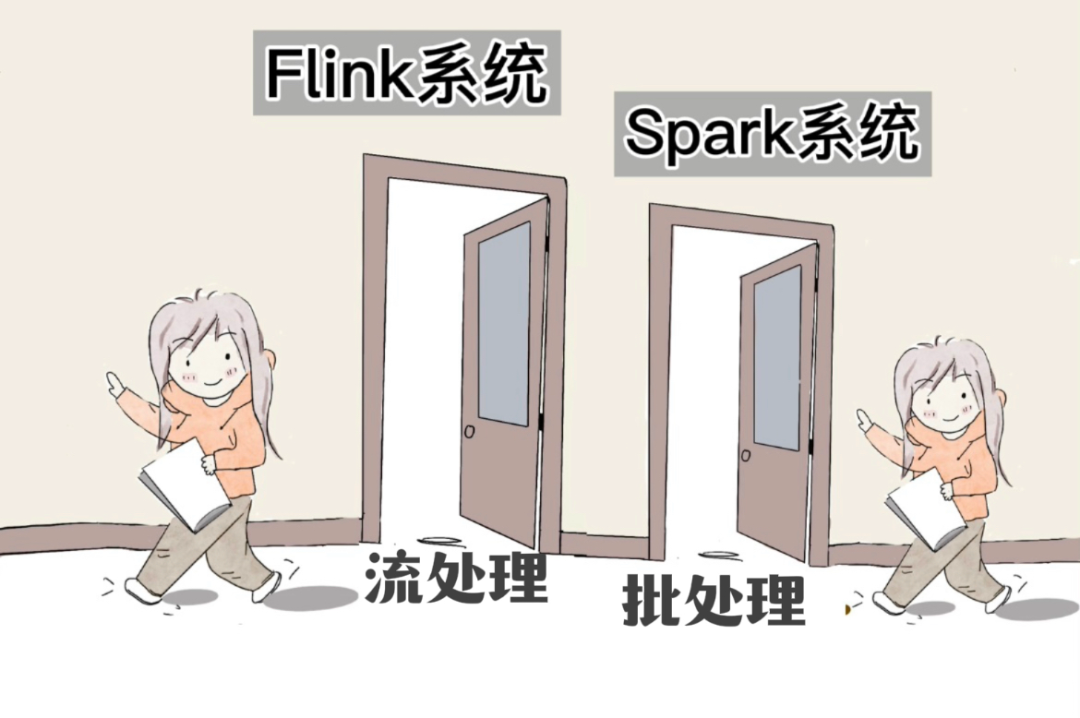
第二,流處理。來一個就計算一個。
換句話説,批處理是讓子彈飛一會。
流處理是,拉出去,就地槍決。
也可以用掃雪來理解。
新數據像雪片一樣飛來。
批處理,一小時,掃雪一次(Spark)。
流處理,落一片,掃一片(Flink) 。
數據從卡夫卡系統出門,立刻進入Flink系統的大門,開始進行比如推薦場景下的“用户畫像”之類的計算。

公司既會使用Spark,也會使用Flink。以Flink為代表的是流處理。以Spark為代表的是批處理。
Flink和Spark這扇門裏走出來的“用户畫像”其實是一種“用户特徵”。
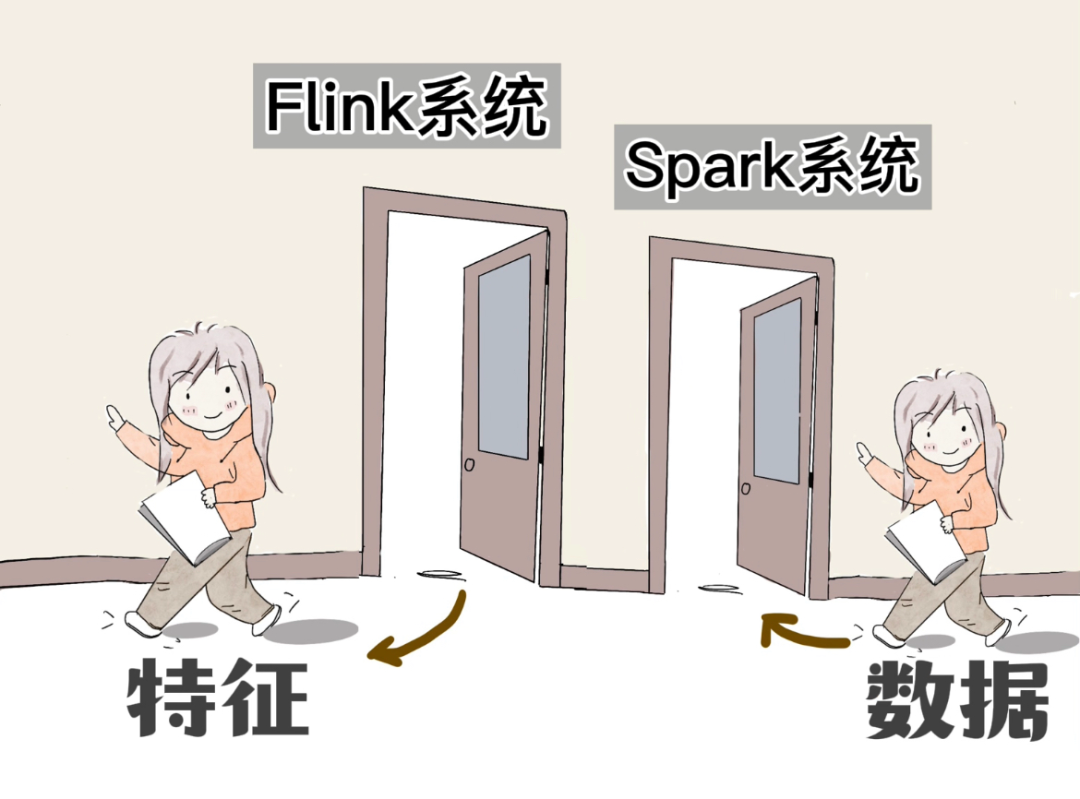
還有其他各種特徵,特徵餵給“人工智能模型”,模型可以預測你下一條,看什麼樣的信息,選購什麼樣的商品。
這就是大數據社交牛逼症的底氣。


2022年3月1日,《互聯網信息服務算法推薦管理規定》,規範算法提供方的行為。不得利用算法屏蔽信息、過度推薦和操縱榜單。
(完)
致謝:感謝魯蔚徵老師,他耐心地回答了我的很多個問題,使這篇文章成為可能。



最後,再介紹一下主編自己吧,
我是譚婧,科技和科普題材作者。
為了在時代中發現故事,
我圍追科技大神,堵截科技公司。
偶爾寫小説,畫漫畫。
生命短暫,不走捷徑。
還想看我的文章,就關注“親愛的數據”。
