深度學習框架簡史:PPT格局初現,中國佔有一席_風聞
Alter-2022-03-23 20:52

撰文 / 張賀飛
編輯 / 沈潔
“科技無國界”的幻想,因為東歐的戰火被徹底擊碎。
蘋果、谷歌、Facebook、SAP、微軟等科技巨頭,早已有了實際的行動。單單是Apple Pay和Google Pay的停用,就已經影響了數千萬人的生活秩序,而GitHub、Node、React等開源平台針對俄羅斯開發者的嚴格限制,則給不少企業的產品開發、商業運作蒙上了一層不確定的陰影。
在這樣的語境下,開源軟件的自主可控再度成為輿論場上的焦點,特別是作為AI基礎技術的深度學習框架,更是聚焦了無數開發者的關切。深度學習框架屬於AI的底層技術創新,一旦這些技術被套上枷鎖,千行百業的智能化轉型將被制約,甚至會影響國內第四次工業革命的進程。
可能在不少人的認知裏,深度學習框架還是一個陌生的詞彙,對其所扮演的角色以及重要性仍處於懵懂狀態。我們不妨從盤點和回顧的視角,梳理下深度學習框架的週期演變,在從學術圈走向工業界再到產業化的歷程中,找尋屬於中國企業的機會和挑戰到底在哪裏。
01 學術時代:學者們的“刀耕火種”
想要講清楚深度學習框架的起源,難免要花上一定的篇幅,簡單概述下人工智能技術的進化歷程:
早在1943年,美國心理學家麥卡洛克和數學家皮茨就提出了人工神經網絡的概念,比世界上最早的通用計算機的出現還早了3年時間。
其後出現了不少新概念和新模型,但人工智能的進展始終差強人意。直到傑弗裏·辛頓在2006年發表了一篇題為《一種深度置信網絡的快速學習算法》的文章,其中的核心理念是利用 GPU 來加速訓練,大幅提高了神經網絡的學習速度。
時間來到2012年,師從傑弗裏·辛頓的多倫多大學研究生艾力克斯·克柴夫斯基,在當年的 ImageNet 挑戰賽中使用一種新的深度神經網絡架構進行訓練,在 ImageNet 數據集上達到了 SOTA 精度,遠超一些學術界的頂級團隊。這種深度神經網絡架構,就是後來大名鼎鼎的AlexNet,並在全球範圍內掀起了深度學習的熱潮。
 圖:傑弗裏·辛頓
圖:傑弗裏·辛頓
在機器學習大行其道的時候,幾乎沒有一種算法在大量的問題上取得壓倒性的優勢,大多數業務問題可以通過大數據和算法結合的經典方式解決。可到了深度學習的時代,數據、算法和算力都在爆炸式增長,為了提高工作的效率,一些研究者開始編寫深度學習模型的幾個必要過程,把前人的研究成果不斷沉澱其中,後來人可以直接調用某些成果,大幅降低了編寫深度學習模型的門檻。
“深度學習框架”的概念由此誕生,迅速湧現出了Theano、Caffe、Torch等多款深度學習框架,至今仍是人工智能圈子裏的熱門話題。
科技文明的每一次躍進,都離不開個體的靈光乍現,人工智能又恰恰是一個標準的眾創型技術。所以早期深度學習框架的締造者,往往被賦予一種特殊的光環,並隨着時間的推移不斷放大其中的價值。可回頭來看,這些盛名在外的早期框架也有着時代的侷限性,所能解決的往往是一類問題,而且有着鮮明的學術色彩。
比如艾力克斯·克柴夫斯基就寫過一套名叫Cuda-Convnet的深度學習框架,可以在GPU上快速跑神經網絡,卻不怎麼重視工程設計,也談不上模塊化和抽象化能力,單純是為了搞科研、出論文。
深度學習開源工具的鼻祖Theano,嚴格地説是一個擅長處理多維數組的 Python 庫,用於高效解決多維數組的計算問題。相較於當前深度學習框架的功能,Theano更像是一個數學表達式的編譯器。
值得一提的是,在深度學習框架“刀耕火種”的日子裏,中國的學者們並沒有缺席。百度2013年成立了深度學習研究院,Caffe等框架的主導者中都有華人的身影。暗合科技創新的潛在趨勢,中國不再是創新進程中的跟隨者,這一次我們也站在了最前沿的領域。
02 商業時代:科技巨頭“闖入江湖”
2015年是深度學習框架的轉折點,這年前後發生了兩件深刻影響到人工智能歷史進程的重要事件:
一件發生在學術領域。微軟亞洲研究院的學者提出了著名的ResNet架構,影響力絲毫不輸當年的AlexNet,不僅在ImageNet的準確率上再創新高,也讓學術界外的工業界形成了一個共識,即深度學習將成為下一個重大技術趨勢。
另一件發生在圍棋圈。谷歌旗下DeepMind團隊開發的AlphaGo,和韓國著名棋手李世石進行了一場圍棋人機大戰,最終以4比1的總比分獲勝。由此出圈的不只有AlphaGo和谷歌,深度學習的概念也被越來越多的“行外人”知曉。

後知後覺的話,這兩起事件都有其弔詭之處。ResNet在2015年的原始殘差網絡的結果一度被質疑無法復現,而AlphaGo的圍棋挑戰賽本身就有作秀的嫌疑。草蛇灰線,伏脈千里,不尋常的背後是科技巨頭們的精妙佈局。
2013年3月,谷歌以4400萬美元的價格收購了傑弗裏·辛頓創建的DNNResearch,這場交易的重心並不是什麼新業務,而是辛頓本人和他的兩位學生。據説百度也參與了這場“拍賣”,並堅持到了辛頓做出選擇的最後一刻。
谷歌瘋狂“斂才”的原因,在2015年11月被揭曉:谷歌大腦團隊開發的深度學習框架TensorFlow正式開源,傑弗裏·辛頓為此做了很多貢獻。谷歌的另一位研究員弗朗索瓦·喬萊特,幾乎獨自完成了Keras框架的開發,為谷歌再添一條護城河。
遺憾錯失傑弗裏·辛頓的百度也沒閒着,2012年開始大規模採購和建立GPU運算集羣,是國內最早投入研究深度學習平台的企業,培養和吸納大批AI頂尖人才,內部打磨重構多年的PaddlePaddle,也在2016年正式開源,後來取了一箇中文名字叫“飛槳”。
同樣對深度學習框架野心勃勃的Meta(原Facebook),走了一條循序漸進的路。先是控制了著名的深度學習庫Torch,然後用從Python替換了Lua語言,對Tensor上的全部模塊進行重構,並在2017年初以PyTorch的身份正式開源。同時還搞了Caffe2項目,像谷歌一樣開啓了雙平台戰略。
這個階段可以説是深度學習框架的第一次“百家爭鳴”,Amazon主導的MXNet、微軟背書的CNTK陸續出現在開源名單上。深度學習框架不再是學者們的自留地,科技巨頭們接過了主導市場的權柄。
相對應的是新舊交替的一幕。
Alpha Go最初是基於Torch開發的,但在TensorFlow開源後立即進行了遷移;Theano的開發團隊在2017年9月宣佈停止維護和更新,從此退出了歷史舞台;微軟的CNTK經歷了一定時間的奮力追趕後,最終在2019年宣佈停止維護;Keras後來被TensorFlow收編,Caffe2被PyTorch接納……
還有很多不知名的深度學習框架,還沒來得及被外界所熟知,就被埋在了人工智能高速增長所掀起的塵土中。相比於豪擲千金買技術、團隊、人才的巨頭,很多初創企業常常被各種因素束手束腳,結局在一開始就註定了。
03 應用時代:“剩者為王”的競速賽
正如人類歷史屢屢被驗證的趨勢,深度學習框架經歷過短暫的激烈角逐後,也呈現出了“寡頭化”的局面。
背靠谷歌這座開源大山,TensorFlow在開源伊始就表現出了主場優勢,大批學者自覺轉移了陣地。按照谷歌天才科學家傑夫·迪恩在一次演講中的説法:2016年TensorFlow的論文引用次數呈現出指數級暴漲。
不過,谷歌無意在學術圈畫地為牢,早早將目光瞄向了工業界,得到了英特爾、英偉達等硬件平台的配合,向全球開發者免費供給AI庫與工具,並在2015年推出了專門為TensorFlow框架打造的計算神經網絡專用芯片TPU,引發了雲端造芯的浪潮,並以每年一代的速度持續迭代。
應該説,谷歌的商業嗅覺非常靈敏,ResNet和AlphaGo一下子就點燃了工業界的激情,人工智能以熊熊大火之勢席捲工業界。TensorFlow自然而然地向工業需求進行傾斜,逐步推出了TensorFlow Serving、TensorFlow Lite等產品,讓客户可以在雲、服務器、移動設備和 IoT 設備上進行部署。
此舉卻被學術界詬病連連,學者們追求的不是部署的便捷性,而是易用性。這也為身為後來者的PyTorch提供了可乘之機,憑藉“易用性”的聚力一招,PyTorch在研究領域迅速站穩腳跟,大多數出版論文和開源模型都在使用 PyTorch,目前論文中的佔比已經達到80%,有了和TensorFlow分庭抗禮的資格。
國外不少研究者心中,深度學習框架已經是TensorFlow和 PyTorch共天下的局面,代表了深度學習框架研發和生產中 90% 以上的用例。可將中國市場納入討論範疇的話,則出現了一些不同的聲音。
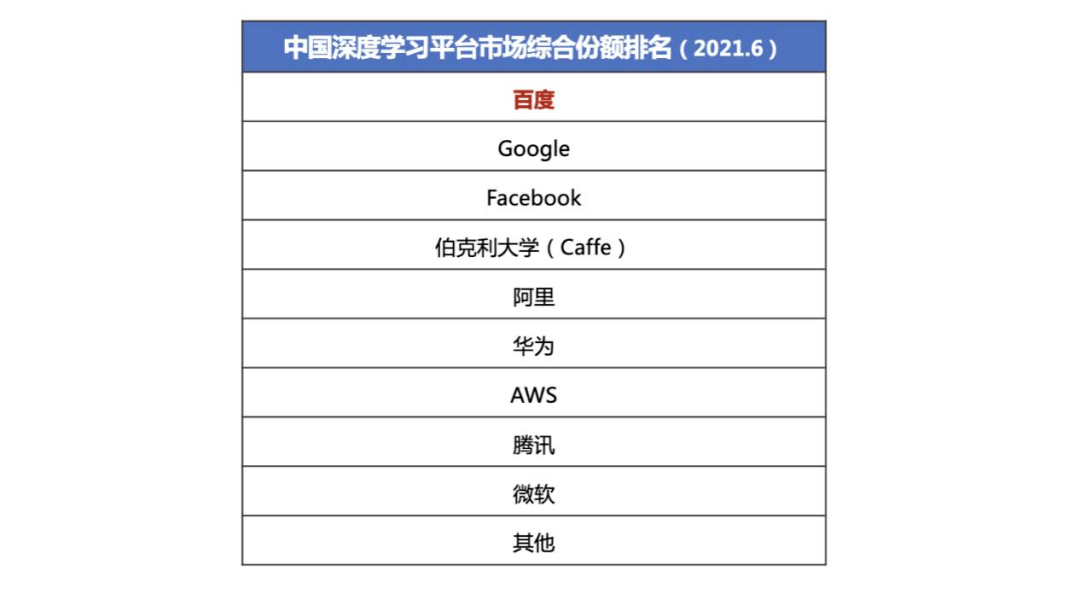
知名市場調研機構IDC曾在2020年下半年公佈了一份中國深度學習框架平台市場份額的報告,TensorFlow、飛槳和PyTorch排名前三,合計佔據了70%以上的份額。等到2021年上半年,IDC再次更新了市場報告,彼時百度飛槳已經超越TensorFlow位居中國市場綜合份額第一。
我們曾就這份報告詢問過不少開發者,對方給出的回答大多是“沒想到”,再進一步的溝通後,聽到最多的聲音是:“原來EasyDL也是飛槳的產品。”其中被頻頻強調的EasyDL,是百度基於飛槳深度學習框架構建的零門檻AI開發平台,開發者上傳數據並標註後,即可訓練相應的模型部署應用。
考慮到中國在人才方面的巨大缺口,飛槳的市場滲透方式有着鮮明的實用主義,先讓客户把AI模型用起來,哪怕他們並不知道後面還有一個深度學習框架。因為中國的大部分中小企業並不具備專業的AI算法開發能力,開發定製 AI 模型絕不是一件容易的事。可從結果導向的話,飛槳或許摸索出了不同於谷歌、Facebook的第三條路。
巨頭們“闖入江湖”的連鎖反應已然發生,市場份額越來越向少數幾個平台集中,無論是美國還是中國,同時在便捷性、易用性、穩定性的多重指標下,算法、算力、編譯器等一個都不能少,深度學習框架的門檻正變得高不可攀。
04 產業時代:中國市場“暗”流湧動
中國市場對深度學習框架的關注,在時空上遲滯了許多,直到中美科技戰的爆發,相關討論才多了起來。
相當長的一段時間裏,中國開發者都是TensorFlow、PyTorch的重度擁躉,還有一些企業曾經深耕過MXNet。這裏面的原因很複雜,百度的工程師文化講求實幹不張揚,飛槳在很長一段時間裏專注於技術和產品,在輿論場上缺少存在感。
國內的其他互聯網公司則犯了“拿來主義”的錯誤,要麼缺少創新精神,怯於和海外的科技巨頭同台競技;要麼奔着摘果子的心態,等別人探索出了眉目再跟隨借鑑…… 所以在2020年以前,中國的深度學習框架屈指可數,除了百度打造的飛槳,只有小米MACE、阿里巴巴XDL在內的幾個推理框架。
轉機出現在2018年前後,中興、華為等企業先後被美國製裁。當Matlab這樣的老牌工具都能被禁用時,不少企業逐漸嗅到了“危險”的氣息:倘若Pytorch和Tensorflow有一天重蹈Matlab的覆轍,對中國AI產業的影響無異於釜底抽薪。
深度學習框架的應用也在這個時間點進入了產業化階段,且呈現出了兩個典型的特徵:一是大型模型訓練,GPT-3、BERT等大模型的誕生,需要在數百台甚至數千台設備上進行訓練,所瞄準的正是產業化的需求;二是可用性,TensorFlow、飛槳、PyTorch先後引入了計算圖和動態圖,目的是讓運算更加簡潔,開發者可以採用命令式的編程風格,方便進行模型的調試。
留給企業和開發者的,其實是一個三難的選擇:倘若像過去那樣All in國外的深度學習框架,存在着各種不確定風險;如果盲目退出國外的框架,似乎也不是理智的選擇,有競爭才會有進步;何況深度學習框架屬於高投入、長週期、搶生態的競爭,在產業鏈中承上啓下的關鍵地位,有着統領產業進步節奏、帶動終端場景與雲端服務協同發展的重要作用,押錯寶的代價不言而喻。
所幸最後的結果並不算糟糕。
按照百度官方的信息,目前基於飛槳開發的模型數量已經有47.6萬個,不乏文心等大模型,服務的開發者數量已經達到406萬,並在270多所高校開設了AI學分課程。至少可以保證在中國市場上奠定飛槳、TensorFlow、PyTorch三分天下的格局,再在市場份額分配上徐徐圖謀。
進入2020年以後,清華大學計圖、曠視科技天元、華為MindSpore、一流科技OneFlow相繼開源,騰訊和阿里也在後面推出了PocketFlow、X-Deep Learning。如果這些新空間有能力以資金、人才等資源換時間,針對中國產業的需求因地制宜,也不排除進一步向國外框架搶奪份額的可能。
回到文初遺留的問題,在AI基礎技術的角逐中,來自中國的力量確實有些孤獨,很長時間裏只有百度一家在搏殺。好在結果並不糟糕,在深度學習框架的“PPT”(飛槳PaddlePaddle、PyTorch、TensorFlow)格局中,已經有一個字母是來自中國,不必再面臨被封殺後無計可施的境地。
05 結語
距離1956年的達特矛斯會議,已經走過了66個春秋,人工智能終於迎來了工業大生產的浪潮。來自中國的企業和科學家們,或許缺席了人工智能的過去,卻在一步步錨定人工智能的未來。
目前中國已經在AI應用層站穩了腳跟,近幾年的專利申請甚至超過了美國,在數據、人才、市場等方面的綜合優勢正在逐步顯現。假如可以用深度學習框架進一步聚合開發者、資本和平台,創造有利於創新的土壤,不無可能擺脱“數字鐵幕”的威脅,讓中國AI在一條堅實的道路上加速奔跑。