英偉達宣佈支持UCIe,推出144核CPU和800億晶體管GPU_風聞
半导体行业观察-半导体行业观察官方账号-专注观察全球半导体最新资讯、技术前沿、发展趋势。2022-03-23 14:11
來源:內容來自半導體行業觀察(ID:icbank)綜合,謝謝。雖然英偉達以GPU聞名世界,但他們在CPU上的表現也備受關注。在昨日舉辦的GTC 2022上,Nvidia 首席執行官 Jensen Huang 終於分享了有關公司 Arm 努力的更多細節,因為他推出了公司新的 144 核 Grace CPU Superchip,這是該公司第一款專為數據中心設計的、基於Arm架構的CPU 。
據介紹,這個基於 Neoverse 的系統支持 Arm v9,可以把兩個CPU與 Nvidia 新品牌的 NVLink-C2C 互連技術融合在一起。Nvidia 聲稱 Grace CPU Superchip 在 SPEC 基準測試中提供的性能比其自己的 DGX A100 服務器中的兩個上一代 64 核 AMD EPYC 處理器高出 1.5 倍,並且是當今領先服務器芯片的兩倍。
總體而言,Nvidia 表示,Grace CPU Superchip 將於 2023 年初出貨,將成為市場上最快的處理器,適用於超大規模計算、數據分析和科學計算等廣泛的應用。

此外,Nvidia 還分享了有關 Grace Hopper Superchip 的新細節,這是其之前發佈的 CPU+GPU 芯片. Nvidia 還宣佈了其新的 NVLink 芯片到芯片 (C2C) 接口,這是一種支持內存一致性的芯片到芯片和芯片到芯片互連。NVLink-C2C 可提供高達 25 倍的能效,比 Nvidia 目前使用的 PCIe 5.0 PHY 的面積效率高 90 倍,支持高達 900 GB/s 或更高的吞吐量。該接口支持 CXL 和 Arm 的 AMBA CHI 等行業標準協議,並支持從基於 PCB 的互連到硅中介層和晶圓級實現的各種連接。
令人驚訝的是,Nvidia 現在允許其他供應商將該設計用於他們自己的小芯片。此外,Nvidia 宣佈將支持新的 UCIe 規範。讓我們深入瞭解細節。
在我們瞭解新的 Grace CPU Superchip之前,您需要快速回顧一下它的第一次實例化。Nvidia 去年首次宣佈了最初稱為Grace CPU的產品,但該公司沒有分享太多細粒度的細節。Nvidia 現在已將第一次嘗試的名稱更改為 Grace Hopper Superchip。
Grace Hopper Superchip 在一個載板上有兩個不同的芯片,一個 CPU 和一個 GPU。我們現在知道 CPU 有 72 個內核,使用基於 Neoverse 的設計,支持 Arm v9,並與 Hopper GPU 配對。這兩個單元通過 900 GBps NVLink-C2C 連接進行通信,提供 CPU 和 GPU 之間的內存一致性,從而允許兩個單元同時訪問 LPDDR5X ECC 內存池,據稱帶寬比標準系統提高了 30 倍。
Nvidia 最初沒有公佈設計中使用的 LPDDR5X 數量,但在這裏我們可以看到該公司現在聲稱擁有“600GB 內存 GPU”,其中肯定包括 LPDDR5X 內存池。我們知道 LPDDR5X 每個封裝的最高容量為 64GB,這意味着 CPU 配備了高達 512GB 的 LPDDR5X。同時,Hopper GPU 通常具有 80GB 的 HBM3 容量,使我們接近 Nvidia 的 600GB 數字。讓 GPU 訪問該數量的內存容量可能會對某些工作負載產生變革性影響,尤其是對於經過適當優化的應用程序。
今天的公告涵蓋了 Grace CPU Superchip,它基於 Grace Hopper CPU+GPU 設計,但使用第二個 CPU 封裝而不是 Hopper GPU。這兩個 72 核芯片也通過 NVLink-C2C 連接進行連接,提供一致的 900 GB/s 連接,將它們融合為一個 144 核單元。此外,基於 Arm v9 Neoverse 的芯片支持 Arm 的 Scalable Vector Extensions (SVE),這是一種性能提升的 SIMD 指令,其功能類似於 AVX。
Grace CPU Superchip 使用 Arm v9,它告訴我們該芯片使用 Neoverse N2 設計. Neoverse N2 平台是 Arm 首個支持新發布的 Arm v9 擴展(如 SVE2 和內存標記)的 IP,其性能比 V1 平台高出 40%。N2 Perseus 平台採用 5nm 設計,支持 PCIe Gen 5.0、DDR5、HBM3、CCIX 2.0 和 CXL 2.0。Perseus 設計針對每功率性能(瓦特)和每面積性能進行了優化。
考慮到 Grace CPU Superchip 的兩個 CPU 和板載內存都消耗 500W 的峯值功率,這很有意義。這與其他領先的 CPU 具有競爭力,例如 AMD 的 EPYC(霄龍),每個芯片的最高功率為 280W(這不包括內存功耗)。Nvidia 聲稱 Grace CPU 在市場上的效率將是競爭 CPU 的兩倍。
每個 CPU 都可以訪問自己的 8 個 LPDDR5X 封裝,因此這兩個芯片仍然會受到近遠內存的標準 NUMA 類趨勢的影響。儘管如此,兩個芯片之間增加的帶寬也應該有助於減少由於競爭減少而導致的延遲,從而實現非常有效的多芯片實現。該設備還配備了 396MB 的片上緩存,但尚不清楚這是用於單個芯片還是兩者兼有。
Grace CPU Superchip 內存子系統提供高達 1TB/s 的帶寬,Nvidia 稱這是 CPU 的首創,是支持 DDR5 內存的其他數據中心處理器的兩倍多。LPDDR5X 共有 16 個封裝,可提供 1TB 容量。此外,Nvidia 指出,Grace 使用了 LPDDR5X 的第一個 ECC 實現。
這給我們帶來了基準。Nvidia 聲稱 Grace CPU Superchip 在 SPECrate_2017_int_base 基準測試中比它在 DGX A100 系統中使用的兩個上一代 64 核 EPYC Rome 7742 處理器快 1.5 倍。Nvidia 的這一聲明基於硅前(pre-silicon)模擬,該模擬預測 Grace CPU 的得分為 740+(每個芯片 370)。AMD 的當前一代 EPYC Milan 芯片是當前數據中心的性能領導者,其 SPEC 結果從 382 到 424 不等,這意味着最高端的 x86 芯片仍將保持領先地位。但是,Nvidia 的解決方案將具有許多其他優勢,例如電源效率和對 GPU 更友好的設計。
兩個 Grace CPU 通過 Nvidia 新的 NVLink 芯片到芯片 (C2C) 接口進行通信。這種芯片到芯片和芯片到芯片的互連支持低延遲內存一致性,允許連接的設備同時在同一個內存池上工作。Nvidia 使用其 SERDES 和 LINK 設計技術製作了界面,重點是能源和麪積效率。
Nvidia 表示,與 Nvidia 目前使用的 PCIe 5.0 PHY 相比,NVLink-C2C 可以提供高達 25 倍的能效和 90 倍的面積效率,支持高達 900 GB/s 或更高的吞吐量。此外,該接口還支持 CXL 和 Arm 的 AMBA 相干集線器接口 (CHI) 等行業標準協議。它還支持多種類型的連接,從基於 PCB 的互連到硅中介層和晶圓級實現。
對 AMBA CHI 的支持很重要,因為它支持 Arm 的相干網狀網絡 (CMN-700),將 Neoverse N2 設計與智能高帶寬低延遲接口與其他平台添加劑(如 DDR、HBM 和各種加速器技術,使用行業標準協議的組合,如 CCIX、CXL 和 PCIe。這種新的網格設計是基於單芯片和多芯片設計的下一代 Arm 處理器的支柱。您可以在此處閲讀有關該協議的更多信息。
Nvidia還宣佈將支持新的UCIe小芯片互連標準,該標註已經得到如英特爾、AMD、Arm、台積電和三星等其他行業巨頭的支持。這種標準化的芯片到芯片互連旨在通過開源設計提供小芯片之間的通信,從而降低成本並培育更廣泛的經過驗證的小芯片生態系統。最後,UCIe 標準旨在與其他連接標準(如 USB、PCIe 和 NVMe)一樣普遍和普遍,同時為小芯片連接提供卓越的功率和性能指標。英偉達對這一新舉措的支持意味着我們理論上可以看到英偉達 CPU 芯片與未來的競爭芯片設計放在同一個封裝中。
NVLink-C2C 現在將覆蓋 Nvidia 的所有芯片,包括 GPU、CPU、SOC、NIC 和 DPU。Nvidia 還表示,它正在開放規範以允許其他公司在其小芯片設計中使用 NVLink。這為客户提供了使用 UCIe 接口或 NVLink 的選項,儘管 Nvidia 聲稱 NVLink-C2C 已針對比 UCIe 更低的延遲、更高的帶寬和更高的能效進行了優化。

Nvidia 正在通過 Grace CPU Superchip 擴展其目標市場,現在涵蓋超大規模計算、雲、數據分析、HPC 和 AI 工作負載,有效地瞄準了通用服務器市場。Grace CPU Superchip 支持 Nvidia 的整個 CUDA 堆棧,並將運行 Nvidia 的所有應用程序,包括 Nvidia RTX、Nvidia AI、HPC 和 Omniverse。這些芯片將於 2023 年上半年開始出貨。
Nvidia 表示,它將發佈一份白皮書,提供有關架構的更詳細的細節,我們將密切關注。接下來,我們先了解一下他們全新的GPU
800億晶體管,英偉達發佈新一代GPU
過去兩年,儘管 COVID-19在肆虐全球,但技術卻從未停歇。尤其是對 NVIIDA 來説。該公司在兩年前的 GTC 2020 上推出了 Ampere GPU 架構,並且在此期間銷售了比以往任何時候都更多的芯片。邁入到2022 年,他們又推出了下一代的新架構——Hopper 架構,它將支撐下一代 NVIDIA 服務器 GPU。
正如大家所看到的一樣,兩年前推出的Ampere 是 NVIDIA 迄今為止最成功的服務器 GPU 架構,僅在去年,數據中心銷售額就超過了 100億 美元。然而,英偉達缺不可以滿足於現狀,因為服務器加速器市場的增長和盈利能力意味着競爭者比以往任何時候都多,他們的目標都是在英偉達把持的市場上分一杯羹。為此,NVIDIA 已經準備好(並且渴望)來談論他們的下一代架構,以及將實現它的第一批產品。
將 NVIDIA 帶入下一代服務器 GPU 的是 Hopper 架構。Hopper 架構以計算機科學先驅 Grace Hopper 的名字命名,對公司正在進行的 GPU 架構系列來説,這是一個非常重要但也是非常 NVIDIA 式的更新。因為公司的努力,他們現在將其產品線分為服務器和消費者 GPU 配置,Hopper 正在 NVIDIA 將公司做得好的一切都加倍,然後將其構建得比以往任何時候都更大。

反過來,這是 NVIDIA Hopper 架構的前沿和中心。雖然 NVIDIA 已全面投資以從內存帶寬和 I/O 到機器學習和機密計算等方面提高性能,但 Hopper 最大的性能提升是在 NVIDIA 想出如何減少工作量、使其處理器的每個領域都都更快。
Hopper 的第一代產品是 H100——NVIDIA 的旗艦服務器加速器。基於 GH100 GPU 的 GH100 是傳統的 NVIDIA 服務器先行產品,該公司從高端起步,為其最大、資金最雄厚的服務器和企業客户開發加速卡。
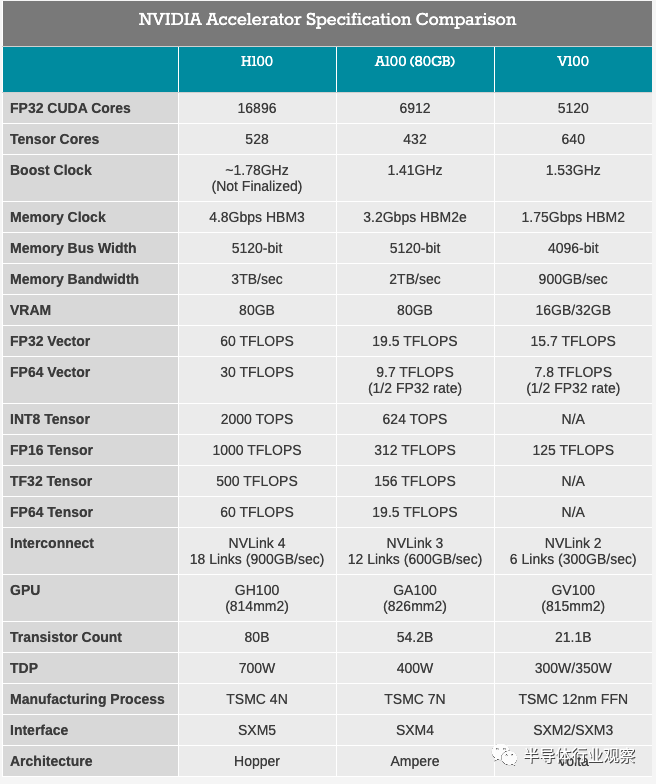
與 NVIDIA 之前的服務器加速器一樣,H100 卡並未配備完全啓用的 GPU。因此,NVIDIA 提供的數據基於實現的 H100,但啓用了許多功能單元(和內存堆棧)

從官方層面,NVIDIA 喜歡引用啓用稀疏性的數字,但出於我們規格表的目的,我使用非稀疏數字與以前的 NVIDIA 硬件以及競爭硬件進行更多的比較。啓用稀疏性後,TF32 的性能可以翻倍。

NVIDIA 將提供兩種通常的 H100 規格:用於高性能服務器的SXM mezzanine和用於更主流服務器的 PCIe 卡。與上一代相比,這兩種外形尺寸的功率要求都顯著提高。NVIDIA 為 SXM 版本的顯卡提供了令人瞠目結舌的700 瓦 TDP,比 A100 官方的 400W TDP 高出 75%。不管是好是壞,NVIDIA 在這裏沒有任何阻礙,儘管晶體管功率擴展的持續下降也沒有給 NVIDIA 帶來任何好處。
冷卻如此熱的 GPU 將是一項有趣的任務,儘管不會超出當前的技術。在這些功率水平下,我們幾乎可以肯定會關注液體冷卻,SXM 外形非常適合這種情況。不過,值得注意的是,競爭對手的 OAM 外形尺寸——本質上是開放計算項目對用於加速器的 SXM 的看法——被設計為最高 700W。因此,假設服務器供應商不採用奇特的冷卻方法,NVIDIA 似乎正在接近mezzanine顯卡所能處理的上限。
同時,H100 PCie 卡的 TDP 將從今天的 300W 提高到 350W。鑑於 300W 是 PCIe 卡的傳統限制,看看 NVIDIA 及其合作伙伴如何讓這些卡保持低温將會很有趣。否則,由於只有 SXM 卡的一半 TDP,我們預計 PCIe 版本的時鐘/配置會明顯變慢,以降低卡的功耗。
Hopper張量核心:現在使用 Transformer Engines
繼續討論 Hopper 架構的重要架構特性,我們從 NVIDIA 的 Transformer 引擎開始。Transformer 引擎名副其實,是一種新型的、高度專業化的張量核心,旨在進一步加速 Transformer ML 模型。
為了與 NVIDIA 對機器學習的關注保持一致,對於 Hopper 架構,該公司重新審視了 ML 市場的構成,以及哪些工作負載很受歡迎和/或對現有硬件的要求最高。在這方面,贏家是Transformer,這是一種深度學習模型,由於其在自然語言處理和計算機視覺中的實用性而迅速普及。Transformer 技術(例如GPT-3模型)的最新進展,以及服務運營商對更好自然語言處理的需求,使 Transformer 成為 ML 的最新重大突破。
但與此同時,對Transformer的處理要求也阻礙了更好模型的開發。簡而言之,更好的模型需要越來越多的參數,僅 GPT-3 就有超過 1750 億個參數,即使在大型 GPU 集羣上,transformer 的訓練時間也變得難以處理。
為此,NVIDIA 開發了一種張量核心的變體,專門用於加速 Transformer 訓練和推理,他們將其稱為 Transformer Engine。NVIDIA 已經優化了這個新單元,將其剝離為僅處理大多數轉換器 (FP16) 使用的低精度數據格式,然後通過引入 FP8 格式進一步縮小。簡而言之,新單元的目標是使用每一步所需的最低精度來訓練Transformer而不損失精度。換句話説,避免做不必要的工作。
結合 H100 上的額外內存和更快的 NVLink 4 I/O,NVIDIA 聲稱大型 GPU 集羣可以將Transformer訓練速度提高 9 倍,這將把當今最大模型的訓練時間縮短到一個更合理的時期時間,並使更大的模型更實用。
同時,在推理方面,Hopper 還可以立即使用自己的 FP8 訓練模型進行推理。這是 Hopper 的一個重要區別,因為它允許客户跳過將訓練有素的Transformer模型轉換和優化到 INT8 的過程。NVIDIA 並未聲稱堅持使用 FP8 而不是 INT8 帶來的任何特定性能優勢,但這意味着開發人員可以享受與在 INT8 模型上運行推理相同的性能和內存使用優勢,而無需先前所需的轉換步驟。
最後,NVIDIA 聲稱 H100 的Transformer推理性能比 A100 提高了 16 倍到 30 倍。就像他們的訓練聲明一樣,這是 H100 集羣與 A100 集羣的對比,因此內存和 I/O 改進也在這裏發揮了作用,但它仍然強調 H100 的Transformer引擎不僅僅是為了加快訓練速度。
DPX 指令:GPU 的動態編程
NVIDIA 對 Hopper 架構的另一項重大智能改進來自動態編程領域。對於他們最新一代的技術,NVIDIA 正在通過添加一組僅用於動態編程的新指令來增加對編程模型的支持。該公司正在調用這些 DPX 説明。
簡而言之,動態編程是一種將複雜問題以遞歸方式分解為更小、更簡單的問題,然後首先解決這些更小問題的方法。動態規劃的關鍵特徵是,如果其中一些子問題相同,則可以識別並消除這些冗餘——這意味着子問題可以解決一次,並將其結果保存以供將來在更大的問題中使用。
所有這一切都意味着,與 Sparsity 和 Transformer Engines 一樣,NVIDIA 正在實施動態編程,以允許他們的 GPU 擺脱更多的工作。通過消除可以根據動態編程規則分解的工作負載的冗餘部分,NVIDIA 的 GPU 需要做的工作要少得多,而且它們可以更快地產生結果。
儘管與 Transformer 引擎不同,通過 DPX 指令添加動態編程支持與其説是加速 GPU 上的現有工作負載,不如説是在 GPU 上啓用新的工作負載。Hopper 是第一個支持動態編程的 NVIDIA 架構,因此可以通過動態編程解決的工作負載通常在 CPU 和 FPGA 上運行。在這方面,這是 NVIDIA 發現了他們可以從 CPU 竊取並在 GPU 上運行的更多工作負載。
總體而言,NVIDIA 聲稱單個 H100 上的動態編程算法性能與 A100 上的幼稚執行相比提高了 7 倍。
至於 DPX 指令對現實世界的影響,NVIDIA 將路線規劃、數據科學、機器人技術和生物學列為新技術的潛在受益者。這些領域已經使用了幾種著名的動態規劃算法,例如 Smith-Waterman 和 Flyod-Warshall,它們對基因序列對齊進行評分並分別找到目的地對之間的最短距離。
總體而言,動態編程是高性能工作負載中比較小眾的領域之一。但 NVIDIA 認為,一旦有合適的硬件支持,它就可以很好地適用於 GPU。
機密計算:保護 GPU 數據免遭窺探
遠離以性能為中心的功能,NVIDIA 對 Hopper 架構的另一項重大推動是在安全方面。隨着雲計算環境(尤其是共享 VM 環境)中 GPU 使用的擴展,該公司正在將新的重點放在相關的安全問題上,以及如何保護共享系統的安全。
這些努力的最終結果是,Hopper 正在為可信執行環境引入硬件支持。具體來説,Hopper 支持創建 NVIDIA 所謂的機密虛擬機,其中 VM 環境中的所有數據都是安全的,並且所有進入(和離開)環境的數據都是加密的。
NVIDIA 在我們的預先簡報中沒有詳細介紹支持其新安全功能的太多技術細節,但據該公司稱,它是新硬件和軟件功能組合的產物。特別值得注意的是,進出 GPU 時的數據加密/解密速度足以以 PCIe 線速(64GB/秒)完成,這意味着在使用此安全性時,實際主機到 GPU 帶寬不會減慢特徵。
反過來,這種受信任的執行環境旨在抵抗所有形式的篡改。GPU 本身的內存內容由 NVIDIA 所謂的“硬件防火牆”保護,它可以防止外部進程接觸它們,同樣的保護也擴展到 SM 中的傳輸中數據。據説,受信任的環境也可以防止操作系統或管理程序從上面訪問 GPU 的內容,將訪問權限限制為僅 VM 的所有者。也就是説,即使對 GPU 進行物理訪問,也不應該能夠訪問 hopper 上的安全 VM 中的數據。
歸根結底,NVIDIA 的目標似乎是讓他們的客户在使用 GPU 處理敏感數據時感到舒適,方法是讓他們在安全模式下工作時有很多硬件可以闖入。反過來,這不僅是為了保護傳統的敏感數據,例如醫療數據,也是為了保護 NVIDIA 的一些客户現在正在創建的高價值 AI 模型。考慮到創建和訓練模型所需的所有工作,客户不希望他們的模型被複制,無論是在共享雲環境中還是從物理上不安全的邊緣設備中退出。
多實例 GPU v2:現在具有隔離性
作為 NVIDIA 在機密計算方面的安全工作的延伸,該公司還將這些保護擴展到其多實例 GPU (MIG) 環境。MIG 實例現在可以完全隔離,實例和主機之間的 I/O 也完全虛擬化和安全,基本上授予 MIG 實例與 H100 整體相同的安全功能。總體而言,這使 MIG 更接近 CPU 虛擬化環境,其中各種 VM 假定彼此不信任並保持隔離。
NVLink 4:將芯片 I/O 帶寬擴展至 900GB/秒
Hopper 架構還帶來了 NVIDIA 的 NVLink 高帶寬互連的新版本,用於將 GPU(很快會擴展到CPU)連接在一起,以便在可以擴展到多個 GPU 的工作負載中獲得更好的性能。NVIDIA 在其每一代旗艦 GPU 上都在 NVLink 上進行了迭代,這次也不例外,他們推出了 NVLink 4。
在等待 NVIDIA 全面披露技術規格的同時,該公司已確認 NVLink 單芯片帶寬已從 A100 的 600GB/秒增加到 H100 的 900GB/秒。請注意,這是 NVLink 支持的所有單個鏈路上的所有上行和下行帶寬的總和,因此將這些數字減半以獲得特定的傳輸/接收速率。
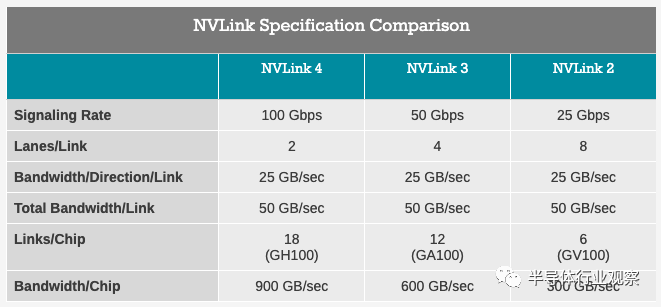
鑑於 NVLink 3 已經以 50 Gbit/秒的信號速率運行,尚不清楚額外的帶寬是由更快的信號速率提供的,還是 NVIDIA 再次調整了來自 GPU 的鏈接數量。NVIDIA 之前更改了 A100 的 NVLink 通道配置,當他們將通道寬度減半並將通道數量增加一倍時,同時將信號速率提高了一倍。在此基礎上添加通道意味着不必弄清楚如何進一步提高信號速率,但這也意味着 NVLink I/O 所需的引腳數量增加了 50%。
同樣值得注意的是,NVIDIA 正在通過 Hopper 添加 PCIe 5.0 支持。由於 PCIe 仍用於主機到 GPU 的通信(至少在 Grace 準備好之前),這意味着 NVIDIA 已經將其 CPU-GPU 帶寬翻了一番,讓他們能夠更好地保持 H100 的供電。儘管充分利用 PCIe 5.0 需要一個支持 PCIe 5.0 的主機 CPU,但 AMD 或 Intel 還沒有提供這種支持。據推測,到 NVIDIA 在第三季度發佈 H100 時,會有人準備好硬件併發貨,尤其是因為 NVIDIA 喜歡對其 DGX 預構建服務器進行同質化。
最後,隨着 H100/NVLink 4 的推出,NVIDIA 也利用這段時間宣佈了一款新的外置 NVLink 交換機。這種外部開關超越了 NVIDIA 當前的板載 NVSwitch 功能,該功能用於幫助在單個節點內構建更復雜的 GPU 拓撲,並允許 H100 GPU 跨多個節點直接相互通信。從本質上講,它可以替代 NVIDIA GPU 通過 Infiniband 網絡進行跨節點通信。
外部 NVLInk 開關允許在單個域內將多達 256 個 GPU 連接在一起,這適用於 32 個 8 路 GPU 節點。據 NVIDIA 稱,該交換機提供的總帶寬為 70.4TB/秒。
然而,值得注意的是,NVLink Switch 並不是 Infiniband 的批發替代品——當然,NVIDIA 也通過其網絡硬件部門進行銷售。其他類型的通信(例如 CPU 到 CPU)仍然需要節點之間的 Infiniband 連接,因此外部 NVLink 網絡是對 Infiniband 的補充,允許 H100 GPU 在它們之間直接聊天。
HGX For H100
最後但並非最不重要的一點是,NVIDIA 已確認他們也在為 H100 更新其 HGX 主板生態系統。HGX 主板是 NVIDIA 多 GPU 設計的主要部分,因為他們首次開始使用 SXM 外形尺寸的 GPU,HGX 主板是 NVIDIA 生產的 GPU 主板,供系統構建者用於設計完整的多 GPU 系統。HGX 板為 NVIDIA 的 SXM 外形 GPU 提供了完整的連接和安裝環境,然後服務器供應商可以將電源和 PCIe 數據(除其他外)從其主板路由到 HGX 主板。對於當前的 A100 一代,NVIDIA 一直在銷售 4 路、8 路和 16 路設計。

Hopper H100 加速器:2022 年第三季度發貨
總結一下,NVIDIA 計劃在今年第三季度推出配備 H100 的系統。這將包括 NVIDIA 的全套自建系統,包括 DGX 和 DGX SuperPod 服務器,以及來自 OEM 合作伙伴使用 HGX 基板和 PCIe 卡的服務器。儘管以典型的方式,英偉達並未公佈單獨的 H100 定價,理由是他們通過服務器合作伙伴銷售此硬件。一旦 NVIDIA 宣佈他們自己的 DGX 系統的價格,我們就會有更多的瞭解,但我只想説,不要指望 H100 卡會便宜。
