一塊英偉達3090單挑180億參數大模型,國產開源項目這回殺瘋了_風聞
量子位-量子位官方账号-2022-05-17 15:53
明敏 發自 凹非寺
量子位 | 公眾號 QbitAI
什麼?單塊GPU也能訓練大模型了?
還是20系就能拿下的那種???
沒開玩笑,事實已經擺在眼前:
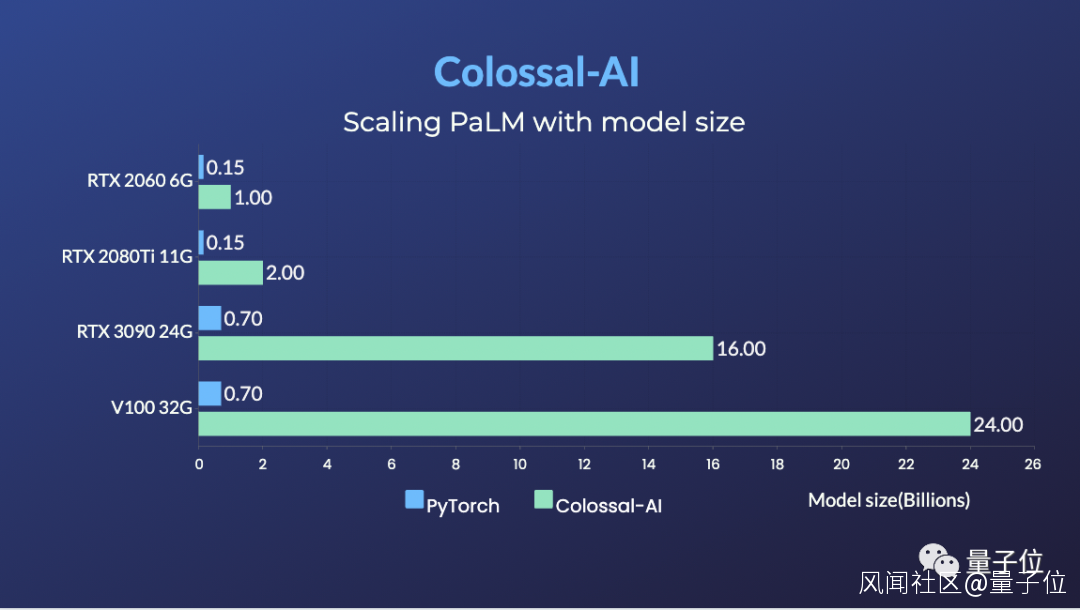
RTX 2060 6GB普通遊戲本能訓練15億參數模型;
RTX 3090 24GB主機直接單挑180億參數大模型;
Tesla V100 32GB連240億參數都能拿下。
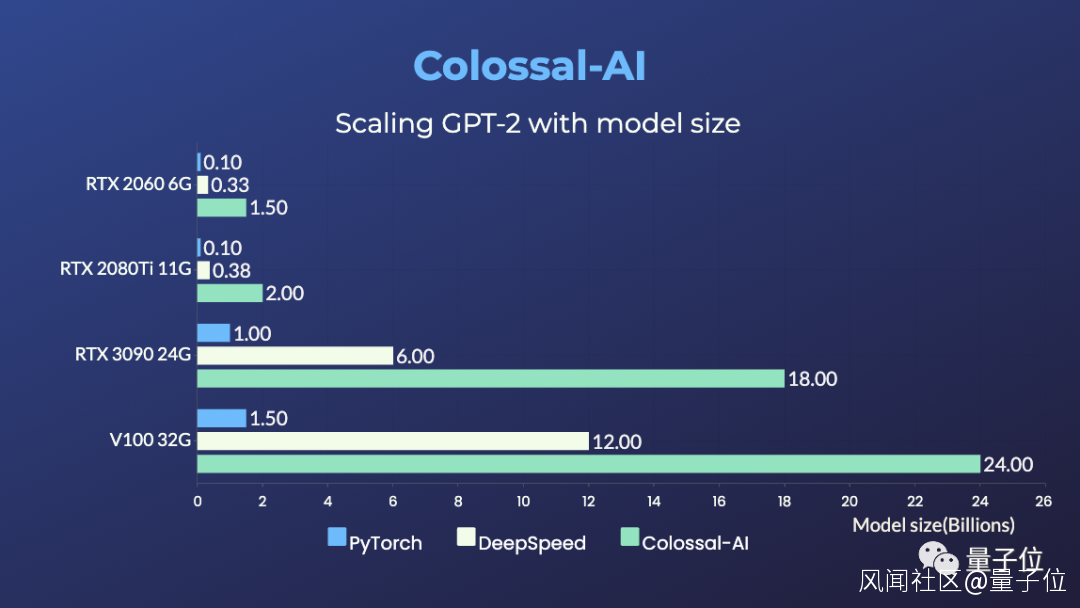
相比於PyTorch和業界主流的DeepSpeed方法,提升參數容量能達到10多倍。
而且這種方法完全開源,只需要幾行代碼就能搞定,修改量也非常少。

這波操作真是直接腰斬大模型訓練門檻啊,老黃豈不是要血虧 。
。
那麼,搞出如此大名堂的是何方大佬呢?
它就是國產開源項目Colossal-AI。
自開源以來,曾多次霸榜GitHub熱門第一。
**△**開源地址:https://github.com/hpcaitech/ColossalAI
主要做的事情就是加速各種大模型訓練,GPT-2、GPT-3、ViT、BERT等模型都能搞定。
比如能半小時左右預訓練一遍ViT-Base/32,2天訓完15億參數GPT模型、5天訓完83億參數GPT模型。
同時還能省GPU。
比如訓練GPT-3時使用的GPU資源,可以只是英偉達Megatron-LM的一半。
那麼這一回,它又是如何讓單塊GPU訓練百億參數大模型的呢?
我們深扒了一下原理~
高效利用GPU+CPU異構內存
為什麼單張消費級顯卡很難訓練AI大模型?
顯存有限,是最大的困難。
當今大模型風頭正盛、效果又好,誰不想上手感受一把?
但動不動就“CUDA out of memory”,着實讓人遭不住。

目前,業界主流方法是微軟DeepSpeed提出的ZeRO (Zero Reduency Optimizer)。
它的主要原理是將模型切分,把模型內存平均分配到單個GPU上。
數據並行度越高,GPU上的內存消耗越低。
這種方法在CPU和GPU內存之間僅使用靜態劃分模型數據,而且內存佈局針對不同的訓練配置也是恆定的。
由此會導致兩方面問題。
第一,當GPU或CPU內存不足以滿足相應模型數據要求時,即使還有其他設備上有內存可用,系統還是會崩潰。
第二,細粒度的張量在不同內存空間傳輸時,通信效率會很低;當可以將模型數據提前放置到目標計算設備上時,CPU-GPU的通信量又是不必要的。
目前已經出現了不少DeepSpeed的魔改版本,提出使用電腦硬盤來動態存儲模型,但是硬盤的讀寫速度明顯低於內存和顯存,訓練速度依舊會被拖慢。
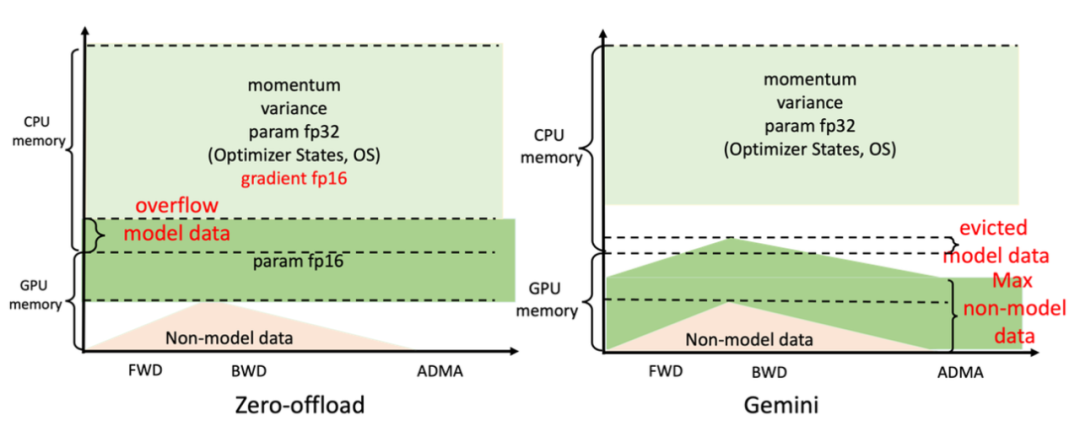
針對這些問題,Colossal-AI採用的解決思路是高效利用GPU+CPU的異構內存。
具體來看,是利用深度學習網絡訓練過程中不斷迭代的特性,按照迭代次數將整個訓練過程分為預熱和正式兩個階段。
預熱階段,監測採集到非模型數據內存信息;
正式階段,根據採集到的信息,預留出下一個算子在計算設備上所需的峯值內存,移動出一些GPU模型張量到CPU內存。
大概邏輯如下所示:

這裏稍微展開説明下,模型數據由參數、梯度和優化器狀態組成,它們的足跡和模型結構定義有關。
非模型數據由operator生成的中間張量組成,會根據訓練任務的配置(如批次大小)動態變化。
它倆常乾的事呢,就是搶GPU顯存。

所以,就需要在GPU顯存不夠時CPU能來幫忙,與此同時還要避免其他情況下內存浪費。
Colossal-AI高效利用GPU+CPU的異構內存,就是這樣的邏輯。
而以上過程中,獲取非模型數據的內存使用量其實非常難。
因為非模型數據的生存週期並不歸用户管理,現有的深度學習框架沒有暴露非模型數據的追蹤接口給用户。其次,CUDA context等非框架開銷也需要統計。
在這裏Colossal-AI的解決思路是,在預熱階段用採樣的方式,獲得非模型數據對CPU和GPU的內存的使用情況。
簡單來説,這是道加減法運算:
非數據模型使用 = 兩個統計時刻之間系統最大內存使用 — 模型數據內存使用
已知,模型數據內存使用可以通過查詢管理器得知。
具體來看就是下面醬嬸的:
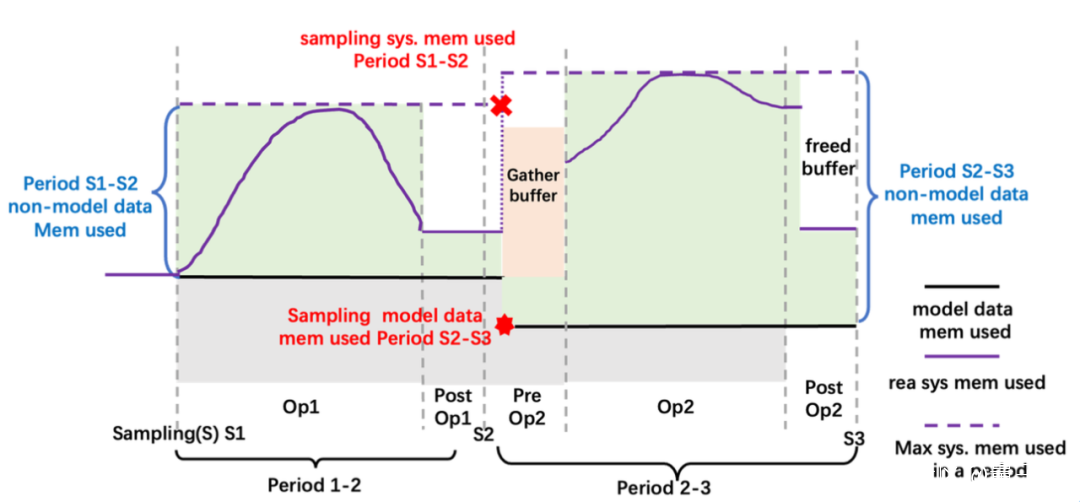
所有模型數據張量交給內存管理器管理,每個張量標記一個狀態信息,包括HOLD、COMPUTE、FREE等。
然後,根據動態查詢到的內存使用情況,不斷動態轉換張量狀態、調整張量位置,更高效利用GPU顯存和CPU內存。
在硬件非常有限的情況下,最大化模型容量和平衡訓練速度。這對於AI普及化、低成本微調大模型下游任務等,都具有深遠意義。
而且最最最關鍵的是——加內存條可比買高端顯卡劃 算 多 了。

前不久,Colossal-AI還成功復現了谷歌的最新研究成果PaLM (Pathways Language Model),表現同樣非常奈斯,而微軟DeepSpeed目前還不支持PaLM模型。
Colossal-AI還能做什麼?
前面也提到,Colossal-AI能挑戰的任務非常多,比如加速訓練、節省GPU資源。
那麼它是如何做到的呢?
簡單來説,Colossal-AI就是一個整合了多種並行方法的系統,提供的功能包括多維並行、大規模優化器、自適應任務調度、消除冗餘內存等。

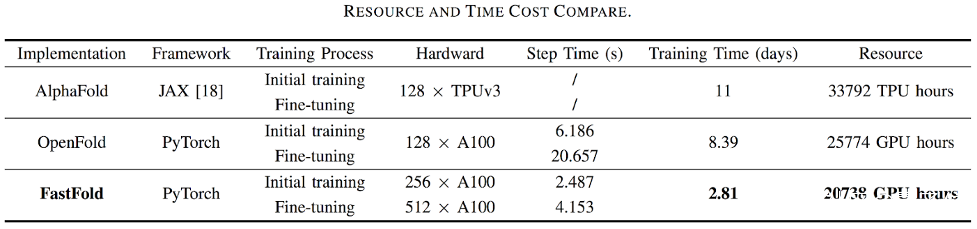
目前,基於Colossal-AI的加速方案FastFold,能夠將蛋白質結構預測模型AlphaFold的訓練時間,從原本的11天,減少到只需67小時。
而且總成本更低,在長序列推理任務中,也能實現9~11.6倍的速度提升。
這一方案成功超越谷歌和哥倫比亞大學的方法。
此外,Colossal-AI還能只用一半GPU數量訓練GPT-3。
相比英偉達方案,Colossal-AI僅需一半的計算資源,即可啓動訓練;若使用相同計算資源,則能提速11%,可降低GPT-3訓練成本超百萬美元。

與此同時,Colossal-AI也非常注重開源社區建設,提供中文教程、開放用户社羣論壇,根據大家的需求反饋不斷更新迭代。
比如之前有讀者留言説,Colossal-AI要是能在普通消費級顯卡上跑就好了。

這不,幾個月後,已經安排好了~
背後團隊:LAMB優化器作者尤洋領銜
看到這裏,是不是覺得Colossal-AI確實值得標星關注一發?
實際上,這一國產項目背後的研發團隊來頭不小。
領銜者,正是LAMB優化器的提出者尤洋。

他曾以第一名的成績保送清華計算機系碩士研究生,後赴加州大學伯克利分校攻讀CS博士學位。
拿過IPDPS/ICPP最佳論文、ACM/IEEE George Michael HPC Fellowship、福布斯30歲以下精英(亞洲 2021)、IEEE-CS超算傑出新人獎、UC伯克利EECS Lotfi A. Zadeh優秀畢業生獎。
在谷歌實習期間,憑藉LAMB方法,尤洋曾打破BERT預訓練世界紀錄。
據英偉達官方GitHub顯示,LAMB比Adam優化器快出整整72倍。微軟的DeepSpeed也採用了LAMB方法。
2021年,尤洋回國創辦潞晨科技——一家主營業務為分佈式軟件系統、大規模人工智能平台以及企業級雲計算解決方案的AI初創公司。
團隊的核心成員均來自美國加州大學伯克利分校、哈佛大學、斯坦福大學、芝加哥大學、清華大學、北京大學、新加坡國立大學、新加坡南洋理工大學等國內外知名高校;擁有Google Brain、IBM、Intel、 Microsoft、NVIDIA等知名廠商工作經歷。
公司成立即獲得創新工場、真格基金等多家頂尖VC機構種子輪投資。

潞晨CSO Prof. James Demmel為加州大學伯克利分校傑出教授、ACM/IEEE Fellow,同時還是美國科學院、工程院、藝術與科學院三院院士。
傳送門:https://github.com/hpcaitech/ColossalAI
參考鏈接:https://medium.com/@hpcaitech/train-18-billion-parameter-gpt-models-with-a-single-gpu-on-your-personal-computer-8793d08332dc