中國速度不磨嘰!硅谷大廠還在發論文,TikTok 產品已經上線了_風聞
大眼联盟-2022-08-16 20:21

中國速度感受一下。
— —
文|杜晨 編輯|VickyXiao 題圖來源:TikTok
突然間,AI 文字轉圖片成為了全球科技業的一大流行技術趨勢。
幾周前我們報道了“新一代梗圖之王” DALL·E mini,一個腦洞十分清奇的文字轉圖片 AI 小工具。當時我們也提到,包括谷歌、OpenAI 等大公司和頂級研究機構都在開發相關模型,就連時尚雜誌《COSMO》都採用 AI 來設計雜誌封面。

圖片來源:COSMO 雜誌
然而令許多人沒想到是:
就在各家硅谷大廠斥巨資研發、砸了無數的人力、發了無數的論文,卻還在測試相關技術的時候,TikTok 居然異軍突起,首先把 AI 文字轉圖片做到了產品裏,而且直接交到了全球十億用户的手上……
| 亂拳打死老師傅,中國速度太快了
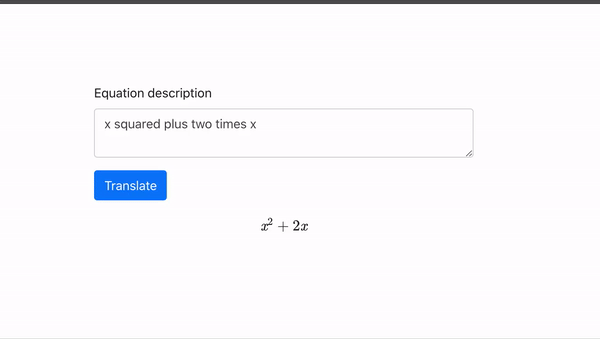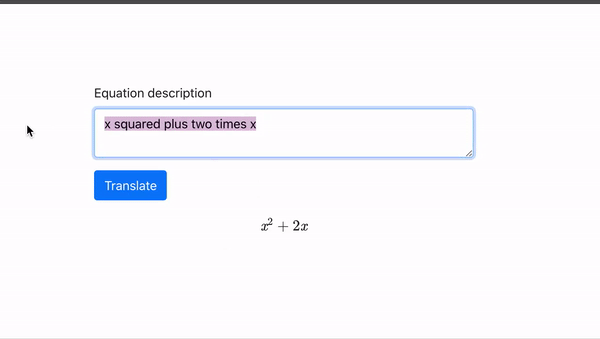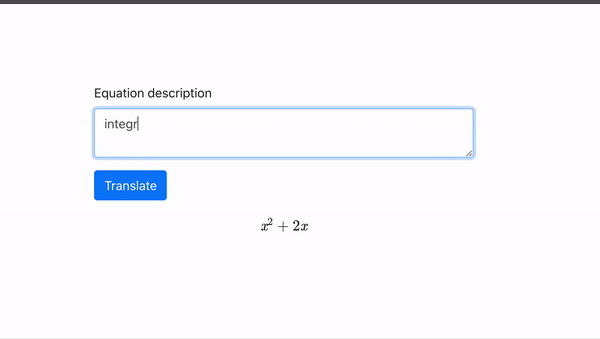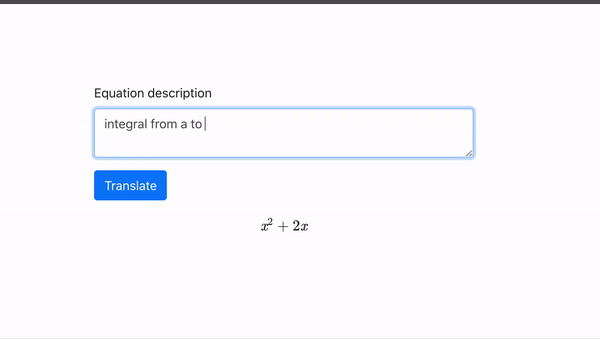
在 TikTok 的特效菜單下,最近增加了一個名叫“AI 綠幕” (AI Greenscreen) 的新選項。
點擊這個選項,然後在屏幕中間的對話框裏輸入一段文字描述,只用不到5秒的時間,TikTok 就可以根據文字描述生成一張豎版畫作,用作短視頻的背景:
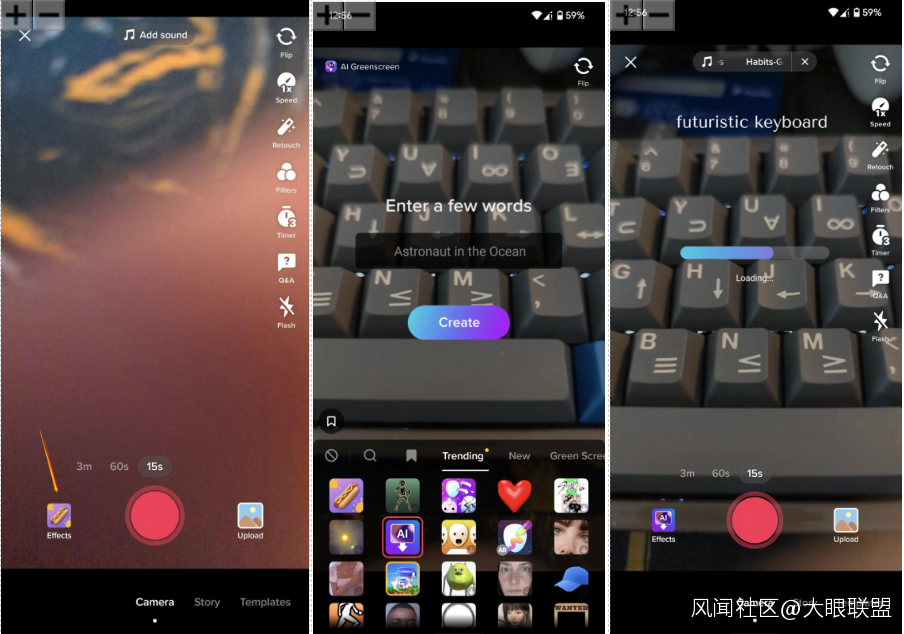
圖片來源:硅星人截圖
**TikTok 用的這個文字轉圖片模型,還是非常簡單的。**硅星人測試了幾個含義大相徑庭的提示,生成的圖片可以説都十分的“迷幻",沒有任何寫實色彩。
但這並不是缺點點——正相反,生成結果具有非常強的水彩/油畫感覺,風格遷移 (style transfer) 的痕跡明顯,而且用的顏色也都鮮亮明快,給人一種耳目一新的感受。
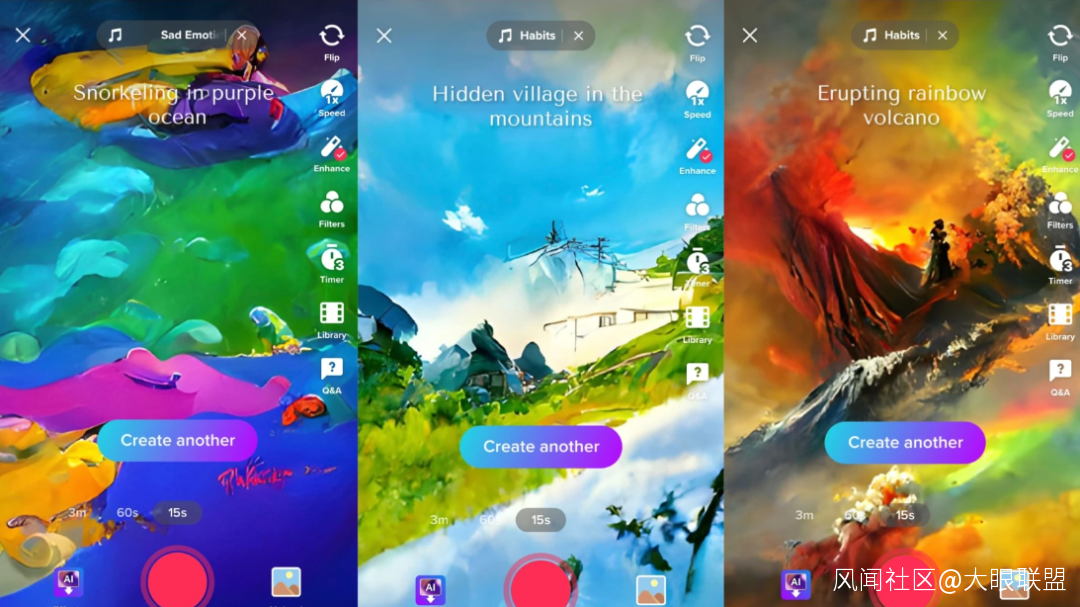
圖片來源:TechCrunch 截圖
我還想單獨説一下下面我自己生成的圖片:
下圖左邊的提示字段是知名遊戲“最後生還者”。生成結果的辨識度太高了,這不正是遊戲主角 Ellie 被泥漿血水浸濕的頭髮嗎?
右圖更有意思,提示是“轟炸”:我完全沒有想到如此“不和諧”的字段,TikTok 的模型居然生成的結果卻相當的“自洽”,特別是圖中的“轟炸機”反而看起來像是代表和平的“白鴿”——是否你也能讀出一點諷刺的意味?
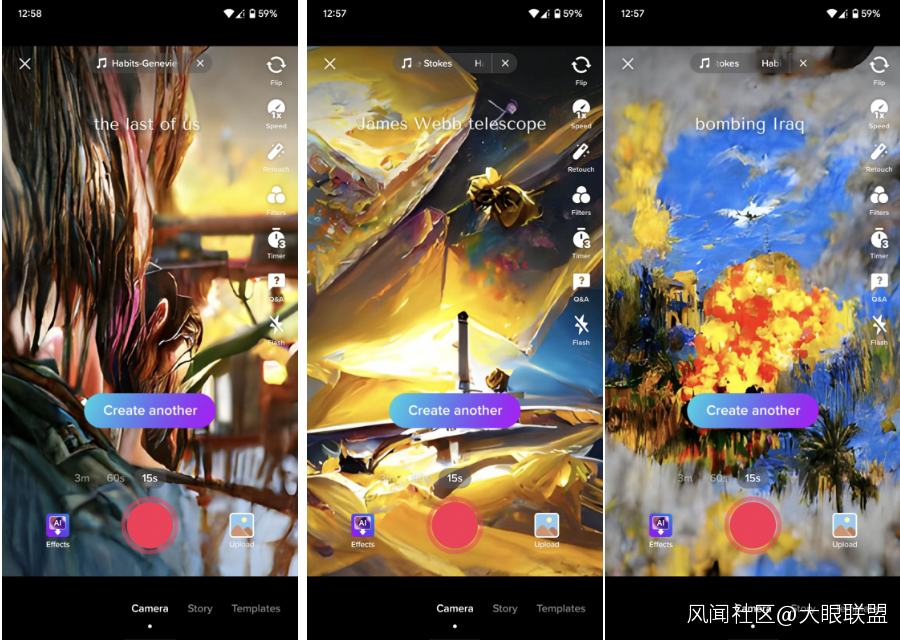
圖片來源:硅星人截圖
當然話説回來,這些只是我自己的解讀和感受,絕不可能是模型的“本意”。但是有趣的藝術作品不正應該是這樣嘛,讓人能夠發現一些巧妙的“彩蛋”,甚至浮想聯翩,解讀出另外的含義。
從這一角度,我還是非常認可 TikTok 目前部署的這個模型的。
模型的質量也值得一提。The Verge、TechCrunch 等美國媒體測試了一些特殊的敏感字段,AI 綠幕生成結果更加抽象了,顯示出字節部署的模型在爭議字段上可能已經做出了提前規避。
要知道 AI 文字生成圖片本來就不是簡單技術,避免爭議/道德風險更是一項相當複雜的工作。
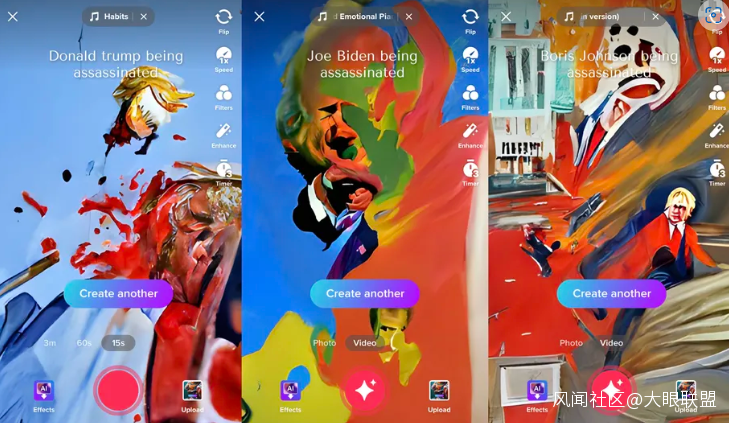
圖片來源:The Verge 截圖
正如文章前面提到,谷歌、OpenAI 等巨頭公司和知名機構開發的 AI 文字生成圖片模型,目前都處於剛剛發佈或者小範圍測試,還在“紙上談兵”的階段。
這邊 TikTok 不僅很快跟進推出了同類模型,更厲害的是已經將其投放到全球十億用户量級別的產品裏了。
**本來以為 AI 藝術創作的潮流還是幾個硅谷大廠在引領,沒想到字節跳動居然“亂拳打死老師傅”——**必須給中國互聯網科技公司的工作速度和質量點讚了。
| AI創作成潮流,硅谷大廠擠破頭
早在2020年,全球知名的人工智能基礎科研機構 OpenAI 發佈了一個名為 GPT-3 語言模型。當時 OpenAI 的論文題為“Language Models are Few-Shot Learners”,直接點出了超大規模語言模型在多種非訓練人物上具備強大、快速的學習和掌握能力。
GPT-3 也完全沒令人失望,在小範圍開放測試 API 之後,外界人士用它開發出了各種各樣神奇的 demo,展示了寫段子、翻譯公式、解數學題、完成用户界面設計、生成財務報表等能力。
“AI 文字生成圖片” 也是這些能力的其中一項。
圖片來源:硅星人
包括 OpenAI、谷歌、Midjourney、Stability AI 等一眾大小公司,已經開發出了多個文字轉圖片生成模型,展示出神經網絡模型具備令人驚訝的藝術創作能力。
從 AI 文字轉圖片生成技術開始得到公眾關注,到今天各路大廠和小公司擠破頭也要摻和,各種不開放的、開放的、收費和免費的模型層出不窮……也就過去了一年左右的時間。
在這些模型當中,OpenAI 的 DALL·E 是最著名的一款。該模型一代於2021年推出,今年剛剛更新到了二代。用户只需提供****自然語言描述,模型就能夠生成非常寫實 (photorealisitic) 的圖片。

圖片來源:OpenAI
除了從零開始生成全新照片,DALL·E 2 還有更多功能,適合現實中多種藝術工作場景。
比如它的編輯能力,可以在一張已經存在的照片中,在用户任選的位置“刪除”或者“添加”物體,並且編輯後的效果仍然很寫實:

圖示:在照片的不同位置添加“火烈鳥”。圖片來源:OpenAI
再比如 DALL·E 2 還具備“啓發”的能力,能夠根據一張已經給定的圖片,生成風格近相同的新照片:

圖片來源:OpenAI
順便一提:有個跟 OpenAI 沒關係的第三方開發者,自己仿着 DALL·E 做了一個圖片生成模型,還給免費開放了,取名為 DALL·E mini。
結果這個“仿製品”比正品還受歡迎,在社交網絡 Twitter 上專門搬運這個模型生成的奇怪圖片的賬號,粉絲量都破了百萬。甚至逼得 OpenAI 專門出來澄清跟它沒關係,要求開發者做出改變。現在這個免費小工具已經改名為 Craiyon 了。
(聽説此事之後,粉絲們還做了一張梗圖,嘲笑 OpenAI 那邊還在控制測試權限,這邊 DALL·E mini 早就給全網玩嗨了……)

圖片來源:FALSEKNEES
而在硅谷大廠的行列當中,現在谷歌是已知動作最快的,在 DALL·E 2 出來不久後也發佈了自己的模型,名為 Imagen。
就像 DALL·E 的根源是語言超大模型 GPT-3,Imagen 的根源也是谷歌開發的泛用型超大語言模型 T5。至於 Imagen 的這個命名,其實是圖片 (image) +生成 (generate) 的混成詞。
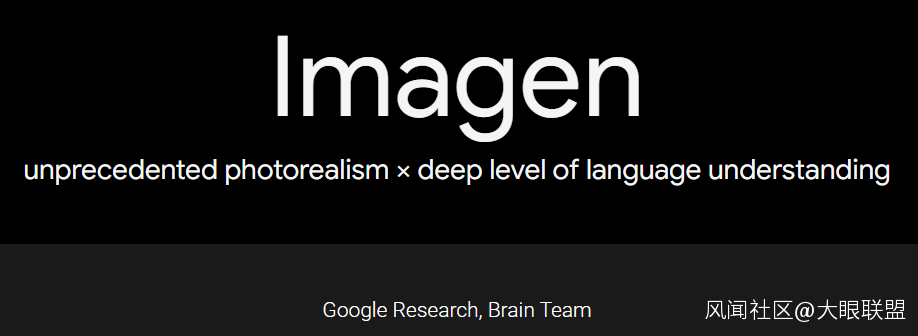

圖片來源:Google Research
雖然做的比 DALL·E 晚,同樣作為硅谷知名 AI 研究型公司的谷歌,還是非常不服 OpenAI 的,宣稱找人做了一堆同類模型的盲測,結果是受試者更喜歡 Imagen 生成的結果,認為其在“生成質量”和“文字描述還原度”上都更勝一籌。
——當然,究竟是 DALL·E 2 和 Imagen 誰的生成結果更好,還是一個很主觀的,見仁見智的事情。在技術實現上,這兩家其實大同小異,都是用了 Diffusion(擴散)模型生成,然後再用 Super-Resolution(超分辨率) 技術來讓生成結果更加清晰。
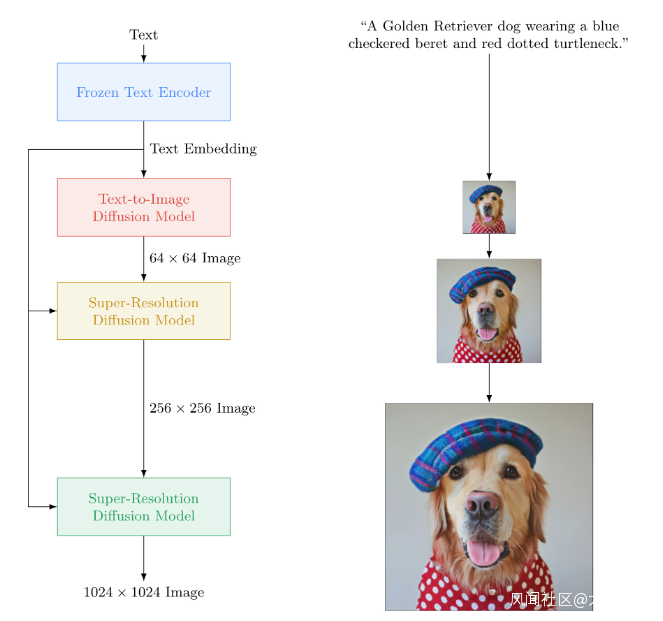
圖片來源:Google Research
還有更多規模更小的新創公司也在做 AI 圖片生成和藝術創作這件事。
**其中一家比較有意思的公司就是 Midjourney,**其創始人是原知名動作感應技術公司 Leap Motion 創始人 David Holz;公司的投資人和顧問團隊更是相當強大,都是蘋果、特斯拉、AMD、GitHub 等知名公司的核心人物。
Midjourney 跟 OpenAI、谷歌的寫實方向背道而馳,而是在抽象、藝術性、獨特風格之間尋求某種巧妙的結合點,這也是這家公司和其模型比較特別之處。另外 Midjourney 開放模型技術的做法也很“年輕化”,不是發佈 API 和文檔,而是把服務接口做到了聊天軟件 Discord 裏。

圖片來源:Midjourney
説完這些比較知名的公司,再來看一家名不見經傳,但是和 TikTok 一樣出手極快的美國公司:Stability AI。
這家公司總部位於硅谷 Los Altos,在上週剛剛發佈了一個可以免費使用的 AI 圖片生成產品 Stable Diffusion。

圖片來源:Stability AI
Stable Diffusion 和前面介紹的幾個寫實派模型沒有太大不同。但是和產品、公司名稱裏的“穩定”正相反,這個模型在有害/爭議字段的處理上,可以説完全沒有任何作為。而又因為產品是完全免費提供給公眾的,已經有很多用户用它製作 deepfake、暴力、恐怖主義、虛假新聞圖片等有害的內容了……
最近大半年,AI 圖片生成已經成為了一個名副其實的科技行業“熱詞”,只是沒想到,Open AI 和谷歌做了這麼多年,卻被 TikTok 給悄無聲息地跑贏了。接下來,應該會有更多的科技公司也參與其中,不少全民應用背後的大廠估計又要忙活着把這項技術加到產品中了。
硅星人