百度版權突圍之路,文學版權保護何時上岸?_風聞
文娱镜像-关注文娱发展趋势2022-08-23 15:00
內容生態是百度在AI之外的半邊天。
早在2017年,李彥宏新年內部演講定調百度未來的四大趨勢——內容分發、連接服務、金融創新、人工智能。在那個時候,百度已經意識到,從本質上來講最核心的東西還是內容的分發。
他説,“怎麼利用百度的平台讓內容回來、讓我們的用户能夠方便獲取,完成我們讓人們最便捷平等地獲取信息找到所求的使命?這是在新的時代裏我們需要認真思考認真準備並且為之奮鬥的東西。”
近幾年的百度,也持續在內容生態層面發力。
01
百度的內容生態防火牆
在音樂版權方面,百度一方面與全球範圍內近百家唱片公司達成了“所有歌曲鏈接都買單”的版權付費模式,來保障音樂著作權所有者的合法權益,其中包括滾石唱片、EMI等著名音樂公司。另一方面也與音著協宣佈達成合作,雙方共同建立音樂詞曲著作權合作渠道,根據試聽次數、下載次數對詞曲權利人進行付費。
在圖像版權方面,早在2018年,百度就基於區塊鏈技術打造了一個版權存證系統,該系統可以為內容作品提供具有明確時間標記的“存在性證明”;一站式在線維權系統還能夠發現侵權行為後進行在線取證並記錄至區塊鏈中。
而在影視作品方面,百度同樣完成了逆襲。 2021年,百度好看視頻發佈了關於保護原創、打擊侵權盜版行為取得的階段性進展,其中幾組數據令人關注:一年多,好看視頻專項小組共封禁賬號24545個;不到10個月,好看視頻處理維權問題8100起。
同樣在百度的內容生態中佔據重要地位的百度文庫,隨着知識分享經濟的興起,百度也上線了版權區塊鏈服務,提供從存證、監測到維權的全鏈路版權服務解決方案。通過“反盜版DNA系統”,日均處理文檔超百萬,查重精度達到99.99%。
至今,我們是否可以回答標題中的那個問題——百度是一家注重版權的企業嗎?似乎百度在音樂、文章、視頻、圖片上都已經有了動作維護內容生態。但是真的就解決了所有問題嗎?
02
盜版文學背後的產業鏈
從某些方面來看,是的,但不盡然。
至少文學作者對此無法認同。
中國版權協會發布的《2021年中國網絡文學版權保護與發展報告》顯示,盜版平台、搜索引擎和應用市場成為網絡文學侵權盜版的三座大山。作為中文互聯網最主要的搜索引擎,百度搜索的文學版權環境不容樂觀。文學作品的搜索結果首頁,充斥着密密麻麻的盜版鏈接。
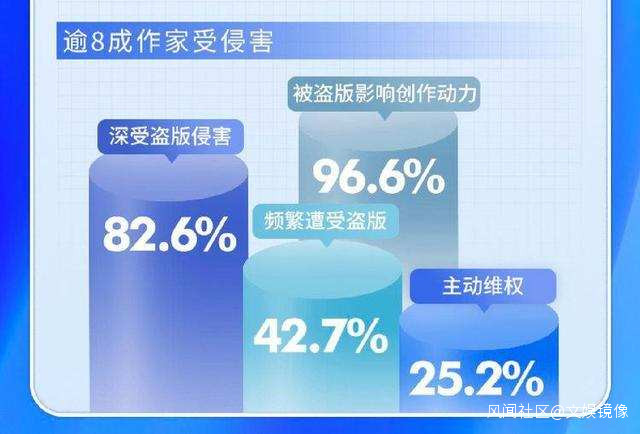
7月,百度發佈《打擊盜版網文站點公告》稱,為維護正版站點的排序權益,將在近期以技術手段對有盜版特徵(如筆趣閣)的小説、網文站點進行識別和處置,以給更多優秀站點展現空間,共建良性的網絡生態環境。但對於網文作者而言,這樣的打擊盜版,更像是“做了,但沒完全做”。
日前,“作家稱刪除自己被盜版鏈接需30年”的話題引發眾多媒體關注。一位作者王先生向媒體反映,自己用百度搜索名下的一部作品,發現僅PC端就有200多萬條侵權盜版鏈接。
面對誇張的盜版網站鏈接數量,王先生曾兩次向百度搜索發起投訴,在收到 “已處理”的反饋後,發現部分盜版鏈接仍然出現在搜索結果中,還出現了打掉一個鏈接,更多盜版鏈接“補位”的弔詭現象。面對200多萬條盜版鏈接,哪怕按照百度的上限要求每天投訴200條,王先生至少也要30年才能投訴完。
對百度而言,文學版權保護真的很難嗎?
從音樂、影視領域的治理經驗來看,搜索引擎完全有能力對網絡版權內容採取必要的過濾措施。即使退而求其次,也應當在收到權利人的維權投訴後履行“通知-刪除”義務。但百度在音樂、圖片、影視等領域的強勢手段,在文學領域毫無展現。反而因為大量盜版鏈接被優先顯示,且百度App的轉碼閲讀功能客觀上“美化”了盜版站點,不少讀者在很長一段時間內都不知道自己看的是盜版。
百度究竟是做不到,還是不想做?盜版視頻和文字大量存在,歸根結底是背後有利可圖。
查看中國裁判文書網,一份判決結果意味深長。百度搜索的主體公司“北京百度網訊科技有限公司”涉及1000多條著作權記錄。其中,《北京百度網訊科技有限公司與北京晉江原創網絡科技有限公司侵害作品信息網絡傳播權糾紛二審民事判決書(2020)京73民終1893號》顯示,百度不僅展示侵權鏈接,還與侵權方合作分成,從盜版傳播中獲得經濟利益。
而搜索引擎作為這條灰色產業鏈的源頭,漠視、不治理、放任,最終都會成為盜版文學灰產的温牀。
也許,時至今日百度仍然揣着明白裝糊塗,對盜版產業危害文學作者的影響視而不見。但至少要明白的是,版權維護並不是無關痛癢的“秀肌肉”,更應該精準落腳到當下的痛點本身。
最起碼,不要在無意中成為灰色產業的保護傘。